
Abstract
Several coarsening algorithms have been developed as a powerful strategy to deal with difficult machine learning problems represented by large-scale networks, including, network visualization, trajectory mining, community detection and dimension reduction. It iteratively reduces the original network into a hierarchy of gradually smaller informative representations. However, few of these algorithms have been specifically designed to deal with bipartite networks and they still face theoretical limitations that need to be explored. Specifically, a recently introduced algorithm, called MLPb, is based on a synchronous label propagation strategy. In spite of an interesting approach, it presents the following two problems: 1) A high-cost search strategy in dense networks and 2) the cyclic oscillation problem yielded by the synchronous propagation scheme. In this paper, we address these issues and propose a novel fast coarsening algorithm more suitable for large-scale bipartite networks. Our proposal introduces a semi-synchronous strategy via cross-propagation, which allows a time-effective implementation and deeply reduces the oscillation phenomenon. The empirical analysis in both synthetic networks and real-world networks shows that our coarsening strategy outperforms previous approaches regarding accuracy and runtime.
This work was carried out at the Center for Artificial Intelligence (C4AI-USP), with support by the São Paulo Research Foundation (FAPESP) under grant number: 2019/07665-4 and by the IBM Corporation. This work is also supported in part by FAPESP under grant numbers 2013/07375-0, 2015/50122-0 and 2019/14429-5, the Brazilian National Council for Scientific and Technological Development (CNPq) under grant number 303199/2019-9, and the Ministry of Science and Technology of China under grant number: G20200226015.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others


1 Introduction
Bipartite networks are a broadly pervasive class of networks, also known as two-layer networks, where the set of nodes is split into two disjoint subsets called “layers” and links can connect only nodes of different layers. These networks are widely used in science and technology to represent pairwise relationship between categories of entities, e.g. documents and terms, patient and gene expression (or clinical variables) or scientific papers and their authors [17, 19]. Over the last years, there has been a growing scientific interest in bipartite networks given their occurrence in many data analytic problems, such as community detection and text classification.
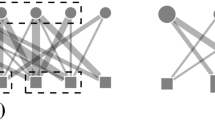
Several coarsening algorithms have been proposed as a scalable strategy to address hard machine learning problems in networks, including network visualization [29], trajectory mining [15], community detection [30] and dimensionality reduction [21]. These algorithms build a hierarchy of reduced networks from an initial problem instance, yielding multiple levels-of-detail, Fig. 1. It is commonly used for generating multiscale networks and, most notably, as a step of the well-known multilevel method.

Coarsening process. In (a), group of nodes are matched; in (b), the original network is coarsened, i.e., matched nodes are collapsed into a super-node and links incident in matched nodes are collapsed into super-edges; the coarsest network is illustrated in (c). The coarsening process is repeated, level by level, until the desired network size is reached.
However, only a few coarsening algorithms have been specifically designed to deal with bipartite networks, as showed in a recent survey [28], and they still face theoretical limitations that open for scientific investigation. Specifically, a recently introduced algorithm, proposed in [24], called MLPb, is based on a label propagation strategy that uses the diffusion of information to build a hierarchy of informative simplified representations of the original network. It implements a high time-cost strategy that searches the whole two-hop neighborhood of each node, which limits its use to sparse networks with a low link-density. As an additional limitation, MLPb uses a synchronous strategy which is known to yield a cyclic oscillation problem in some topological structures, as bipartite components.
To overcome these issues, we propose a novel fast coarsening algorithm based on the cross-propagation concept suitable for large-scale bipartite networks. Specifically, two-fold contribution:
-
We design a novel coarsening algorithm that uses a semi-synchronous strategy via cross-propagation, which only considers the direct neighbors of nodes, which implies a cost-efficient implementation and can deeply reduce the oscillation phenomenon.
-
We improve the classical cross-propagation strategy using the multilevel process by adding two restrictions: The first defines the minimum number of labels at the algorithm convergence and the second enforces size constraints to groups of nodes belonging to the same label. These restrictions increase the potential and adaptability of cross-propagation to foster novel applications in bipartite networks and can foster future research.
The empirical analysis, considering a set of thousands of networks (both synthetic and real-world networks), demonstrated that our coarsening strategy outperforms previous approaches regarding accuracy and runtime.
