
Abstract
General and adaptive strategies have been a highly pursued goal of the optimization community, due to the domain-dependent set of configurations (operators and parameters) that is usually required for achieving high quality solutions. This work investigates a Deep Q-Network (DQN) selection strategy under an online selection Hyper-Heuristic algorithm and compares it with two state-of-the-art Multi-Armed Bandit (MAB) approaches. We conducted the experiments on all six problem domains from the HyFlex Framework. With our definition of state representation and reward scheme, the DQN was able to quickly identify the good and bad operators, which resulted on better performance than the MAB strategies on the problem instances that a more exploitative behavior deemed advantageous.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others


1 Introduction
For many complex optimization problems, the use of heuristic approaches is often required to achieve feasible solutions in reasonable computational time [2]. One drawback of heuristics is that their performance heavily rely on the configuration setting, which must be tuned for the problem-domain at hand [2].
Because of that, the optimization community has investigated several adaptive search methodologies [2], initially only for parameter tunning, but then it expanded for automatically controlling the heuristic operators to be used. These strategies are normally termed in the literature as Hyper-Heuristics (HH) [3], in which the algorithm explore the search space of low-level heuristics. It can also be found as Adaptive Operator Selection (AOS) [7], usually when the selection occurs at a certain step within a meta-heuristic.
Moreover, with the advance and success of Machine Learning (ML) techniques, there has been an increasing interest in using novel ML for guiding the optimization search in several ways, including the selection of heuristic operators [9]. Due to the stochastic and iterative nature of optimization heuristics, Reinforcement Learning [17] techniques have been widely investigated for HH and AOS applications. However, most of them are traditionally simple additive reinforcement strategies, such as Probability Matching (PM) and Adaptive Pursuit (AP) [7], that use the received feedback to update a probability vector. Others are based on selection rules, that takes into account the feedback and the frequency of appliances in order to deal with the exploration versus exploitation dilemma (e.g., Choice Function and Multi Armed Bandit based strategies [7]).
Although those approaches presented good overall results, they lack a state representation according to the traditional RL definition [17], in which an agent learns a policy (directly or not) by interacting with an environment based on the observed state and the received feedback (reward or penalty). This work investigates a selection Hyper-Heuristic that uses a Deep Q-Network to choose the heuristics. The selection agent is updated while solving an instance using the Q-learning algorithm [19] with an Artificial Neural Network as function approximator [17]. In this way, we model the task of selecting the heuristics as a Markov Decision Process (MDP) [14], which implicates that the state representation must contain enough information for the agent to take an action.
Using a MDP-based strategy for this selection task has been shown to be advantageous over stateless strategies [18]. In fact, there are a few works that have successfully applied Q-Learning for HH and AOS. Handoko et al. [8] defined a discrete state space that relates to fitness improvement and diversity level. Then, the Q-learning updates the state-action values which are used to select the crossover operator of an evolutionary algorithm applied on the Quadratic Assignment Problem. The experimental results demonstrated that the approach is competitive with classical credit assignment mechanisms (AP, PM and MAB), while being less sensitive to the number of operators.
Similarly, Buzdalova et al. [4] applied Q-Learning to select crossover and mutation operators for the Traveling Salesman Problem. The state is defined by a 2-tuple containing the current generation and the fitness improvement of the current best individual over the initial best individual, both values discretized into 4 intervals. Their approach outperformed a random selection, indicating that the agent was able to learn a working policy while solving the instances. Mosadegh et al. [11] proposed a Simulated Annealing (SA) based HH that uses Q-Learning to select the moving operators. Each action consists on three operators, and the state is the number of times that the previous actions succeed (i.e., the operator generated an accepted solution under the SA conditions). The approach was significantly superior to other versions of SA and two software packages, with respect to both the quality of the solution and the computation time.
One limitation of these works is the use of a discrete state space, which may limit the representation of the search stage [18]. However, when defining a continuous state representation, the classical Q-Learning becomes infeasible due to the high dimensional Q-Table. Therefore, a function approximation model is necessary to estimate the state-action values [17]. The work from Teng et al. [18] defined a continuous state space that includes landscape measures about the current population and some parent-oriented features. Then, a Self-Organizing Neural Network is trained offline to select the crossover operator. The performance of this approach was competitive with other selection mechanisms (including a tabular Q-Learning) and even better on some instances, thus highlighting the advantages of using a continuous MDP-based selection strategy.
In Sharma et al. [15], the authors used a Double Deep Q-Network to select mutation operators of a Differential Evolution algorithm applied on several CEC2005 benchmark functions. The target network, which is trained offline during the training phase, receives as input 99 continuous features, where 19 are related to the current population and the reaming characterize the performance of each operator so far. This approach outperformed other non-adaptive algorithms and was competitive with state-of-the-art adaptive approaches.
In contrast with these works, we modeled a continuous state representation that consider only the past performance of the operators (within a certain memory), and the DQN is only trained online to learn a selection policy on each instance. We compare this approach with two state-of-the-art MAB based selection rules, namely the Dynamic MAB (DMAB) [5] and the Fitness-Rate-Rank MAB (FRRMAB) [10]. The MAB problem can be seen as a special case of Reinforcement Learning with only a single state [17].
We have present a preliminary work in a workshop paper [6], in which we report the results on two problem domains (the Vehicle Routing and the Traveling Salesman problems). Later, we found a flaw in our FRRMAB implementation. Here, we expand the results to all six problems from the Hyper-Heuristics Flexible framework (HyFlex) [12] and with all implementations revised. Moreover, we also present some analysis on the behavioral aspect of the selection mechanisms.
The remainder of this paper is organized as follows: Sect. 2 explains the concepts of HHs and describes the selection strategies that we compared: DMAB, FRRMAB and DQN. The experimental setup and results are given in Sect. 3. Finally, we draw some conclusions and indicate future works in Sect. 4.
2 Selection Hyper-Heuristic
According to Burke et al. [3], Hyper-Heuristics can be divided in two groups: selection HH, where it selects from a set of predefined low-level heuristics (llh); generative HHs, where the algorithm uses parts of llhs to construct new ones. Moreover, they can also be classified by its source of learning feedback: online, offline, and no-learning. This work is about an online learning selection HH.
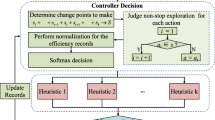
As a search methodology, selection HHs explore the search space of low-level heuristics (e.g., evolutionary operators) [3]. To avoid getting stuck into local optima solutions, good HHs must know which is the appropriate low-level heuristic to explore a different area of the search space at the time [3]. We used in this work a standard selection Hyper-Heuristic algorithm, as shown in Algorithm 1. Iteratively, it selects and applies a low-level heuristic on the current solution and computes the reward. Then, the acceptance criteria decides if the new solution is accepted and, at last, the HH calls the update method of the corresponding selection model.

