trump-tweets-wayback
Item Preview
trump-tweets-wayback.png



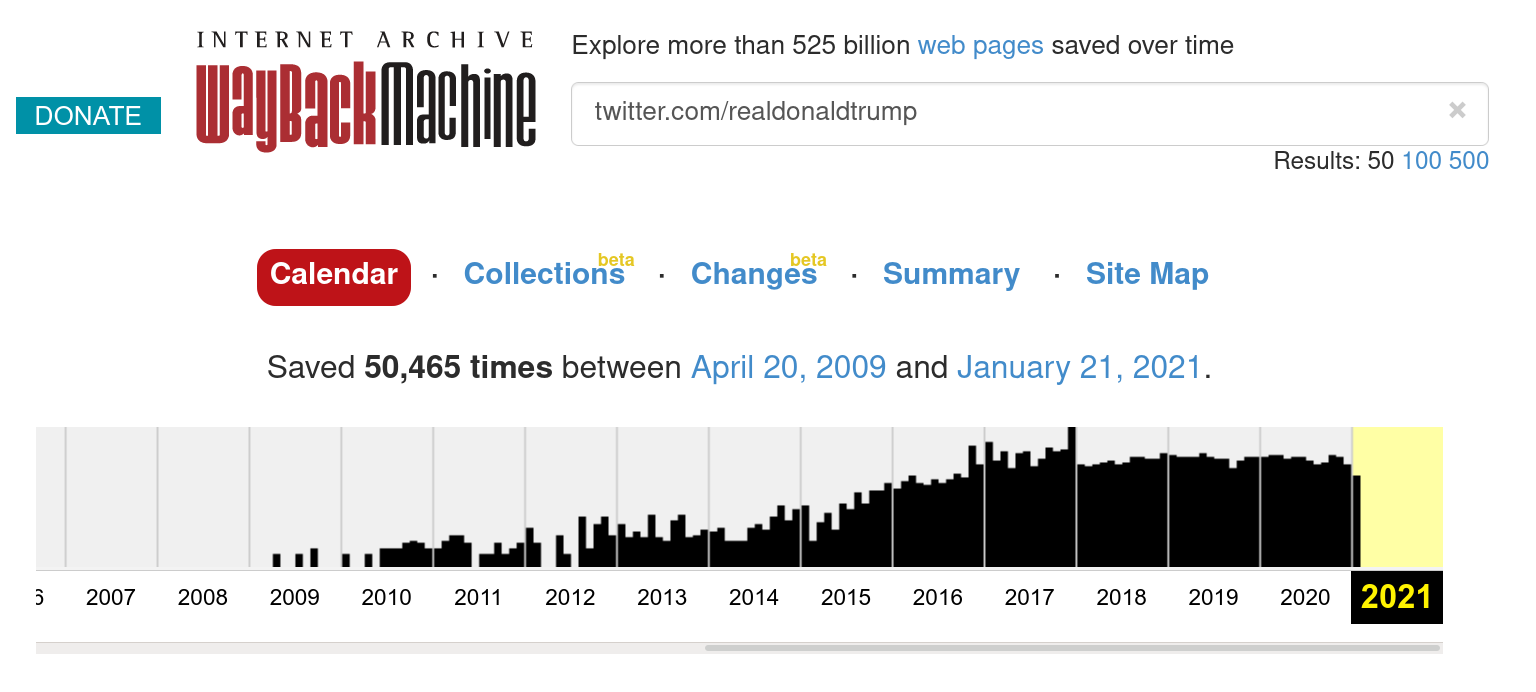
This contains a snapshot of data about Trump's tweets that are in the Internet Archive. It consists of a Jupyter Notebook that was used to query the Internet Archive's CDX API to see what snapshots are available for the URL prefix https://twitter.com/realDonaldTrump/status/{tweet-id}. The notebook serializes the results as a SQLite database that has information about 16 million snapshots that includes the URL, timestamp, size in bytes, HTTP status code, and HTTP media type. The sqlite database needs to be decompressed before the noteboo will work properly.
Reviews
There are no reviews yet. Be the first one to
write a review.

{kind=link}