The remainder of the paper is organized as follows: First, we introduce the basic concepts and notations. Then, we present the proposed coarsening strategy. Finally, we report results and summarize our findings and discuss future work.
2 Background
A network \(\mathcal {G}=(\mathcal {V}, \mathcal {E}, \sigma , \omega )\) is bipartite (or two-layer) if its set of nodes \(\mathcal {V}\) and \(\mathcal {V}^1 \cap \mathcal {V}^2 = \emptyset \). \(\mathcal {E}\) is the set of links, wherein \(\mathcal {E}\subseteq \mathcal {V}^1 \times \mathcal {V}^2\). A link (u, v) may have an associated weight, denoted as \(\omega (u, v)\) with \(\omega : \mathcal {V}^1 \times \mathcal {V}^2 \rightarrow \mathbb {R}\); and a node u may have an associated weight, denoted as \(\sigma (u)\) with \(\sigma : V \rightarrow \mathbb {R}\). The degree of a node \(u \in \mathcal {V}\) is denoted by \(\kappa (u) = \sum _{v \in \mathcal {V}}w(u, v)\). The h-hop neighborhood of u, denoted by \(\varGamma _h(u)\), is formally defined as the nodes in set \(\varGamma _h(u) = \{v\ | \) there is a path of length h between u and \(v\}\). Thus, \(\varGamma _1(u)\) is the set of nodes adjacent to u; \(\varGamma _2(u)\) is the set of nodes 2-hops away from u, and so forth.
2.1 Label Propagation
The label propagation (LP) algorithm is a popular, simple and time-effective algorithm, commonly used in community detection [20]. Every node is initially assigned to a unique label, then, at each iteration, each node label is updated with the most frequent label in its neighborhood, following the rule:
wherein \(l_v\) is the current label of v, \(l_u^{'}\) is the new label of u, \(\mathcal {L}\) is the label set for all nodes and \(\delta \) is the Kronecker’s delta. Intuitively, groups of densely connected nodes will converge to a single dominant label.
LP has been widely studied, extended and enhanced. The authors in [1] proposed a modified algorithm that maximizes the network modularity. The authors in [11] presented a study of LP in bipartite networks. The authors in [12], improved in [2], introduced a novel algorithm that maximizes the modularity through LP in bipartite networks. The authors in [7] presented a variation of this concept to k-partite networks. In the multilevel context, the authors in [14] proposed a coarsening algorithm based on LP and, recently, the authors in [24] extended this concept to handle bipartite networks.
Synchronous LP formulation can yield cyclic oscillation of labels in some topological structures, as bipartite, nearly bipartite, ring, star-like components and other topological structures within them. Specifically, after an arbitrary step, labels values indefinitely oscillate between them, i.e. a node exchanges its label with a neighbor and, in a future iteration, this exchange is reversed. This problem is illustrated in Fig. 2.

Oscillation phenomenon. In (a), labels are randomly assigned to nodes; in (b), a propagation process updates the labels; in the subsequent iterations, labels values indefinitely oscillate between them.
To suppress this problem, it is used the asynchronous [20] or semi-synchronous [4] strategy, in which a node or a group of nodes is updated at a time, respectively. For bipartite networks are common to apply the cross-propagation concept, a semi-synchronous strategy [11], in which nodes in a selected layer are set as propagators and nodes in the other layer are set as receivers. The process is initially performed from the propagator to the receivers, then it is performed in the reverse direction, as illustrated in Fig. 3.

Cross-propagation in bipartite networks. In (a), labels are propagated from top layer to bottom layer; in (b), the process is performed in the reverse direction.
2.2 Coarsening in Bipartite Networks
A popular strategy to solve large-scale network problems (or data-intensive machine learning problems) is through a multiscale analysis of the original problem instance, which can involve a coarsening process that builds a sequence of networks at different levels of scale. Coarsening algorithms are commonly used as a step of the multilevel method, whose aim is to reduce the computational cost of a target algorithm (or a task) by applying it on the coarsest network. It operates in three phases [25]:
-
Coarsening phase: Original network \(\mathcal {G}_0\) is iteratively coarsened into hierarchy of smaller networks \(\{\mathcal {G}_1, \mathcal {G}_2, \cdots , \mathcal {G}_\mathcal {H}\}\), wherein \(G_\mathcal {H}\) is the coarsest network. The process implies in collapsing nodes and links into single entities, referred to as super-node and super-link, respectively.
