
Abstract
In software development, code autocomplete can be an essential tool in order to accelerate coding. However, many of these tools built into the IDEs are limited to suggesting only methods or arguments, often presenting to the user long lists of irrelevant items. Since innovations introduced by transformer-based models that have reached the state of the art performance in tasks involving natural language processing (NLP), the application of these models also in tasks involving code intelligence, such as code completion, has become a frequent object of study in recent years. In these paper, we present a transformer-based model trained on 1.2 million Java files gathered from top-starred Github repositories. Our evaluation approach was based on measuring the model’s ability to predict the completion of a line, proposing a new metric to measure the applicability of the suggestions that we consider better adapted to the practical reality of the code completion task. With a recently developed Java web project as test set, our experiments showed that in 55.9% of the test cases the model brought at least one suggestion applicable, while the best baseline model presented this in 26.5%.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others


1 Introduction
When building digital solutions, combining good practices of code quality and standardization with fast development is one of the challenges in the field of Software Engineering. In this context of productivity, associated with Integrated Development Environments (IDEs) and often used by developers, code completion can be an essential tool in order to accelerate coding [10].
Many traditional code completion systems works recommending all possible methods or attributes. Although, the list of suggestions is often long, requiring the user to scroll through many irrelevant items. To supply this, intelligent code completion systems propose to reduce these lists to relevant items given the context being edited [1, 10, 13]. However, many of them work exclusively suggesting only methods or arguments [12], that is, not able to complete longer code sequences by suggesting them both together, increasing productivity.
Since innovations introduced by transformer-based solutions such as Bidirectional Encoder Representations from Transformers (BERT) [2], Generative Pre-trained Transformer (GPT) [11] and XLNet [17], natural language processing (NLP) tasks has significantly expanded its range of possibilities in recent years. Dismissing recurrence or convolutions, the transformers model architecture has reached state of the art results in translation tasks mainly based on attention mechanisms [16]. Thus, the application of these models also in tasks involving code intelligence such as code completion has become a frequent target [3, 5, 7, 12, 14].
Even though it has aroused great interest and stimulated much work, there are some open research points in this area. The appropriate use of meaningful datasets for the tasks, modeling and evaluation aspects are among the observed challenges. So our work was developed with this context in perspective. The first contribution of this paper is a transformer-based model trained on 1.2 million Java files focused on code completion. As the second contribution, we point out a new method of evaluating code completion systems, proposing a new metric that we consider closer to measuring the applicability of the suggestion in the real world of software development.
The paper is structured as follows: Sect. 2 discusses the context of related works. After that, Sect. 3 describes our approach for building the corpus, model definition and training. In Sect. 4, we define our model evaluation methodology, and propose a new code completion evaluation metric by arguing how the standard metrics that we are aware of can be problematic in this context. Section 5 presents the results of the experiments and, finally, Sect. 6 concludes this work.
2 Related Work
This section summarizes selected papers in the area, highlighting their objectives, results, techniques, and parameters used. The papers were obtained in a non-systematic review considering the main topics involved in Machine Learning applied to code autocomplete tasks.
A challenge when applying standard language models to tasks like code completion consists of out-of-vocabulary (OOV) words, which can be understood as words that were not observed during training and become unpredictable for many models. This problem can strongly affect the performance since the software developers can create any identifier needed on the code, which is not a frequent problem in natural language tasks [4]. Jian Li et al. [6] proposes a solution for that presenting what they called a pointer mixture network. Based on the context, the proposed model learns to regenerate an OOV word locally repeated through a pointer copy mechanism, and generate a within vocabulary word through an RNN component. To build the training corpus, the source codes were represented in the form of abstract syntax tree (AST). It was evaluated different approaches with JavaScript and Python datasets, totaling 150,000 files each stored in the AST format.
Although, as demonstrated by Rafael-Michael Karampatsis et al. [4], advanced approaches such as variations of the Byte-Pair Encoding (BPE) algorithm can not only deal well with the OOV problem, but also reduce the vocabulary size. Having the BPE as a principle of the tokenization strategy, the GPT-2 [11] is a 1.5B parameter Transformer [16] that performs state of the art results in several natural language tasks. Recently, this model started to be widely explored also for code intelligence tasks.
In this context, Alexey Svyatkovskiy et al. [12] introduces GPT-C, which is a variant of GPT-2 trained from scratch using a large set of data files that comprises over 1.2 billion lines of source code in JavaScript, TypeScript, C# and Python. As the evaluation of the model’s quality, besides the perplexity, was used another two metrics to capture string similarity between suggested and expected code: ROUGE-L, which consists of a variant of the Recall-Oriented Understudy for Gisting Evaluation (ROUGE) based on the Longest Common Subsequence (LCS), and Levenshtein edit similarity. The authors consider the last one a critical metric in this context by affirming that developers tend to accept suggestions even partially matching the expectation, that is, requiring edits. The best model presented was trained on Python, reaching an average perplexity of 1.82, ROUGE-L of 0.80 and an edit similarity of 86.7%.
In addition, Shuai Lu et al. [7] also proposes a GPT model for code completion and text-to-code generation, named CodeGPT. The authors present pretrained models for both Python and Java, with datasets that includes respectively 1.1M and 1.6M functions. For each programming language, they have used two training approaches. The first approach trains the model from scratch, which means that weights are randomly initialized and the vocabulary is newly obtained. The other approach uses GPT-2 model as starting point, taking advantage of the predefined weights and keeping the same vocabulary. The evaluation of the models is made both in token-level, measuring the accuracy in predicting the next token, and line-level, measuring the exact match (EM) and the edit similarity. Their best model reaches a score average of 71.28.
Finally, based on the GPT-2 model as well, we find Tabnine [14]. Available for several IDEs, this is a plugin that displays code sequences as suggestions according to the context. However, we are not aware about performance metrics of this solution, as much as architecture details.
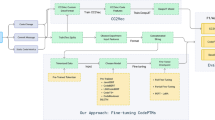
3 Approach
In this session, we describe the construction of our training corpus, as well as detail the model applied and the training process.
3.1 Corpus
We built our corpus selecting public Java projects on Github. In order to increase the probability of obtaining a selection of projects with well-written code, we limited our search for repositories with at least 1500 stars, indicating a good relevance in the community. The corpus is structured in a single text file, using special tokens to delimit the beginning and end of a file, as well as the end of each line. After processing these repositories, we reached 8.12G of total data size, comprising over 1.4 million files and 230 million lines of Java source code.
3.2 Model
The Transformers [16] is a type of deep neural network that relies on attention mechanisms for sequence processing, dispensing with recurrence or convolutions. This architecture applies multiple heads of what the authors called self-attention mechanism, which enables the model to draw complex correlations between tokens in different levels, taking this data into account when predicting the next tokens in a sequence. This type of network overcomes the state of the art approaches such as recurrent neural networks and long short-term memory in many tasks in the field of natural language processing (NLP) and natural language understanding (NLU). In addition, it requires significantly less time to train as it is able to parallelize.
The architecture of our model is the same as the GPT-2 [11], which is an auto-regressive pre-trained model based on 12 layers of Transformer decoders. In order to take advantage of the pre-defined weights and vocabulary, we used the GPT-2 small version pretrained in English as a starting point. This indicates that the resulting model has the original GPT-2 vocabulary and persists the natural language processing skills.
The process of model fine-tuning with the Java Corpus was done with 1 epoch, 1.6 million steps and 96 h of computing time in a single GPU V100. Throughout this article, we’ll refer to our model as Java8G.
4 Evaluation
In this section, we define our evaluation methodology, where we initially propose the creation of a new metric to measure the applicability of the model’s suggestions in code completion, and then we detail how we proceed with the experiments.
4.1 DG Evaluation Metric
This far we already know that language models can also be applied to problems involving code intelligence. However, when looking for the best metric to evaluate the model code suggestions, we found that the application of standard metrics (e.g. Levenshtein and BLEU) to evaluate natural language tasks could be problematic when applied to code completion tasks, meaning that they may not measure the real applicability of a code hint.
Motivated by this, we propose a new metric we consider better adapted to the context of code completion. Given two strings expected and prediction, the DG metric, as formally described in Algorithm 1, calculates the sum of equal characters until there is a divergence between expected and prediction, rated by the expected length.

