No one is against "Investing in Infrastructure". No one wants bridges to collapse, investing is always more popular than spending, and it's even alliterative! What's more, since infrastructure is almost invisible by definition, it's politically safe to support investing in infrastructure because no one will see when you don't follow through on your commitment!
 |
| Ponte Morandi collapse - Michele Ferraris, CC BY-SA 4.0 via Wikimedia Commons |
Geoffrey Bilder gives a talk where he asks us to think of Crossref and similar services as "information infrastructure" akin to "plumbing", where the implication is that since we, as a society, are accustomed to paying plumbers and bridge builders lots of money, we should also pony up for "information infrastructure", which is obvious once you say it.
What qualifies as infrastructure, anyway? If I invest in a new laptop, is that infrastructure for the Go-to-Hellman blog? Blogspot is Google-owned blogging infrastructure for sure. It's certainly not open infrastructure, but it works, and I haven't had to do much maintenance on it.
There's a lot of infrastructure used to make Unglue.it, which supports distribution of open-access ebooks. It uses Django, which is open-source software originally developed to support newspaper websites. Unglue.it also uses modules that extend Django that were made possible by Django's Open license. It works really well, but I've had to put a fair amount of work into updating my code to keep up with new versions of Django. Ironically, most of this work has been in fixing the extensions that have not updated along with Django.
I deploy Unglue.it on AWS, which is DEFINITELY infrastructure. I have a love/hate relationship with AWS because it works so well, but every time I need to change something, I have to spend 2 hours with documentation to find the one-line incantation that make it work. But every few months, the cost of using AWS goes down, which I like, but the money goes to Amazon, which is ironic because they really don't care for the free ebooks we distribute.
Aside from AWS and Django, the infrastructure I use to deliver Ebook Foundation services includes Python, Docker, Travis-CI, GitHub, git, Ubuntu Linux, MySQL, Postgres, Ansible, Requests, Beautiful Soup, and many others. The Unglue.it database relies on infrastructure services from DOAB, OAPEN, LibraryThing, Project Gutenberg, OpenLibrary and Google Books. My development environment relies heavily on BBEdit and Jupyter. We depend on Crossref and Internet Archive to resolve some links; we use subject vocabulary from Library of Congress and BISAC.
You can imagine why I was interested in "JROST 2020" which turns out to stand for "Join Roadmap for Open Science Tools 2020", a meeting organized by a relatively new non-profit, "Invest in Open Infrastructure" (IOI). The meeting was open and free, and despite the challenges associated with such a meeting in our difficult times, it managed to present a provocative program along with a compelling vision.
If you think a bit about how to address the infrastructure needs of open science and open scholarship in general, you come up with at least 3 questions:
- How do you identify the "leaky pipes" that need fixing so as to avoid systemic collapse?
- How do you bolster healthy infrastructure so that it won't need repair?
- How do you build new infrastructure that will be valuable and thrive?
If it were up to me, my first steps would be to:
- Get people with a stake in open infrastructure to talk to each other. Break them out of their silos and figure out how their solutions can help solve problems in other communities.
- Create a 'venture fund" for new needed infrastructure. Work on solving the problems that no one wants to tackle on their own.
Invest in Open Infrastructure is already doing this! Kaitlin Thaney, who's been Executive Director of IOI for less that a year, seems to be pressing all the right buttons. The JROST 2020 meeting was a great start on #1 and #2 is the initial direction of the "JROST Rapid Response Fund", whose first round of awards was announced at the meeting.
Among the first awardees of the JROST Rapid Response Fund announced at JROST2020 was an organization that ties into the infrastructure that I use, 2i2c. It's a great example of much-needed infrastructure for scientific computing, education, digital humanities and data science. 2i2c aims to create hosted interactive computing environments that run in the cloud and are powered by entirely open-source technology (Jupyter). As I'm a Jupyter user and enthusiast, this makes me happy.