-
Solution finding phase: The target algorithm or a task is applied or evaluated in the coarsest representation \(G_\mathcal {H}\).
-
Uncoarsening phase: The solution obtained in \(G_\mathcal {H}\) is projected back, through the intermediate levels \(\{G_{\mathcal {H}-1}, G_{\mathcal {H}-2}, \cdots , G_{1}\}\), until \(G_0\).
It is notable that the coarsening is the key component of the multilevel method, since it is problem-independent, in contrast to the other two phases that are designed according to the target task [25]. Therefore, many algorithms have been developed and, recently, some strategies able to handle bipartite networks have gained notoriety.
One of the first, proposed in [22, 23], called OPM\(_{hem}\) (one-mode projection-based matching algorithm), decomposes the bipartite structure into two unipartite networks, one for each layer. Although it increases the range of analysis options available (as classic and already established algorithms), this decomposition can lead to loss of information, reflecting in the performance of the algorithm.
Later, the authors in [27] introduced two coarsening algorithms, called RGMb (random greedy matching) and GMb (greedy matching), that uses directly the bipartite structure to select a pairwise set of nodes. They use the well-known and useful concept of a two-hop neighborhood. As a drawback, performing this search on large-scale bipartite networks with a high link-density can be computationally impractical.
Recently, the authors in [24] proposed a coarsening based on label propagation through the two-hop neighborhood. Despite its accuracy, it uses a standard and synchronous propagation strategy that can lead to instability and it does not guarantee the convergence.
The growing interest in coarsening algorithms for bipartite networks is recent and current strategies faces several theoretical limitations that remain mostly unexplored, consequently, open to scientific exploration. To overcome these issues, in the next section, we present a novel coarsening strategy.
3 Coarsening via Semi-synchronous Label Propagation for Bipartite Networks
We design a coarsening strategy via semi-synchronous label propagation for bipartite networks (CLPb). We use the cross-propagation concept to diffuse labels between layers. After the convergence, nodes in the same layer that belong to the same label will be collapsed into a single super-node.
3.1 Algorithm
A label is defined as a tuple \(\mathcal {L}_u(l, \beta )\), wherein l is the current label and \(\beta \in [0,1] \subset \mathbb {R}^+\) is its score. At first, each node \(u \in \mathcal {V}\) is initialized with a starting label \(\mathcal {L}_u=(u, \nicefrac {1.0}{\sqrt{\kappa (u)}})\), i.e. the initial \(\mathcal {L}_u\) is denoted by its id (or name) with a maximum score, i.e. \(\beta =1.0\). To reduce the influence of hub nodesFootnote 1, in all iteration, \(\beta \) must be normalized by its node degree, as follows:
Each step propagates a new label to a receiver node u selecting the label with maximum \(\beta \) from the union of its neighbors’ labels, i.e. \(\mathcal {L}_u = \cup \mathcal {L}_v\ \forall \ v \in \varGamma _1(u)\), according to the following filtering rules:
-
1.
Equal labels \(\mathcal {L}^{eq} \subseteq \mathcal {L}u\) are merged and the new \(\beta ^{'}\) is composed by the sum of its belonging scores:
$$\begin{aligned} \beta ^{'} = \sum _{(l, \beta ) \in \mathcal {L}^{eq}} \beta , \end{aligned}$$(3) -
2.
The belonging scores of the remaining labels are normalized, i.e.:
$$\begin{aligned} \mathcal {L}_u = \{(l_1, \frac{\beta _1}{\beta ^{sum}}), (l_2, \frac{\beta _2}{\beta ^{sum}}), \dots , (l_\gamma , \frac{\beta _\gamma }{\beta ^{sum}})\}, \end{aligned}$$(4)$$\begin{aligned} \beta ^{sum} = \sum _{i=1}^\gamma \beta _i, \end{aligned}$$(5)where \(\gamma \) is the number of remaining labels.
-
3.
