
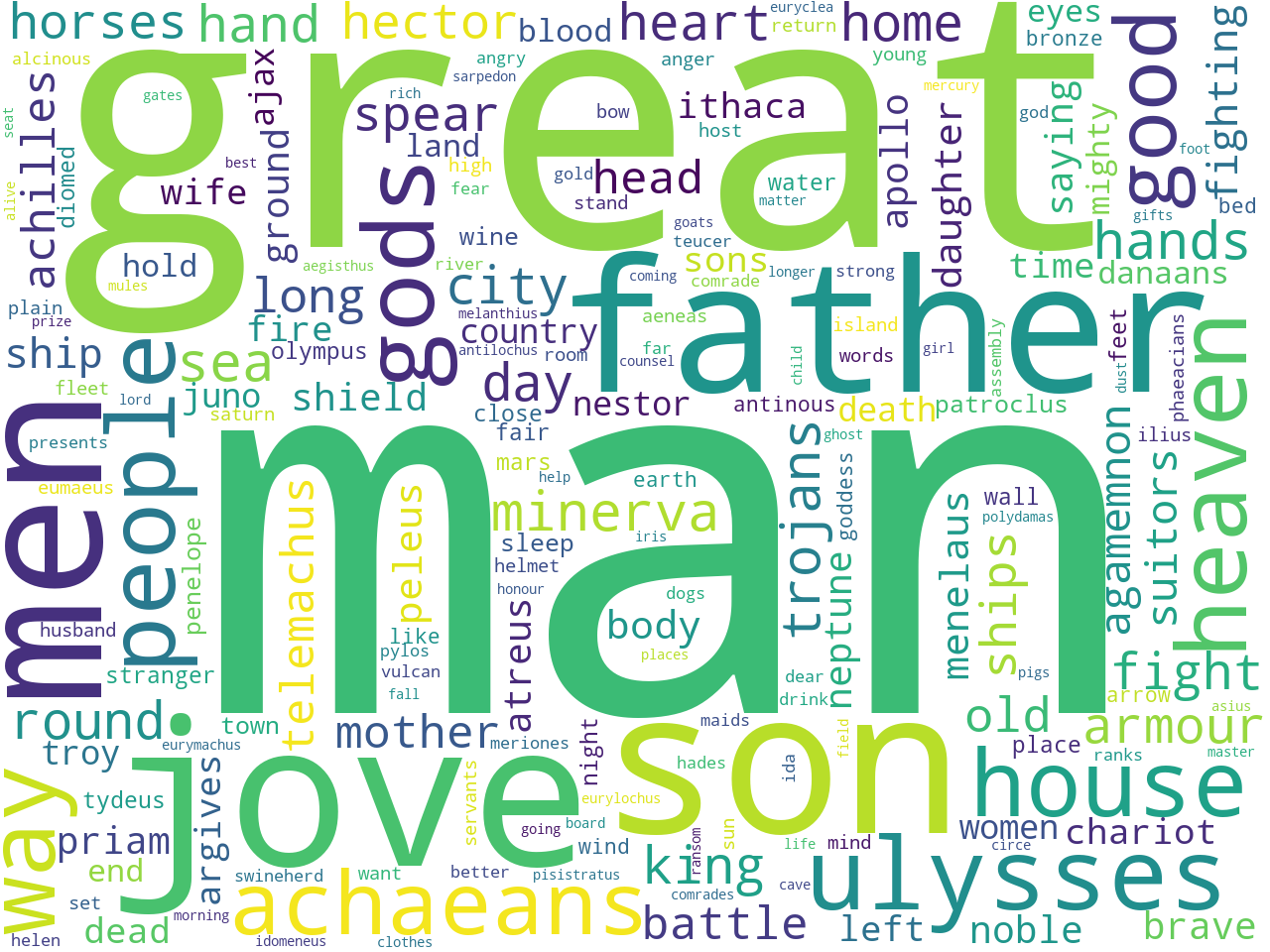
Given a corpus of narrative text, the Distant Reader creates data sets -- affectionately called "study carrels" -- for the purposes of use & understanding. By definition, data sets are designed to be computable, and this Web page is the result of one such computing process applied against the study carrel named homer. Here you will find a simple analysis of the carrel's extracted features. Use the features to characterize the content of the carrel, and use the features as a sort of back-of-the-book index as input for more in-depth use & understanding. For more information, please see the read me file describing study carrels in greater detail.
| Creator | eric |
| Date created | 2024-05-16 |
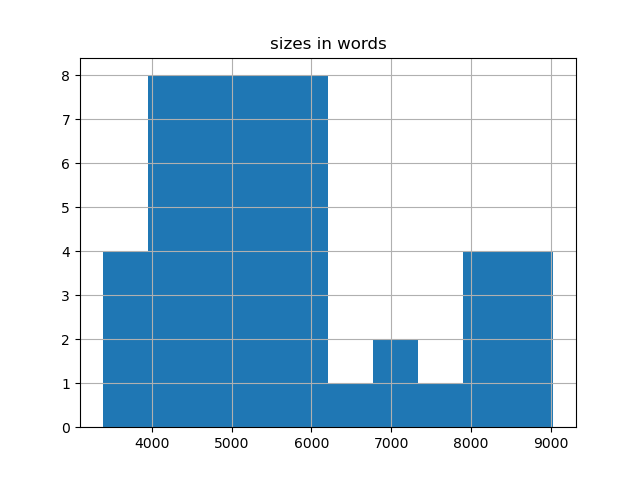
| Number of items | 48 |
| Number of words | 272735 |
| Average readability score | 76 |
| Bibliographics | plain text; HTML; JSON |
| Other files | stopwords; entire corpus |




 unigrams |
 bigrams |
 nouns |
 proper nouns |
 pronouns |
 verbs |
 adjectives |
 adverbs |
 any entity |
 persons |
 geo-political entities |
 organizations |
For more information, please see the read me file describing study carrels in greater detail.