The reward is defined as the FIR value (Eq. 2) and was kept the same for all selection strategies. Since our goal is to investigate the learning ability of the selection strategies, the acceptance criteria accepts all solutions. In this way, the actions of the agent always reflects a change in the environment.
The selection is made according to the employed selection strategy. In this work, we compared three strategies: Dynamic MAB, Fitness-Rate-Rank MAB, and Deep Q-Network.
2.1 Dynamic Multi-Armed Bandit
A MAB framework is composed of N arms (e.g., operators) and a selection rule for selecting an arm at each step. The goal is to maximize the cumulative reward gathered over time [16]. Among several algorithms to solve the MAB, the Upper Confidence Bound (UCB) [1] is one of the most known in the literature, as it provides asymptotic optimality guarantees. The UCB chooses the arm that maximizes the following rule
where \(n_{i,t}\) is the number of times the ith arm has been chosen, and \(p_{i,t}\) the average reward it has received up to time t. The scaling factor C gives a balance between selecting the best arm so far (\(p_{i,t}\), i.e., exploitation) and those that have not been selected for a while (second term in the Eq. 1, i.e., exploration).
However, the UCB algorithm was designed to work in static environments. This is not the case in the Hyper-Heuristic context, where the quality of the low-level heuristics can vary along the HH iterations [7]. Hence, the Dynamic MAB, proposed by [5], incorporates the Page-Hikley (PH) statistical test to deal with this issue. This mechanism resembles a context-drifting detection, but is related to the performance of the operators throughout the execution of the algorithm. Once a change in the reward distribution is detected, according to the PH test, the DMAB resets the empirical value estimates and the confidence intervals (p and n in Eq. 1, respectively) of the UCB [5].
2.2 Fitness-Rate-Rank Multi-Armed Bandit
The Fitness-Rate-Rank MAB [10] proposes the use of Fitness Improvement Rate (FIR) to measure the impact of the application of an operator i at time t, which is defined as
where \(p f_{i, t}\) is the fitness value of the original solution, and \(c f_{i,t}\) is the fitness value of the offspring.
Moreover, the FFRMAB uses a sliding window of size W to store the indexes of past operators, and their respective FIRs. This sliding window is organized as a First-in First-out (FIFO) structure and reflects the state of the search process. Then, the empirical reward \(Reward_{i}\) is computed as the sum of all FIR values for each operator i in the sliding window.
In order to give an appropriate credit value for an operator, the FRRMAB ranks all the computed \(Reward_{i}\) in descending order. Then, it assigns a decay value to them based on their rank value \(Rank_{i}\) and on a decaying factor \(D \in [0,1]\)
The D factor controls the influence for the best operator (the smaller the value, the larger influence). Finally, the Fitness-Rate-Rank (FRR) of an operator i is given by
These \(FRR_{i,t}\) values are set as the value estimate \(p_{i,t}\) in the UCB Eq. (1). Also, the \(n_{i,t}\) values considers only the amount of time that the operator appears in the current sliding window. This differs from the traditional MAB and other variants such as the DMAB, where the value estimate \(p_{i,t}\) is computed as the average of all rewards received so far.
2.3 Deep Q-Network
The classic Q-learning algorithm keeps a table that stores the Q-values (the estimate value of performing an action at current state) of all state-action pairs [19]. This table is then updated accordingly to the feedback the agent receives upon interacting with the environment. However, in a continuous state space, keeping the Q-table is not feasible due to the high dimensionality of the problem [17]. Instead, we can use a function approximation model (called the Q-model) that gives the estimate Q-values. In DQN, the Q-model is defined by an Artificial Neural Network (ANN), in which the inputs are the current observed state representation, and the output layer yields the predicted Q-values for the current state-action pairs. For this task, we used the MultiLayer Perceptron Regressor from the Scikit-learn library [13].