The label with the largest \(\beta \) is selected:
$$\begin{aligned} \mathcal {L}_u^{'} = \mathop {{{\,\mathrm{arg\,max}\,}}}\limits _{{(l,\beta ) \in \mathcal {L}_u}} \mathcal {L}_u. \end{aligned}$$(6) -
4.
The size of the coarsest network is naturally controlled by the user, i.e. require defining a number of reduction levels, a reduction rate or any other parameter to fit a desired network size. Here, the minimum number of labels \(\eta \) for each layer is a user-defined parameter. A node \(u \in \mathcal {V}^i\), with \(i\in \{1,2\}\) define a layer, is only allowed to update its label if, and only if, the number of labels in the layer \(|\mathcal {L}^i|\) remains equal to or greater than \(\eta ^i\), i.e.:
$$\begin{aligned} |\mathcal {L}^i| \le \eta ^i. \end{aligned}$$(7) -
5.
At last, a classical issue in the multilevel context is that super-nodes tend to be highly unbalanced at each level [25]. Therefore, is common to constrain the size of the super-nodes from an upper-bound \(\mu \in [0, 1] \subset \mathbb {R}^+\), which limits the maximum size of a group of labels in each layer:
$$\begin{aligned} \mathcal {S}^i = \frac{1.0 + (\mu * (\eta ^i - 1)) * |\mathcal {V}^i|}{\eta ^i}, \end{aligned}$$(8)wherein \(\mu =1.0\) and \(\mu =0\) implies highly imbalanced and balanced groups of nodes, respectively. Therefore, a node u with weight \(\sigma (v)\) can update its current label l to a new label \(l^{'}\) if, and only if:
$$\begin{aligned} \sigma (u) + \sigma (l^{'}) \le S^i \quad \mathrm {and}\quad \sigma (l^{'}) = \sum _{v \in l^{'}} \sigma (v). \end{aligned}$$(9)
If restrictions 3 or 4 are not attained, the algorithm returns to step 3; the label with the maximum \(\beta \) is removed and a new ordered label is selected. The process is repeated until a label that satisfies the restrictions 3 and 4 is obtained. Figure 4 shows one step of CLPb in a bipartite network using the previously defined strategy. The propagation process is repeated \(\mathcal {T}\) (user-defined parameter) times until the convergence or stops when there are no label changes.

One step of the CLPb algorithm in a bipartite network. In (a), the process is performed from the top layer, considering the propagators nodes \(\in \mathcal {V}^1\), to the bottom layer, considering the receiver nodes \(\in \mathcal {V}^2\). At first, represented in (b), equal labels are merged. In (c), second step, remaining labels are normalized. In third step, the label B is selected, as showed in (d). In (e), the restriction 4 and 5 are tested. Finally, label B is propagated to the node in the bottom layer, as illustrated by the black dashed line.
After the cross-propagation convergence, the algorithm collapses each group of matched nodes (i.e. nodes with same label) into a single super-node. Links that are incident to matched nodes are collapsed into the so-called super-links. Figure 5 illustrates this process.
Note, the CLPb process does not guarantee that the desired minimum number of labels \(\eta \) will be reached at the current level, i.e. the algorithm can stop with a number of labels greater than the desired one. However, the multilevel process naturally mitigates this problem, since CLPb is performed, level by level, in the subsequent coarsened networks, until the desired number of nodes are reached. I.e., the original network \(\mathcal {G}_0\) is iteratively coarsened into a hierarchy of smaller networks \(\{\mathcal {G}_1, \mathcal {G}_2, \cdots , \mathcal {G}_\mathcal {H}, \cdots \}\), wherein \(\mathcal {G}_\mathcal {H}\) is an arbitrary level. Table 1 summarizes three levels automatically achieved by CLPb when evaluated in the UCForum [10].

Contraction process. In (a), group of nodes are matched using CLPb algorithm; in (b), the original network is coarsened, i.e., nodes that share labels are collapsed into a super-node and links incident to matched nodes are collapsed into super-edges.
Naturally, users can control the maximum number of levels and the reduction factor \(\rho \) for each layer, rather than input the desired number of nodes in the coarsest network. In this case, the desired number of nodes for each layer and in each level can be defined as exemplified in Eq. 10. Alternatively, users can stop the algorithm in an arbitrary level. However, this is a technical decision and the stop-criterion in Eq. 10 is commonly used in the literature [25].
