classification-QA-gutenberg
Introduction
This is a Distant Reader "study carrel", a set of structured data intended to help the student, researcher, or scholar use & understand a corpus.
This study carrel was created on 2021-05-28 by Eric Morgan <emorgan@nd.edu>. The carrel was created using the Distant Reader gutenberg process, and the input was the result of a query applied to a local mirror of Project Gutenberg -- classification:"QA". Then, for future reference, the results were saved to a Zip file complete with rudimentary bibliographics. The name of the file is input-file.zip. The Zip file was then unpacked and the contents saved to a cache as well as a directory of plain text files. All of the analysis -- "reading" -- has been done against these plain text files. For example, a short narrative report has been created. This Web page is a more verbose version of that report.
All study carrels are self-contained -- no Internet connection is necessary to use them. Download this carrel for offline reading. The carrel is made up of many subdirectories and data files. The manifest describes each one in greater detail.
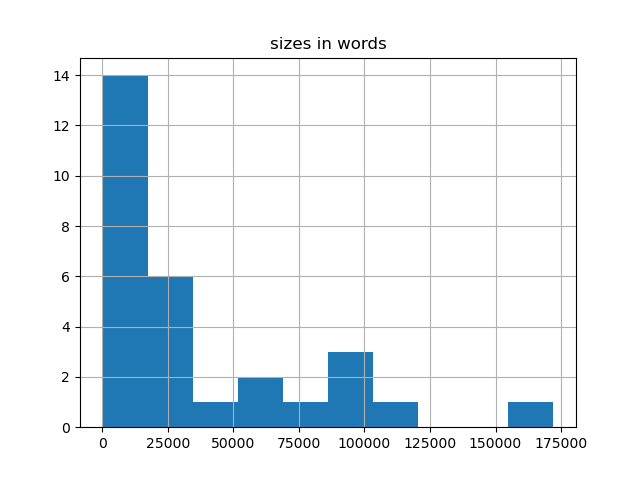
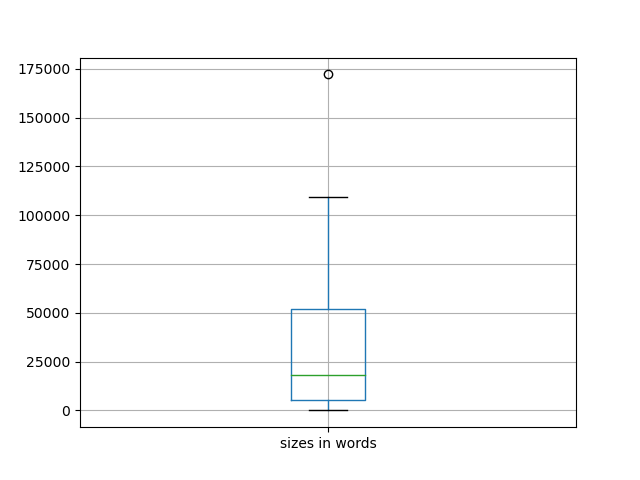
Size
There are 34 item(s) in this carrel, and this carrel is 1,025,207 words long. Each item in your study carrel is, on average, 35,351 words long. If you dig deeper, then you might want to save yourself some time by reading a shorter item. On the other hand, if your desire is for more detail, then you might consider reading a longer item. The following charts illustrate the overall size of the carrel.
