
This post continues where my last one left off, investigating broken links in our discovery layer. Be forewarned—most of it will be a long, dry list of all the mundane horrors of librarianship. Metadata mismatches, EZproxy errors, and OpenURL resolvers, oh my!
What does it mean when we say a link is broken? The simplest definition would be: when a link that claims to lead to full text does not. But the way that many discovery layers work is by translating article metadata into a query in a separate database, which leads to some gray areas. What if the link leads to a search with only a single result, the resource in question? What if the link leads to a search with two results, a dozen, a hundred…and the resource is among them? What if the link leads to a journal index and it takes some navigation to get to the article’s full text? Where do we draw the line?
The user’s expectation is that selecting something that says “full text” leads to the source itself. I think all of the above count as broken links, though they obviously range in severity. Some mean that the article simply cannot be accessed while others mean that the user has to perform a little more work. For the purposes of this study, I am primarily concerned with the first case: when the full text is nowhere near the link’s destination. As we discuss individual cases reported by end users, it will solidify our definition.
Long List
I’m going to enumerate some types of errors I’ve seen, providing a specific example and detailing its nature as much as possible to differentiate the errors from each other.
1. The user selects a full text link but is taken to a database query that doesn’t yield the desired result. We had someone report this with an article entitled “LAND USE: U.S. Soil Erosion Rates–Myth and Reality” in Summon which was translated into a query on the article’s ISSN, publication title, and an accidentally truncated title (just “LAND USE”).1 The query fails to retrieve the article but does show 137 other results. The article is present in the database and can be retrieved by editing the query, for instance by changing the title parameter to “U.S. soil erosion rates”. Indeed, the database has the title as “U.S. soil erosion rates–myth and reality”. The article appears to be part of a recurring column and is labelled “POLICY FORUM: LAND USE” which explains the discovery layer’s representation of the title.
Fundamentally, the problem is a disagreement about the title between the discovery layer and database. As another example, I’ve seen this problem occur with book reviews where one side prefixes the title with “Review:” while the other does not. In a third instance of this, I’ve seen a query title = "Julia Brannen Peter Moss "and" Ann Mooney Working "and" Caring over the Twentieth Century Palgrave Macmillan Basingstoke Hampshire 2004 234 pp hbk £50 ISBN 1 4039 2059 1" where a lot of ancillary text spilled into the title.
2. The user is looking for a specific piece except the destination database combines this piece with similar ones into a single record with a generic title such that incoming queries fail. So, for instance, our discovery layer’s link might become a title query for Book Review: Bad Feminist by Roxane Gay in the destination, which only has an article named “Book Reviews” in the same issue of the host publication. In my experience, this is one of the more common discovery layer problems and can be described as a granularity mismatch. The discovery layer and subscription database disagree about what the fundamental unit of the publication is. While book reviews often evince this problem, so too do letters to the editor, opinion pieces, and recurring columns.
3. An article present in one of our subscription databases is not represented in the discovery layer, despite the database being correctly selected in the knowledgebase that informs the discovery system’s index. We’re able to read the article “Kopfkino: Julia Phillips’ sculptures beyond the binary” in an EBSCO database that provides access to the journal Flash Art International but no query in Summon can retrieve it as a result. I suppose this is not technically a broken link as a non-existent link but it falls under the general umbrella of discovery layer content problems.
4. The exact inverse of the above: an article is correctly represented by the discovery layer index as being part of a database subscription that the user should have access to, but the article does not actually exist within the source database due to missing content. This occurred with an interview of Howard Willard in American Artist from 1950. While our subscription to Art & Architecture Source does indeed include the issue of American Artist in question, and one can read other articles from it, there was no record for the interview itself in EBSCOHost nor are its pages present in any of the PDF scans of the issue.
5. The user is looking for an article that is combined with another, even though the source seems to agree that they should be treated separately. For instance, one of our users was looking for the article “Musical Curiosities in Athanasius Kircher’s Antiquarian Visions” in the journal Music in Art but Summon’s link lands on a broken link resolver page in the destination EBSCO database. It turns out, upon closer inspection, that the pages for this article are appended to the PDF of the article that appears before it. All other articles for the issue have their own record. This is an interesting hybrid metadata/content problem similar to granularity mismatch: while there is no record for the article itself in the database, the article’s text is present. Yet unlike some granularity mismatches it is impossible to circumvent via search; you have to know to browse the issue and utilize page numbers to locate it.
6. The user selects a link to an article published within the past year in a journal with a year-long embargo. The discovery layer shows a “full text online” link but because the source’s link resolver doesn’t consider an embargoed article to be a valid destination, the link lands on an error page. This is an instance where Summon would, ideally, at least take to you to the article’s citation page but in any case the user won’t be able to retrieve the full text.
7. The user selects an article that is in a journal not contained within any of the library’s database subscriptions. This is usually simple knowledge base error where the journal lists for a database changed without being updated in the discovery layer index. Still, it’s quite common because not all subscription changes are published in a machine-readable manner that would allow discovery layers to automate their ingestion.
8. The user selects an article listed as being published in 2016 in the discovery layer, while the source database has 2017 so the OpenURL fails to resolve properly. Upon investigation, this date mismatch can be traced back to the journal’s publisher which lists the individual articles as being published in 2016 while the issue in which they are contained comes from 2017. The Summon support staff rightly points out to me that they can’t simply change the article dates to match one source; while it might fix some links, it will break others, and this date mismatch is a fundamentally unsolvable disagreement. This issue highlights the brittleness of real world metadata; publishers, content aggregators, and discovery products do not live in harmony.