3.2 Complexity
The computational complexity of the LP is near-linear regarding the number of links, i.e., \(\mathcal {O}(|\mathcal {V}|+|\mathcal {E}|)\) steps are needed at each iteration. If a constant number of \(\mathcal {T}\) iterations are considered, then \(\mathcal {O}(\mathcal {T}(|\mathcal {V}|+|\mathcal {E}|))\). The contraction process (illustrated in Fig. 5), first, iterates over all matched nodes \(\in \mathcal {V}_\mathcal {H}\) to create super-nodes \(\in \mathcal {V}_{\mathcal {H}+1}\), then, each link in \(\mathcal {E}_\mathcal {H}\) is selected to create super-links \(\in \mathcal {E}_{\mathcal {H}+1}\), therefore, \(\mathcal {O}(|\mathcal {V}|+|\mathcal {E}|)\). These complexities are well-known in the literature, and the expanded discussion can be found in [25] and [20]. Based on these considerations, the CLPb complexity is \(\mathcal {O}(\mathcal {T}(|\mathcal {V}|+|\mathcal {E}|))\) + \(\mathcal {O}(|\mathcal {V}|+|\mathcal {E}|)\) at each level.
4 Experiments
We compared the performance of CLPb with four state-of-the-art coarsening algorithms, namely MLPb, OPM\(_{hem}\), RGMb and GMb (discussed in Sect. 2 and presented in the survey [28]). First, we conducted an experiment in a set of thousands of synthetic networks and, then, we test the performance of the algorithms in a set of well-known real networks.
A common and practical approach to verify the quality of a coarsened representation is mapping each super-node as a group (community or cluster) and evaluate them using quality measures. This type of analysis is considered a benchmark approach in the literature, as discussed in the recent surveys [25, 28] and in other studies, as [6, 8, 9, 18, 24]. Therefore, it is natural to use this analysis in our empirical evaluation.
The following two measures were considered: normalized mutual information (NMI) [13], which quantifies the quality of the disjoint clusters comparing the solution found by a selected algorithm with the baseline (or ground truth), and Murata’s Modularity [16], which quantifies the strength of division of a network into communities. Experiments were executed on a Linux machine with an 6-core processor with 2.60 GHz and 16 GB main memory.
4.1 Synthetic Networks
The benchmark analysis was conducted on thousands of synthetic networks obtained employing a network generation tool called BNOC, proposed in [26]. Each network configuration was replicated 10 times to obtain the average and standard deviation. Default parameters are presented in [26].
First, we evaluated the sensibility of the algorithms regarding the noise level in the networks. The noise level is a disturbance or error in the dataset (the proportion of links wrongly inserted), e.g., 0.5 means that half of the links are not what they should be. Noise can negatively affect the algorithm’s performance in terms of accuracy.
A set of 1000 synthetic bipartite networks with distinct noise level was generated, as follows: \(|\mathcal {V}|=2,000\) with \(|\mathcal {V}^1|=|\mathcal {V}^2|\), noise within the range [0.0, 1.0] and 20 communities for each layer. Figure 6(a) depicts the NMI values for the evaluated algorithm as a function of the amount of noise. The algorithms exhibit distinct behaviors. MLPb and CLPb obtained high NMI values with a low level of noise, however, NMI values for MLPb decrease quickly after 0.22 noise level, whereas CLPb decreases slowly. Therefore, MLPb revealed a high noise sensibility. Although GMb, RGMb and OPM\(_{hem}\) algorithms obtained the lowest NMI values, mainly, within the range [0.0, 0.4], their performances decrease slowly compared with MLPb.
We also evaluated the sensibility of the algorithms regarding the number of communities in the networks. A set of 1000 synthetic bipartite networks with distinct number of communities was generated, as follows: \(|\mathcal {V}|=2,000\) with \(|\mathcal {V}^1|=|\mathcal {V}^2|\), communities within the range [1, 500] and 0.3 of noise level. Figure 6(b) depicts the NMI values for the evaluated algorithm as a function of the number of communities. GMb, RGMb and OPM\(_{hem}\) presented a high sensibility to a low number of communities in the network, specifically, within the range [1, 100], in contrast, CLPb and MLPb obtained high NMI values in the same range. Within the range [200, 500], all algorithms obtained close NMI values.