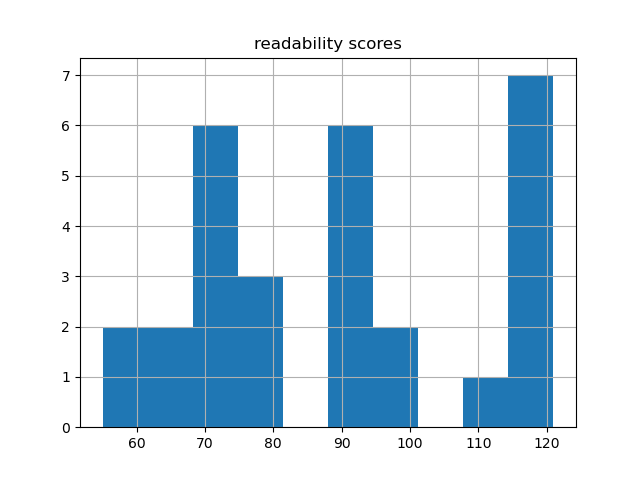
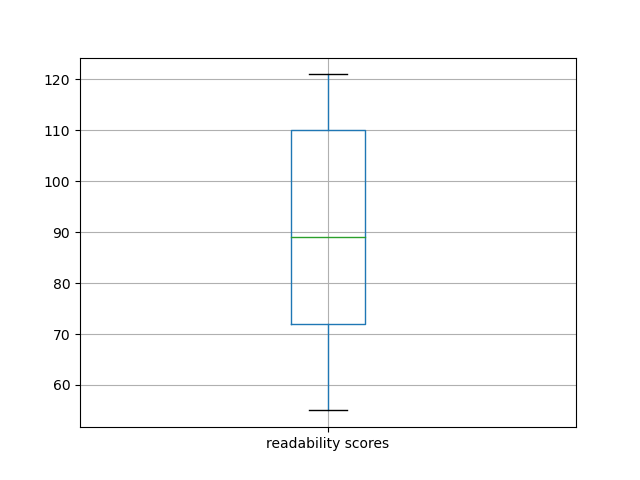
Readability
On a scale from 0 to 100, where 0 is very difficult and 100 is very easy, the documents have an average readability score of 89. Consequently, if you want to read something more simplistic, then consider a document with a higher score. If you want something more specialized, then consider something with a lower score. The following charts illustrate the overall readability of the carrel.
Word Frequencies
By merely counting & tabulating the frequency of individual words or phrases, you can begin to get an understanding of the carrel's "aboutness". Excluding "stop words", some of the more frequent words include:
one, will, two, may, number, first, time, three, now, must, many, digits, illustration, square, space, four, line, also, see, stallman, work, even, made, geometry, every, given, like, point, life, way, find, make, found, puzzle, form, man, numbers, well, another, case, much, new, little, use, de, great, certain, equal, just, right
Using the three most frequent words, the three files containing all of those words the most are Amusements in Mathematics, The Teaching of Geometry, and Jerome Cardan: A Biographical Study.
The most frequent two-word phrases (bigrams) include:
straight line, free software, different ways, de vita, vita propria, fourth dimension, one another, straight lines, ai lab, right angles, let us, euclidean geometry, square root, new york, stallman says, operating system, three dimensions, plane geometry, gnu project, will find, many different, years ago, four pieces, every one, solid geometry, open source, fewest possible, two sides, one side, see also, source code, three times, will give, old man, gian battista, correct answer, one hundred, will now, little puzzle, one day, will show, richard stallman, elementary geometry, will form, decimal point, elementary school, equilateral triangle, two squares, will make, two pieces
And the three file that use all of the three most frequent phrases are Free as in Freedom: Richard Stallman''s Crusade for Free Software The Teaching of Geometry, and Amusements in Mathematics.
While often deemed superficial or sophomoric, rudimentary frequencies and their associated "word clouds" can be quite insightful:
Keywords
Sets of keywords -- statistically significant words -- can be enumerated by comparing the relative frequency of words with the number of times the words appear in an entire corpus. Some of the most statistically significant keywords in the carrel include:
illustration, number, line, fig, vol, square, space, greek, geometry, circle, b.c., woman, university, sphere, spaceland, section, place, paris, numeral, mr., mit, isosceles, ibm, hacker, flatland, euclid, dimensions, digit, constant, colour, catalan, book, arithmetic, algebra, a.d., year, xerox, world, work, word, way, vita, varietate, unix, tx-0, tribe, torvalds, tmrc, time, thinker
And now word clouds really begin to shine:
Topic Modeling
Topic modeling is another popular approach to connoting the aboutness of a corpus. If the study carrel could be summed up in a single word, then that word might be number, and The Number Concept: Its Origin and Development is most about that word.