With these estimated Q-values, the agent selects the next action (low-level heuristic) according to its exploration policy. We used the \(\epsilon \)-greedy policy, that selects a random action with probability \(\epsilon \), and selects the action with the highest Q-value with probability \(1- \epsilon \). Thus, \(\epsilon \) is a parameter that controls the degree of exploration of the agent and is usually set to a small value [17].
After performing the action, receiving the reward and observing the next state, the Q-model is updated by running one iteration of gradient descent on the Artificial Neural Network, with the following target value
where \(s^{\prime }\) is the next state after performing the action, and \(\max _{a^{\prime }} Q\left( s^{\prime }, a^{\prime }\right) \) is the highest Q-value of all possible actions from state \(s^{\prime }\). The discount factor \(\gamma \) ([0, 1]) controls the influence of the future estimate rewards.
We defined the state representation as the normalized average rewards of each operator. For this, we used the same sliding window structure from FRRMAB. Hence, if we have 10 available low-level heuristics, for example, the state is represented as a vector of 10 values ranging [0,1], where each value is the average of the past W rewards (window size) of an operator. The idea is to investigate if the past observed rewards can be representative enough to allow the DQN to learn a proper selection policy.
3 Experiments
We conducted the experiments on all 6 problems from the HyFlex Framework [12]: One Dimensional Bin Packing (BP), Flow Shop (FS), Personal Scheduling (PS), Boolean Satisfiability (MAX-SAT), Traveling Salesman Problem (TSP), and Vehicle Routing Problem (VRP). The HyFlex provides 10 instances of each domain and 4 types of low-level heuristics: mutational, ruin-and-recreate, local search, and crossover. We included all operators but the crossover group into the selection pool. We refer to the documentation for more details [12].
We executed each selection strategy 31 times on every instance with different random seeds. We set the stopping criteria as 300 s of CPU running time on a Intel(R) Core(TM) i7-5930K CPU @ 3.50 GHz. The number of runs and stopping criteria were set following the Cross-Domain Heuristic Search ChallengeFootnote 1 competition rules, for which the HyFlex was originally developed. Table 1 displays the parameters setting that we used throughout the experiments.
Next we present the performance comparison of the selection strategies for each problem domain. For this, we compared the mean performance obtained by each approach on all instances using the Friedman hypothesis test and a pairwise post-hoc test with the Bergmann correction. The results of these tests are shown in the pipe graphs (e.g. Fig. 1), where the approaches are displayed according to their rank (the smaller the better), and the connected bold lines indicate the approaches that are statistically equivalent (\(p < 0.05\)).
Additionally, we also compared them on each instance individually with the Kruskal-Wallis hypothesis test, followed by a pairwise Dunn’s test, with the lowest ranked approach set as the control variable. The tables, such as Table 2, report the average and standard deviation of the best solution found by each selection strategy in the 31 runs. Bold values indicate that the corresponding approach achieved a better performance with statistical difference (\(p < 0.05\)), and gray background highlights all approaches that were statistically equivalent to the approach with the best rank on that instance.
Moreover, we also contrasted the approaches in terms of the selection behavior during the search. For this, we divided the search into 10 phases with equal number of iterations, and computed the average frequency that each operator was selected on that phase, resulting on the line graphs such as Fig. 2.
3.1 Bin Packing
On Bin Packing, both DQN and FRRMAB were statistically equivalent when considering all instances performance, as displayed in Fig. 1 where the DQN ranked better.