NMI of the algorithms in relation to the noise level (a) and number of communities and (b) in 2, 000 synthetic networks.
A Nemenyi post-hoc test [5] was applied to the results depicted in Figs. 6(a) and 6(b) to detect statistical differences in the performances of the algorithms. The critical difference (CD) is indicated at the top of each diagram and algorithms’ average ranks are placed in the horizontal axis, with the best ranked to the left. A black line connects algorithms for which there is no significant performance difference. According to the Nemenyi statistics, the critical value for comparing the mean-ranking of two different algorithms at 95 percentiles is 0.04, i.e. significant differences are above this value. CLPb was ranked first followed by GMb, the pair MLPb and RGMb and then, in last, OPM\(_{hem}\). Furthermore, CLPb performs statistically better than MLPb, RGMb and OPM\(_{hem}\) algorithms.


Runtime as a function of link-density in 1, 000 synthetic networks: (b) and (c) shows the total time spent for each algorithm on the experiments, absolute and relative values, respectively.
We assessed the scalability of the algorithms in terms of the absolute and relative total time spent. First, a set of 1000 synthetic networks with distinct link-density was generated, as follows: link-density within the range [0.01, 0.99], wherein 0.01 indicates very sparse networks and 0.99 indicates very dense networks with \(m\approx n^2\); \(|V|=5,000\) with \(|V^1|=|V^2|\) and 20 communities at each layer. Figure 8 shows how each algorithm contributed to the total time, in both absolute values, Figs. 8(a) and 8(b), and relative values, Fig. 8(c) (values shown on top of the bars). The total time spent running the experiments was 419, 857.968 s, or nearly 116 h. CLPb spent 4, 351.2 s, which is nearly \(1.0\%\) of the total time, furthermore, CLPb ran 18 to 35 times faster than the other algorithms. GMb and OPM\(_{hem}\) were the most expensive algorithms.
A set of 1000 synthetic bipartite networks with distinct number of nodes was generated, as follows: the number of nodes within the range [1, 000, 40, 000] and communities as a percentage of the number of nodes, i.e. \(|V|*0.01\). Figure 9 shows how each algorithm contributed to the total time, in both absolute values, Figs. 9(a) and 9(b), and relative values, Fig. 9(c) (values shown on top of the bars). The total time spent running the experiments was 128, 151.711 s, or nearly 35 h. CLPb spent 5, 644.2 s, which is nearly \(4.4\%\) of the total time, furthermore, CLPb ran 3, 3 to 8, 2 times faster than the other algorithms. GMb and OPM\(_{hem}\) were the most expensive algorithms.
4.2 Real-World Networks
We considered six real-world bipartite networks available at KONECT (the Koblenz Network Collection) [10]. We took the largest connected component of each network. Network properties are detailed in Table 2(a). Murata’s modularity was used to obtain the accuracy of the algorithms by reducing the networks to \(30\%\), \(50\%\) and \(80\%\) of its original sizes.

Runtime as a function of the number of nodes in 1, 000 synthetic networks: (b) and (c) show the total time spent for each algorithm on the experiments, absolute and relative values, respectively.
Considering \(30\%\), \(50\%\) and \(80\%\) of network reduction, summarized in Tables 2(b), 2(c) and 2(d), CLPb yielded the best values on 4, 5 and 3 networks, respectively; and MLPb yielded the best values on 2 networks at each of the three cases. The pair GMb and OPM\(_{hem}\) obtained the best value on one network with \(80\%\) of network reduction.
A Nemenyi post-hoc test was applied to the results, shown in Figs. 10(a), 10(b) and 10(c), obtained from \(30\%\), \(50\%\) and \(80\%\) of network reduction, respectively. Figure 10(d) summarizes the overall results. According to the Nemenyi statistics, the critical value for comparing the average-ranking of two algorithms at the 95 percentile is 1.11. According to Fig. 10(d), CLPb was ranked best, followed by MLPb, the pair GMb and OPM and, in last, RGMb. Furthermore, CLPb performs statistically better than GMb, RGMb and OPM\(_{hem}\).