If the study carrel could be summed up in three words ("topics") then those words and their significantly associated titles include:
- 10 - The Mystery of Space A Study of the Hyperspace Movement in the Light of the Evolution of New Psychic Faculties and an Inquiry into the Genesis and Essential Nature of Space
- stallman - Free as in Freedom: Richard Stallman''s Crusade for Free Software
- geometry - The Golden Mean
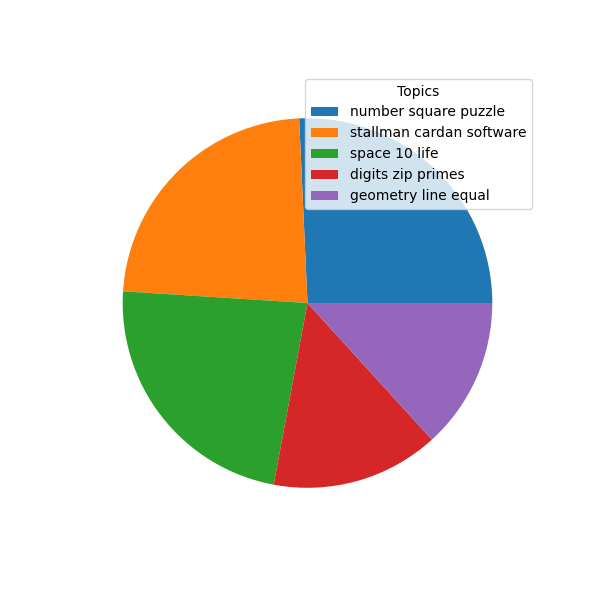
If the study carrel could be summed up in five topics, and each topic were each denoted with three words, then those topics and their most significantly associated files would be:
- number, square, puzzle - Amusements in Mathematics
- stallman, cardan, software - Jerome Cardan: A Biographical Study
- space, 10, life - The Mystery of Space A Study of the Hyperspace Movement in the Light of the Evolution of New Psychic Faculties and an Inquiry into the Genesis and Essential Nature of Space
- digits, zip, primes - The Fibonacci Number Series
- geometry, line, equal - The Teaching of Geometry
Moreover, the totality of the study carrel's aboutness, can be visualized with the following pie chart:
Noun & Verbs
Through an analysis of your study carrel's parts-of-speech, you are able to answer question beyonds aboutness. For example, a list of the most frequent nouns helps you answer what questions; "What is discussed in this collection?":
number, time, digits, illustration, p., space, line, way, life, work, man, geometry, numbers, case, point, square, words, years, fact, hand, mind, system, one, software, lines, puzzle, form, order, ways, times, part, world, plane, day, place, side, consciousness, men, problem, nature, knowledge, b, things, numerals, example, sides, solution, method, book, matter
An enumeration of the verbs helps you learn what actions take place in a text or what the things in the text do. Very frequently, the most common lemmatized verbs are "be", "have", and "do"; the more interesting verbs usually occur further down the list of frequencies:
is, be, are, was, have, had, has, been, were, do, see, made, given, being, find, make, found, said, used, did, say, give, does, know, says, take, get, shown, called, known, following, come, seen, use, let, put, having, show, set, go, taken, seems, ''s, done, cut, form, left, think, call, am
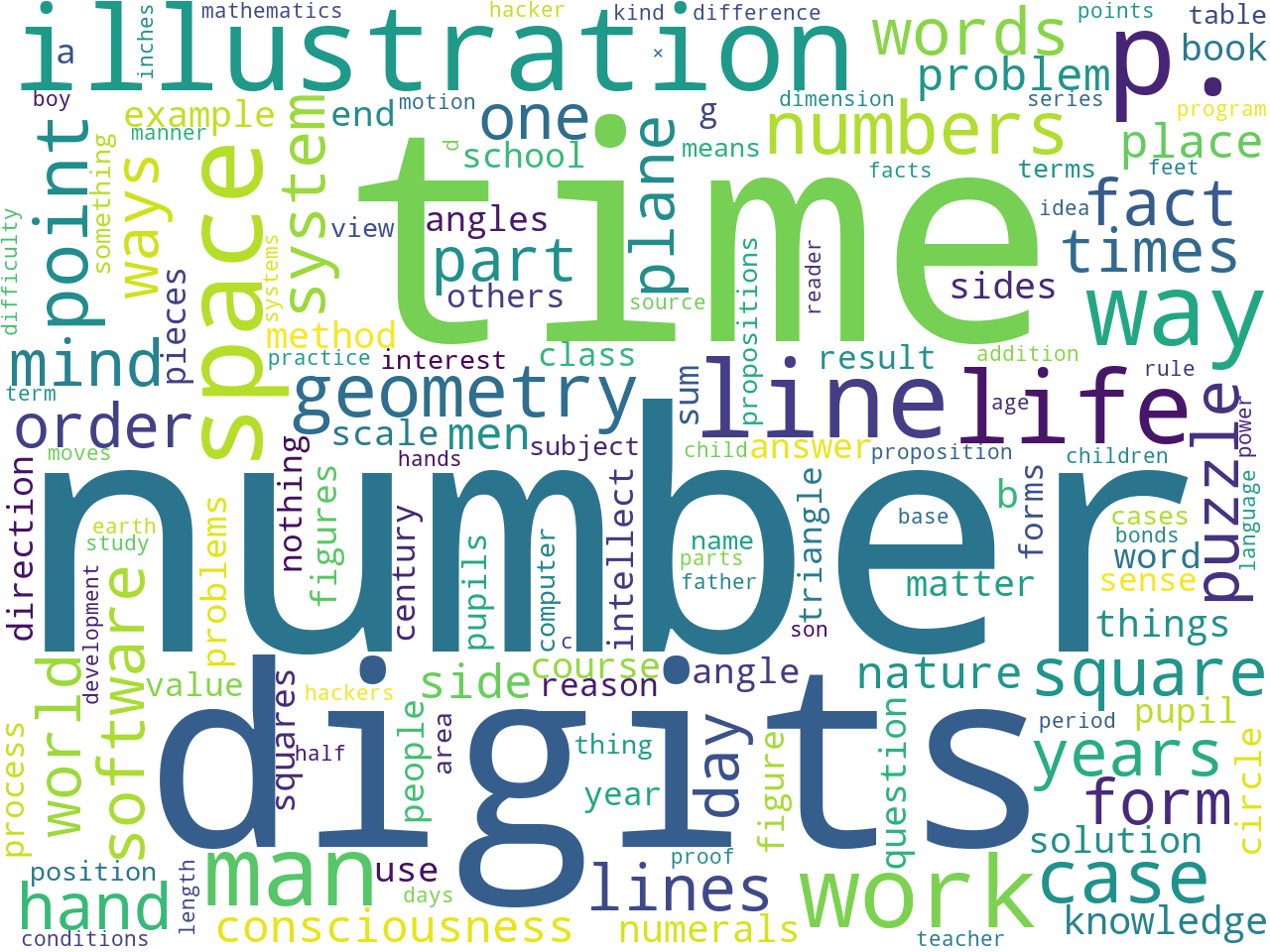

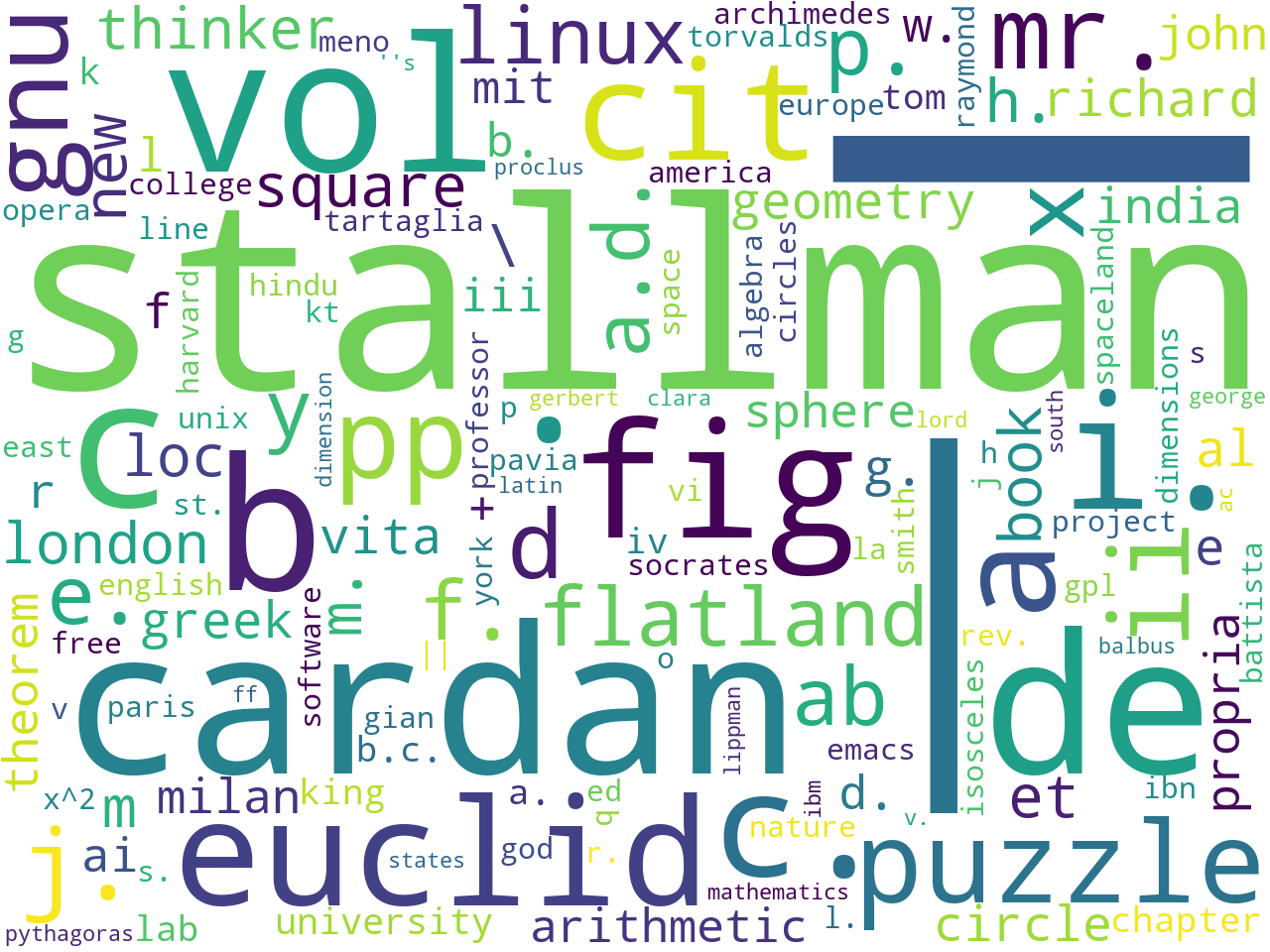
Proper Nouns
An extraction of proper nouns helps you determine the names of people and places in your study carrel.
_, |, stallman, cardan, de, vol, b, c, ., fig, i., euclid, c., cit, a, puzzle, pp, ii, gnu, mr., x, j., d, flatland, e., f., ab, y, p., linux, a.d., square, new, h., \, et, m., book, thinker, loc, london, m, geometry, richard, al, g., e, vita, greek, circle
An analysis of personal pronouns enables you to answer at least two questions: 1) "What, if any, is the overall gender of my study carrel?", and 2) "To what degree are the texts in my study carrel self-centered versus inclusive?"
it, i, he, his, we, you, they, their, its, my, them, him, our, me, your, her, us, itself, she, himself, themselves, one, myself, yourself, thy, ourselves, herself, mine, ours, ''s, y^2, oneself, theirs, thee, yours, n, hers, theseus, freebsd, a^2, |results, |kp[=e]el, ya, y, writes--"they, thyself, talkee, sè, r_{1, pp
Below are words cloud of your study carrel's proper & personal pronouns.