To support the proposed metric, in Fig. 1, we present two practical cases simulating the string comparison between an expected code and the model prediction by applying edit similarity, one of the metrics used to evaluate the IntelliCode models [12], against DG metric. As we can see, in the case A, the strings are relatively close by the edit similarity metric, but there’s a big difference between them when we talk about the algorithm logic. In such case, we understand that there’s a higher chance of the user skipping the suggestion than accept and edit it to meet the expectation, since it tends to be as less productive as writing the entire sequence. In the other way, we have a lower DG score, showing that only 20% of the prediction could be applied without requiring adaptation.
Now, in the case B, we have a situation where the model effectively suggests part of the expected code, meaning that the user could fully accept the suggestion, but we don’t have it reflected on the edit similarity metric. Even more problematic, we have two very different situations for the practical reality of the code completion presenting the same edit similarity score (67.6%). That’s not the case for DG score where we have a full match, meaning that the suggestion is perfectly applicable.

Edit Similarity and DG Metric in code completion
4.2 Methodology
The DG metric creation and evaluation methodology we defined was based on the attempt to get as close as possible to the practical reality of using a code completion tool. For this purpose, our approach was based on submitting the model to try to complete a line given specific previous contexts, and evaluate the applicability of the predictions in the current line using the DG metric.
To base the execution of the tests we selected a real project of an Web API recently developed with Spring Boot, one of the most popular Java Frameworks in Web Development. In order to get more insights from the evaluation, we decided to observe the performance in more specific contexts of the project. Thus, we categorized the files in the following groups, which are also often found in other Web API projects: controller, which comprises implementation of classes that handles HTTP requests; service, consisting of classes that implements functionalities and system business rules; test, defining the context of unit testing; generic, for everything else. From this project, we generated 4075 test cases for evaluation.
To define the test cases we worked with the concept of triggers, which can be understood as points of opportunity to display suggestions, like the insertion of characters such as white space, “.", “(" or “@". We consider this examples as triggers for the Java language because we understand them as points where the developer is more likely to seek help from a code completion tool. Therefore, our evaluation system iterates through the project files lines, seeking for triggers to generate test cases, taking what’s before the trigger as input and what’s next as reference to measure the applicability of the predictions. To exemplify this, the Fig. 2 shows how we structured the test cases. Highlighted in dark gray, we have the marker endofcontext right after the trigger “@", meaning that everything before this marker, in white, is the input sent to the model and, in dark green, what will be used as reference for evaluation.