The empirical investigation showed that CLPb yielded more accurate and stable results compared to the standard algorithms and requires considerably lower execution time. It is a strong indicator of its performance on large-enough problem sizes and must foster the development of novel scalable solutions defined in bipartite networks, including network visualization, trajectory mining, community detection or graph partitioning, data dimension reduction and optimization of high-complexity algorithms [3, 15, 27].

Nemenyi post-hoc test: (a), (b) and (c) represent the results depicted in Tables (b), (d) and (d); alternatively, (d) summarizes the overall results.
5 Conclusion
We have proposed a novel time-effective semi-synchronous coarsening algorithm to handle large-scale bipartite networks, called CLPb. We introduce the cross-propagation concept in the model to overcome unstable issues, as the cyclic oscillations found state-of-the-art algorithms. Furthermore, CLPb employs a search strategy that only visits the immediate neighborhood of each node, which is more suitable to evaluate large-scale networks even with high link-density. Consequently, the algorithm has low computational complexity.
Empirical analysis on thousands of networks provided compelling evidence that CLPb outperforms the state-of-the-art algorithms regarding accuracy and demands considerably shorter execution times, specifically, CLPb was 4 to 35 times faster as compared to the established algorithms.
Note, this study intended to present our algorithm and validate them from an empirical approach following the state-of-the-art guidelines [28]. We now intend to employ the CLPb in real applications, e.g., in future work, we plan to extend the CLPb to dimension reduction and semi-supervised classification tasks. Another issue that deserves further attention is its application to network visualization.
Notes
- 1.
The highest-degree nodes are often called hubs.
References
Barber, M.J., Clark, J.W.: Detecting network communities by propagating labels under constraints. Phys. Rev. E 80, 026129 (2009)
Beckett, S.J.: Improved community detection in weighted bipartite networks. R. Soc. Open Sci. 3(1), 140536 (2016)
Cintra, D., Valejo, A., Lopes, A., Oliveira, M.: Visualization to assist interpretation of the multilevel paradigm in bipartite graphs. In: 15th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, pp. 133–140 (2019)
Cordasco, G., Gargano, L.: Label propagation algorithm: a semi-synchronous approach. Int. J. Soc. Netw. Min. 1(1), 3–26 (2012)
Demšar, J.: Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 7, 1–30 (2006)
Dias, M.D., Mansour, M.R., Dias, F., Petronetto, F., Silva, C.T., Nonato, L.G.: A hierarchical network simplification via non-negative matrix factorization. In: Proceedings of the Conference on Graphics, Patterns and Images (SIBGRAPI), pp. 119–126 (2017)
Ding, C., Li, T., Wang, D.: Label propagation on k-partite graphs. In: 2009 International Conference on Machine Learning and Applications, pp. 273–278. IEEE (2009)
Karypis, G., Kumar, V.: Metis - unstructured graph partinioning and sparse matrix ordering system. Technical report, University of Minnesota, Department of Computer Science (1995)
Karypis, G., Kumar, V.: A fast and high quality multilevel scheme for partitioning irregular graphs. SIAM J. Sci. Comput. 20(1), 359–392 (1998)
Kunegis, J.: KONECT: the Koblenz network collection. In: Proceedings of the 22nd International Conference on World Wide Web, pp. 1343–1350 (2013)
Liu, X., Murata, T.: How does label propagation algorithm work in bipartite networks? In: 2009 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology, vol. 3, pp. 5–8. IEEE (2009)
Liu, X., Murata, T.: An efficient algorithm for optimizing bipartite modularity in bipartite networks. J. Adv. Comput. Intell. Intell. Inform. 14(4), 408–415 (2010)
Meilă, M.: Comparing clusterings—an information based distance. J. Multivar. Anal. 98(5), 873–895 (2007)