But while 2i2c is the awardee, it's being built on top of Jupyter. Is Jupyter also infrastructure? It needs investment too, doesn't it? There's a lot of overlap between the Jupyter team and the 2i2c team, so investment in one could be investment in the other. In fact, Chris Holdgraf, Executive Director of 2i2c, told me that "we see 2i2c as a way to both increase the impact of Jupyter in the research/education community, and a way to more sustainably drive resources back into the Jupyter community.".
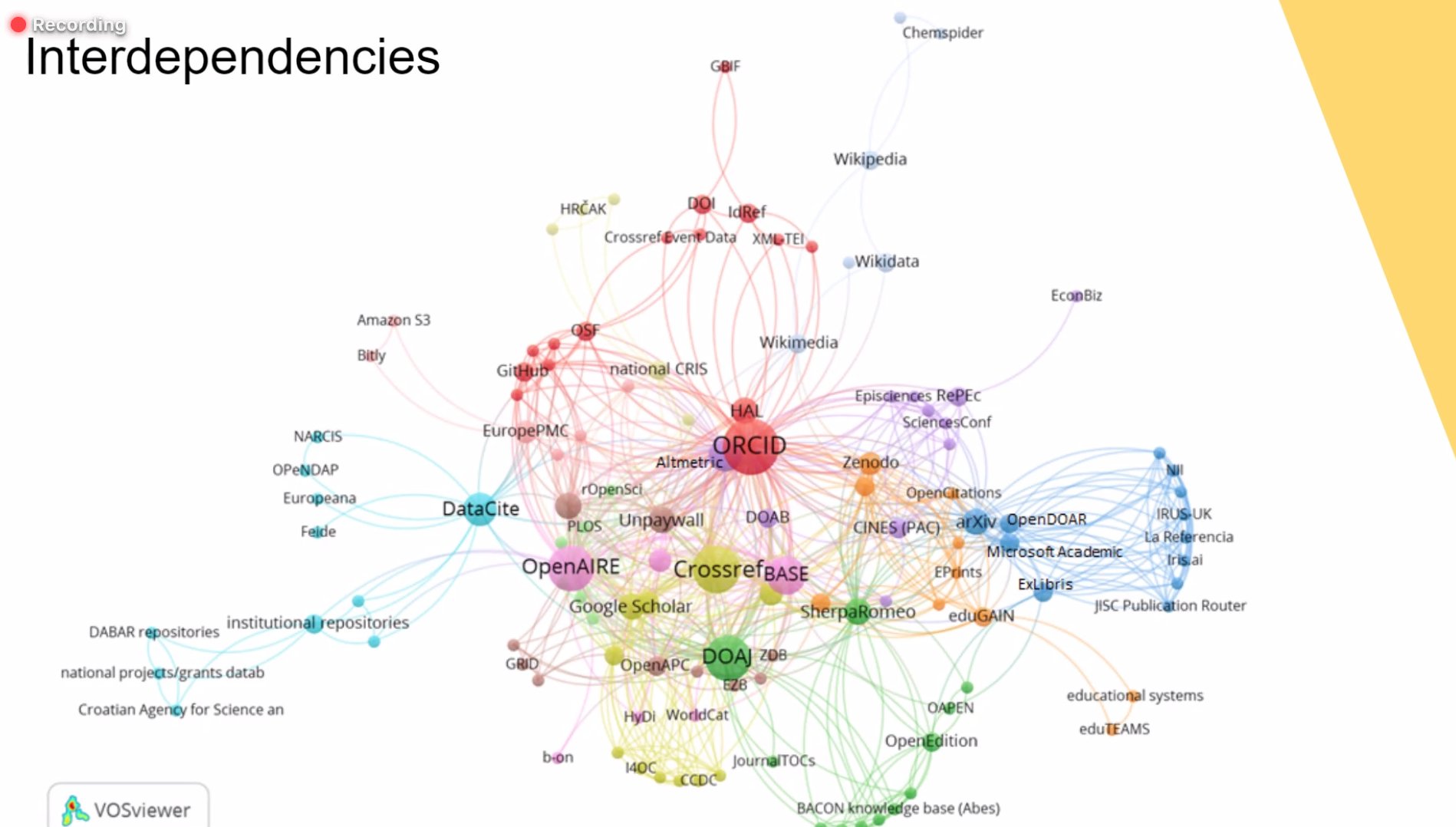 |
| Open Science Infrastructure Interdependency (from “Scoping the Open Science Infrastructure Landscape in Europe”, https://doi.org/10.5281/zenodo.4153809) |
Where does Jupyter fit in the infrastructure landscape? It's nowhere to be seen on the neat "interdependency map" presented by SPARC EU at JROST. If 2i2c is an example of investment-worthy infrastructure, maybe the best way to think of Jupyter is "infra-infrastructure" - the open information infrastructure needed to build open information infrastructure. "Trickle-down" investment in this sort of infrastructure may be the best way to support projects like Jupyter so they stay open and are widely used.