Friedman ranking with post-hoc tests on BP instances
In fact, if we observe the individual performance shown in Table 2, we can notice that their performance was dependent on the type of the instance, meaning that neither of them could generalize for all instances.
Figure 2 displays the average appliances of each operator for instance 0, that the DQN was worse than FRRMAB. We can observe that the DQN presents a exploitative behavior, giving high emphasis on the early prominent operators. The FRRMAB, on the other hand, was able to detect a change in operator performance.

Average selection of operators on BP instance 0

Average selection of operators on BP instance 7
However, this exploitative behavior was advantageous on some instances, such as instance 7 as shown in Fig. 3. The DQN detected at the initial phases the set of prominent operators, while the FRRMAB needed more time to do so.
3.2 Flow Shop
The DQN presented very poor performance on Flow Shop, where the FRRMAB and DMAB were both statistically better, as displayed in Fig. 4. Even when comparing the instances individually (Table 3), the DQN was not competitive in any instance.

Friedman ranking with post-hoc tests on FS instances
Figure 5 shows that, although the DQN kept selecting a few operators at around 10% of times, its exploitative behavior of giving high emphasis on the top two operators resulted on the poor performance on Flow Shop. Therefore, the reward scheme and/or the state representation that we defined were not satisfiable for domains in which more exploration is required to attain high quality solutions.
3.3 Personal Scheduling
The same thing happened in the PS domain, as shown in Fig. 6 and Table 4, where we can see that the MAB strategies were statistically superior to the DQN.
However, in this case we noticed that the DQN did present a more explorative behavior in comparison to the other domains, as displayed in Fig. 7. But even so, while the MAB strategies kept an operator being selected at maximum around 15% of the times, the DQN reached about 30% of preference for a single operator on some phases.