Meyerhenke, H., Sanders, P., Schulz, C.: Partitioning complex networks via size-constrained clustering. In: Gudmundsson, J., Katajainen, J. (eds.) SEA 2014. LNCS, vol. 8504, pp. 351–363. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-07959-2_30
Minatel, D., Valejo, A., Lopes, A.: Trajectory network assessment based on analysis of stay points cluster. In: Brazilian Conference on Intelligent Systems (BRACIS), pp. 564–569 (2018)
Murata, T.: Modularities for bipartite networks. In: Proceedings of the 20th ACM Conference on Hypertext and Hypermedia, pp. 245–250 (2009)
Newman, M.E.J.: Scientific collaboration networks. II. Shortest paths, weighted networks, and centrality. Phys. Rev. E Stat. Nonlinear Soft Matter Phys. 64(1), 016132 (2001)
Noack, A., Rotta, R.: Multi-level algorithms for modularity clustering. In: Vahrenhold, J. (ed.) SEA 2009. LNCS, vol. 5526, pp. 257–268. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-02011-7_24
de Paulo Faleiros, T., Valejo, A., de Andrade Lopes, A.: Unsupervised learning of textual pattern based on propagation in bipartite graph. Intell. Data Anal. 24(3), 543–565 (2020)
Raghavan, N., Albert, R., Kumara, S.: Near linear time algorithm to detect community structures in large-scale networks. Phys. Rev. E Stat. Nonlinear Soft Matter Phys. 76, 036106 (2007)
Sakellaridi, S., Fang, H.R., Saad, Y.: Graph-based multilevel dimensionality reduction with applications to eigenfaces and latent semantic indexing. In: Proceedings of the International Conference on Machine Learning and Applications (ICMLA), pp. 194–200 (2008)
Valejo, A., Ferreira, V., de Oliveira, M.C.F., de Andrade Lopes, A.: Community detection in bipartite network: a modified coarsening approach. In: Lossio-Ventura, J.A., Alatrista-Salas, H. (eds.) SIMBig 2017. CCIS, vol. 795, pp. 123–136. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-90596-9_9
Valejo, A., Lopes, A., Filho, G., Oliveira, M., Ferreira, V.: One-mode projection-based multilevel approach for community detection in bipartite networks. In: International Symposium on Information Management and Big Data (SIMBig), Track on Social Network and Media Analysis and Mining (SNMAN), pp. 101–108 (2017)
Valejo, A., Faleiros, T.P., Oliveira, M.C.R.F., Lopes, A.: A coarsening method for bipartite networks via weight-constrained label propagation. Knowl. Based Syst. 195, 105678 (2020)
Valejo, A., Ferreira, V., Fabbri, R., Oliveira, M.C.R.F., Lopes, A.: A critical survey of the multilevel method in complex networks. ACM Comput. Surv. 53(2), 35 (2020)
Valejo, A., Goes, F., Romanetto, L.M., Oliveira, M.C.F., Lopes, A.A.: A benchmarking tool for the generation of bipartite network models with overlapping communities. Knowl. Inf. Syst. 62, 1641–1669 (2019)
Valejo, A., Oliveira, M.C.R.F., Filho, G.P., Lopes, A.A.: Multilevel approach for combinatorial optimization in bipartite network. Knowl. Based Syst. 151, 45–61 (2018)
Valejo, A.D.B., de Oliveira dos Santos, W., Naldi, M.C., Zhao, L.: A review and comparative analysis of coarsening algorithms on bipartite networks. Eur. Phys. J. Spec. Top. (4), 1–11 (2021). https://doi.org/10.1140/epjs/s11734-021-00159-0
Walshaw, C.: A multilevel algorithm for force-directed graph drawing. In: Proceedings of the International Symposium on Graph Drawing, vol. 1984, pp. 171–182 (2001)
Zhu, M., Meng, F., Zhou, Y., Yuan, G.: An approximate spectral clustering for community detection based on coarsening networks. Int. J. Adv. Comput. Technol. 4(4), 235–243 (2012)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Valejo, A.D.B. et al. (2021). Coarsening Algorithm via Semi-synchronous Label Propagation for Bipartite Networks. In: Britto, A., Valdivia Delgado, K. (eds) Intelligent Systems. BRACIS 2021. Lecture Notes in Computer Science(), vol 13073. Springer, Cham. https://doi.org/10.1007/978-3-030-91702-9_29
Download citation
DOI: https://doi.org/10.1007/978-3-030-91702-9_29
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-91701-2
Online ISBN: 978-3-030-91702-9
eBook Packages: Computer ScienceComputer Science (R0)