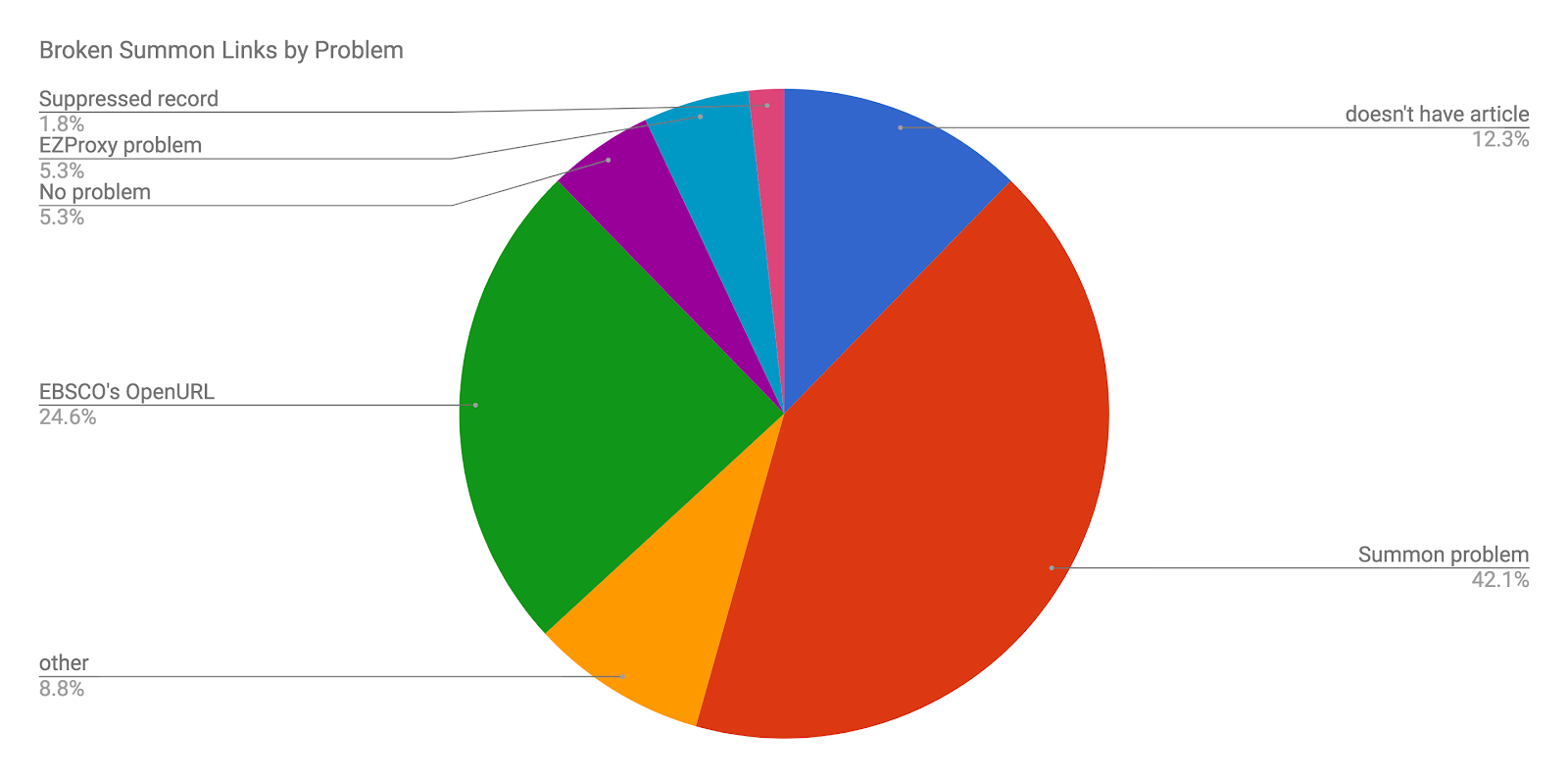
Reviewing the list of problems, this dual organization seems to helpfully group like issues:
- Metadata & linking problems
- Metadata mismatch (1, 5, 8)
- Granularity mismatch (2)
- Link resolver error (6)
- Index problems
- Article not in database/journal/index (3, 4, 5, 6)
- Journal not in database (7)
Of these three, the first category accounts for the vast majority of problems according to my anecdata. It’s notable that issues overlap and their classification is inexact. When a link to an embargoed article fails, should we say that is due to the article being “missing” or a link resolver issue? Whatever the case, it is often clear when a link is broken even if we could argue endlessly about how exactly.
There are also a host of problems that we, as librarians, cause. We might misconfigure EZproxy for a database or fail to keep our knowledge base holdings up to date. The difference with these problems is that they tend to happen once and then be resolved forever; I fix the EZproxy stanza, I remove access to the database we unsubscribed from. So the proportion of errors we account for is vanishingly low, while these other errors are eternal. No matter how many granularity mismatches or missing articles in I point out, there are always millions more waiting to cause problems for our users.
Notes
- This sort of incredibly poor handling of punctuation in queries is sadly quite common. Even though, in this instance, the source database and discovery layer are made by the same company the link between them still isn’t prepared to handle a colon in a text string. Consider how many academic articles have colons in their title. This is not good. ↩





{kind=link}