But wait... Jupyter is built on top of Python, right? Python needs people investing in it, Is Python infra-infra-infrastructure? And Python is built on top of C (I won't even mention Jython or PyJS), right?? Turtles all the way down. Will 2i2c eventually get buried under other layers of infrastructure, be forgotten and underinvested in, only to be one day excavated and studied by technology archeologists?
Looking carefully at the interdependency map, I don't see a lot of layers. I see a network with lots of loops. And many of the nodes are connectors themselves. Orcid and CrossRef resemble roads, bridges and plumbing not because they're hidden underneath, but because they're visible and in-between. They exist because of the entities they connect cooperate to make the connection robust instead of incidental. They're not infra-infrastructure, they're inter-infrastructure. Trickle-down investment probably wouldn't work for inter-infrastucture. Instead, investments need to come from the communities that benefit so that the communities can decide how to manage and access to the inter-infrastructure to maximize the community benefit.
There's another type of infrastructure that needs investment. I work in ebooks, and a lot of overlapping communities have tackled their own special ebook problems. But the textbook people don't talk to the public domain people don't talk to the monograph people don't talk to the library people. (A slight exaggeration.) There are lots of "almost" solutions that work well for specific tasks. But with the total amount of effort being expended, we could some really amazing things... if only we were better at collaborating.
For example, the Jupyter folks have gotten funding from Sloan for the "Executable Book Project". This is really cool. Similarly, there's Bookdown, which comes out of the R community. And there are other efforts to give ebooks the functionality that a website could have. Gitbook is a commercial open-source effort targeting a similar space, Rebus, a non-profit, is using Pressbooks to gain traction in the textbook space, while MIT Press's PubPub has similar goals.
I'll call these overlapping efforts "para-infrastructure." Should investors in open infrastructure target investment in "rolling up" or merging these efforts? When private equity investors have done this to library automation companies the results have not benefited the user communities, so I'd say "NO!" but what's the alternative?
I've observed that the folks who are doing the best job of just making stuff work rarely have the time or resources to go off to conferences or workshops. Typically, these folks have no incentive to do the work to make their tools work for slightly different problems. That can be time consuming! But it's still easier than taking someone else's work and modifying it to solve your own special problem. I think the best way to invest in open para-infrastructure is to get lots of these folks together and give the time and incentive to talk and to share solutions (and maybe code.) It's hard work, but making the web of open infrastructure stronger and more resilient is what investment in open infrastructure is all about.
Different types of open infrastructure benefit from different styles of investment; I'm hoping that IOI will build on the directions exhibited by its Rapid Response Fund and invest effectively in infra-infrastructure, inter-infrastructure, and para-infrastructure.
Notes
1. Geoff Bilder and Cameron Neylon have a nice discussion of many of the issues in this post: “Bilder G, Lin J, Neylon C (2016) Where are the pipes? Building Foundational Infrastructures for Future Services, retrieved [date], http://cameronneylon.net/blog/where-are-the-pipes-building-foundational-infrastructures-for-future-services/ ”
2. "Trickle-down" has a negative connotation in economics, but that's how you feed a tree, right?


_by_Matisse.jpg/640px-La_danse_(I)_by_Matisse.jpg)








{kind=link}
{kind=link}