Average selection of operators on FS instance 0

Friedman ranking with post-hoc tests on PS instances

Average selection of operators on PS instance 0
3.4 MAX-SAT
The MAX-SAT is another domain in which giving high preference to few operators results in better solutions. Figure 8 and Table 5 shows that the DQN outperformed with a large marge the two MAB approaches.

Friedman ranking with post-hoc tests on MAX-SAT instances
Interestingly, on some instances such as the one displayed in Fig. 9, the three approaches identified the same set of operators as the best ones, meaning that the simple fitness-based reward scheme was able to give the selection strategy useful information in order to select the proper operators at each time. But again, the DQN selects with higher frequency the better heuristics and discard the others very quickly.
3.5 Traveling Salesman Problem
The TSP was another problem domain that the DQN outperformed the DMAB and FRRMAB, as shown in Fig. 10. When observing the individual instance performance (Table 6), the DQN was statistically better on 7 out of 10 instances and was at least equivalent on the others.
Figure 11 confirms that the same exploitative behavior, i.e., giving high preference for one to three heuristics, allows the DQN to attain high quality solution on some domains.

Average selection of operators on MAX-SAT instance 0

Friedman ranking with post-hoc tests on TSP instances

Average selection of operators on TSP instance 0
3.6 Vehicle Routing Problem
Finally, on VRP we observed a similar pattern of the Bin Packing domain: both DQN and FRRMAB were statistically equivalent on general (Fig. 12), but they outperformed one another on different type of instances (Table 7). The FRRMAB was better on the Solomon instances and the DQN outperformed the others on the Homberger instances.