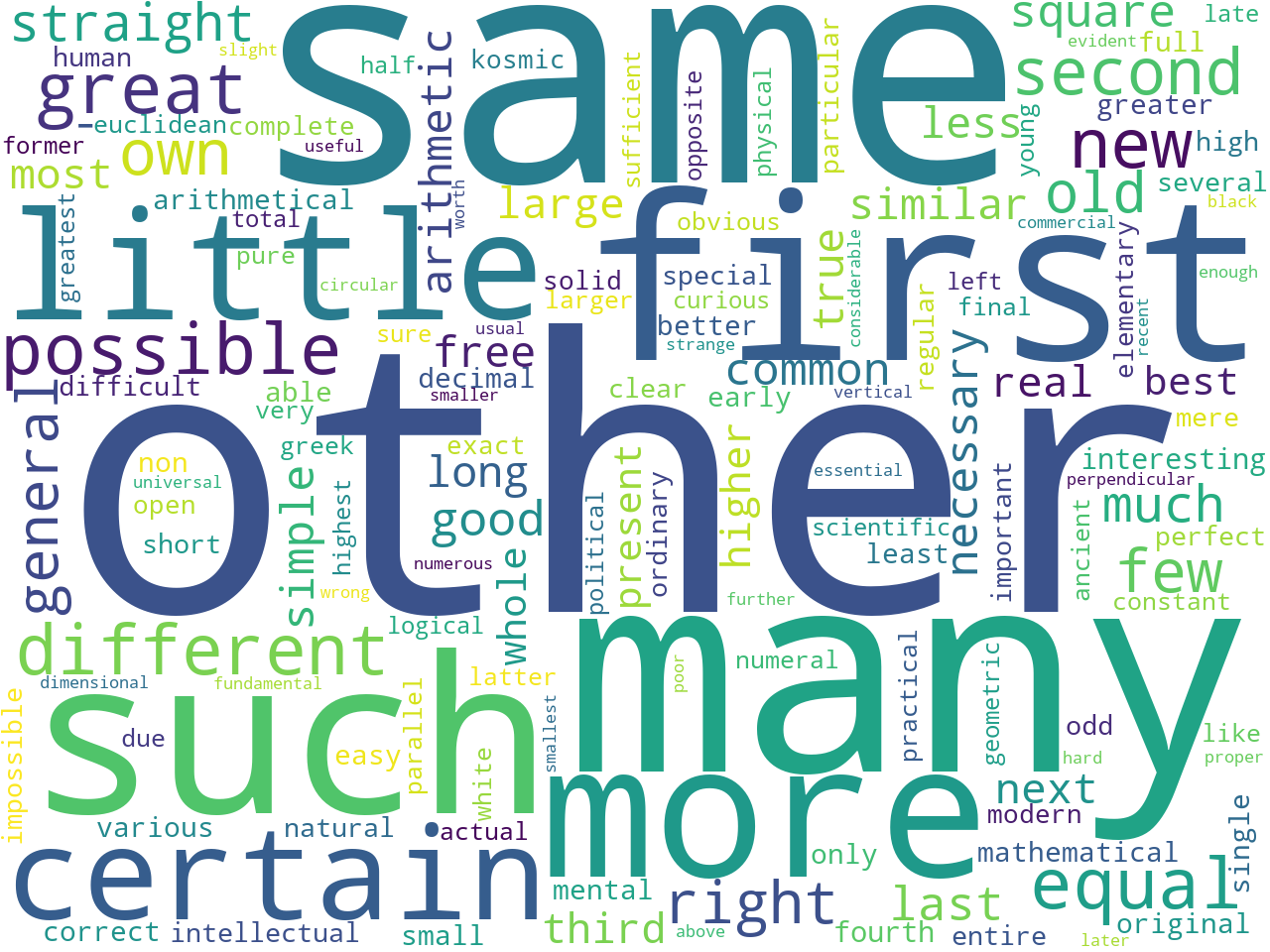
Adjectives & Verbs
Learning about a corpus's adjectives and adverbs helps you answer how questions: "How are things described and how are things done?" An analysis of adjectives and adverbs also points to a corpus's overall sentiment. "In general, is my study carrel positive or negative?"
other, same, many, first, such, more, little, certain, possible, equal, great, different, new, second, own, few, right, general, old, straight, much, good, last, square, necessary, common, simple, arithmetic, -, true, free, similar, long, less, real, next, large, most, third, higher, present, whole, best, interesting, fourth, small, greater, correct, single, full
not, so, then, only, now, more, as, also, even, up, out, very, thus, just, therefore, well, here, most, once, however, always, still, together, n''t, first, again, on, down, never, far, too, much, all, quite, exactly, indeed, back, rather, ever, long, really, already, there, almost, yet, off, probably, often, perhaps, in

Next steps
There is much more to a study carrel than the things outlined above. Use this page's menubar to navigate and explore in more detail. There you will find additional features & functions including: ngrams, parts-of-speech, grammars, named entities, topic modeling, a simple search interface, etc.
Again, study carrels are self-contained. Download this carrel for offline viewing and use.
Thank you for using the Distant Reader.