Friedman ranking with post-hoc tests on VRP instances

Average selection of operators on VRP instance 5
Figure 13 shows the frequencies of operator selection on one Homberger instance. Such as in other VRP instances, we observed a pattern in which the DQN gave really high emphasis (more than 80%) for a single operator, which is a local search heuristic. This happens because only the fitness improvement is rewarded and, although the Q-Learning update rule (5) already implicitly deals with delayed rewards, it was not enough to give some credit for the exploration heuristics.
4 Conclusion
This work investigated the use of a heuristic selection strategy using Deep Q-Network. In comparison with the MAB-based strategies, the DQN selects its actions based on a state representation, which can give more insights about the current search stage.
We performed the experiments on six problem domains from the HyFlex framework and compared our approach with DMAB and FRRMAB strategies. We could observe that our approach can detect earlier the good and bad operators. However, it is slower to detect a change in performance of the heuristics. Therefore, for the domains and instances that there exists dominant operators, it outperformed the other selection approaches. On the other hand, it performed worse than both MABs when a wider diversity of operators was necessary.
Hence, further studies should be pursued to improve the exploration of DQN, so it can become more adaptive to different domains. This can be done either by improving the state representation, so it can give different information to the agent (such as stagnation, concept drift, etc.), or by investigating different reward schemes, so it can also rewards operators that do not necessarily improve the fitness function.
References
Auer, P., Cesa-Bianchi, N., Fischer, P.: Finite-time analysis of the multiarmed bandit problem. Mach. Learn. 47(2), 235–256 (2002)
Blum, C., Puchinger, J., Raidl, G.R., Roli, A.: Hybrid metaheuristics in combinatorial optimization: a survey. Appl. Soft Comput. 11(6), 4135–4151 (2011)
Burke, E.K., Hyde, M., Kendall, G., Ochoa, G., Özcan, E., Woodward, J.R.: A Classification of Hyper-heuristic Approaches, pp. 449–468. Springer, US, Boston, MA (2010). https://doi.org/10.1007/978-1-4419-1665-5_15
Buzdalova, A., Kononov, V., Buzdalov, M.: Selecting evolutionary operators using reinforcement learning: initial explorations. In: Proceedings of the Companion Publication of the 2014 Annual Conference on Genetic and Evolutionary Computation, pp. 1033–1036 (2014)
DaCosta, L., Fialho, A., Schoenauer, M., Sebag, M.: Adaptive operator selection with dynamic multi-armed bandits. In: Proceedings of the 10th Annual Conference on Genetic and Evolutionary Computation, pp. 913–920. GECCO ’08, Association for Computing Machinery, New York, NY, USA (2008)
Dantas, A., Rego, A.F.D., Pozo, A.: Using deep q-network for selection hyper-heuristics. In: Proceedings of the Genetic and Evolutionary Computation Conference Companion, pp. 1488–1492. GECCO ’21, Association for Computing Machinery, New York, NY, USA (2021)
Fialho, Á.: Adaptive Operator Selection for Optimization. Université Paris Sud - Paris XI (Dec, Theses (2010)
Handoko, S.D., Nguyen, D.T., Yuan, Z., Lau, H.C.: Reinforcement learning for adaptive operator selection in memetic search applied to quadratic assignment problem. In: Proceedings of the Companion Publication of the 2014 Annual Conference on Genetic and Evolutionary Computation, pp. 193–194. GECCO Comp ’14, Association for Computing Machinery, New York, NY, USA (2014)
Karimi-Mamaghan, M., Mohammadi, M., Meyer, P., Karimi-Mamaghan, A.M., Talbi, E.G.: Machine learning at the service of meta-heuristics for solving combinatorial optimization problems: A state-of-the-art. European Journal of Operational Research (2021)
Li, K., Fialho, Á., Kwong, S., Zhang, Q.: Adaptive operator selection with bandits for a multiobjective evolutionary algorithm based on decomposition. IEEE Trans. Evol. Comput. 18(1), 114–130 (2014)
Mosadegh, H., Ghomi, S.F., Süer, G.A.: Stochastic mixed-model assembly line sequencing problem: Mathematical modeling and q-learning based simulated annealing hyper-heuristics. Eur. J. Oper. Res. 282(2), 530–544 (2020)
Ochoa, G., et al.: HyFlex: A Benchmark Framework for Cross-domain Heuristic Search, vol. 7245, pp. 136–147 (2012)
Pedregosa, F., et al.: Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 12, 2825–2830 (2011)
Puterman, M.L.: Chapter 8 markov decision processes. In: Handbooks in Operations Research and Management Science, Stochastic Models, vol. 2, pp. 331–434. Elsevier (1990)
Sharma, M., Komninos, A., López-Ibáñez, M., Kazakov, D.: Deep reinforcement learning based parameter control in differential evolution. In: Proceedings of the Genetic and Evolutionary Computation Conference, pp. 709–717 (2019)
Soria-Alcaraz, J.A., Ochoa, G., Sotelo-Figeroa, M.A., Burke, E.K.: A methodology for determining an effective subset of heuristics in selection hyper-heuristics. Eur. J. Oper. Res. 260(3), 972–983 (2017)
Sutton, R.S., Barto, A.G.: Reinforcement Learning, Second Edition: An Introduction. MIT Press (2018)
Teng, T.-H., Handoko, S.D., Lau, H.C.: Self-organizing neural network for adaptive operator selection in evolutionary search. In: Festa, P., Sellmann, M., Vanschoren, J. (eds.) LION 2016. LNCS, vol. 10079, pp. 187–202. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-50349-3_13
Watkins, C.J.C.H., Dayan, P.: Q-learning. Mach. Learn. 8(3), 279–292 (1992)
Acknowledgements
This work was financially supported by Conselho Nacional de Desenvolvimento Científico e Tecnológico (CNPq) and by Coordenação de Aperfeiçoamento de Pessoal de Nível Superior (CAPES).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Dantas, A., Pozo, A. (2021). Online Selection of Heuristic Operators with Deep Q-Network: A Study on the HyFlex Framework. In: Britto, A., Valdivia Delgado, K. (eds) Intelligent Systems. BRACIS 2021. Lecture Notes in Computer Science(), vol 13073. Springer, Cham. https://doi.org/10.1007/978-3-030-91702-9_19
Download citation
DOI: https://doi.org/10.1007/978-3-030-91702-9_19
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-91701-2
Online ISBN: 978-3-030-91702-9
eBook Packages: Computer ScienceComputer Science (R0)