Example of a test case
For each test case, we request twice the model to generate two sequences of 16 tokens. For each model prediction, we create two suggestions: the long suggestion (L) and the short suggestion (S). In the Fig. 3 we show highlighted a demonstration of the model suggestions and their types in a plugin developed for IDEA IntelliJ. Therefore, the L suggestions are the complete predictions of the model within the boundary of a line. As an attempt to increase the performance of the model, the short suggestions presents only a part of the predicted sequence, since we understand that there’s a higher probability of the model to correctly predict a short next part of the code than trying to complete the entire line. As shown, the S suggestions are the first alphabetical part of the L suggestions.

Java8G suggestions on IntelliJ
4.3 Baseline
We selected the Microsoft CodeGPT [7] Java model as baseline, since our model is also based on the GPT architecture. We ran the tests with both models versions available on HuggingFace [15]: the CodeGPT [8], which is trained from scratch, and the CodeGPT-Adapted [9], that is pretrained in English as well as our model.
5 Results
In this section we present different analyzes and interpretations of the results obtained in the experiments.
In Fig. 4 we present the models long and short suggestions score average in two metrics: DG, on the left, and edit similarity on the right. As we can see, unlike the DG Metric, the L suggestions performed better than S in edit similarity. This highlights the problem of using this metric when you want to measure the applicability of the model’s predictions. Since S is part of the L suggestion, if L is applicable, then S should be as well. The opposite happens with the edit similarity because it considers the length of the target to calculate the score, penalizing the suggestion score even with it fully matching a initial part of the target. Therefore, with DG Metric, the S suggestions must have a superior or at least equivalent performance compared to the L suggestion. And, as we can see, the model tends to predict shorter sequences more accurately than longer sequences, meeting the initial expectation regarding the creation of short suggestions.

Suggestions DG and Edit Similarity score average
By analysing the Fig. 5, in which we again demonstrate the score average of both DG metric and edit similarity, but this time with the individual results for each code category, we can observe a pattern: in most of the analysis the performance in the controller category presented the best results. Intuitively, by analyzing the code pattern applied in these contexts, we can deduce that, since it is usually formed by blocks of codes that are remarkably often repeated, we understand that it tends to become more easily predictable by the model. The same could explain the lower performance on the service category, where there tend to have fewer patterns or repetitions that can increase the predictive capacity of the model. For ease of reading and comparison, we also present this data in tabular form, in Table 1, adding the average of the metric for each tested model.

Suggestions DG and Edit Similarity score by category

Presence of full matching suggestions in each test case
Analyzing the average performance of the metrics can give us a good overview of the model’s performance. However, since we understand that the developer tends to ignore suggestions that require corrections, the analysis considering partially matching suggestions can be limited. This way, looking deeper into the data, in Fig. 6 we try to answer an important question: of all the test scenarios applied, how many presented at least one full matching suggestion? As we can see, our model in 55% the tests brought at least one full match suggestion, while the best CodeGPT model present this in 26.5% of the cases. Again, we present the view in tabular form in Table 2.
6 Conclusion
We presented a GPT-2 based model trained on 1.2 million Java files focused on code completion. We also introduced the DG Metric, a new approach that we consider closer to measure the applicability of the suggestion in the real world of the software development compared to standard metrics such as Levenshtein that, as we demonstrated, can be problematic.
We also look to run tests on a real and newly developed project, seeking to get a real idea of the model’s completion capability in a situation as close to reality as we could simulate. Among different analyzes shown, we demonstrated that our model presented at least one fully applicable suggestion in more than half of the test cases, outperforming in 2 times the baseline models.
The results corroborate, along with other studies in this field, that transformers-based models have great potential in code intelligence tasks. In the future, as also proposed by Alexey Svyatkovskiy et al. [12], we plan to finetune the model for user personalization, making the model sensitive to specific standards of each project, enhancing the performance of the suggestions.
References
Bruch, M., Monperrus, M., Mezini, M.: Learning from examples to improve code completion systems. In: Proceedings of the 7th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on The Foundations of Software Engineering, ESEC/FSE ’09, pp. 213–222. Association for Computing Machinery, New York (2020). ISBN 9781605580012, https://doi.org/10.1145/1595696.1595728
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, Minnesota, vol. 1 (Long and Short Papers), pp. 4171–4186. Association for Computational Linguistics (2019). https://doi.org/10.18653/v1/N19-1423, https://www.aclweb.org/anthology/N19-1423
Feng, Z., et al.: CodeBERT: a pre-trained model for programming and natural languages. In: Findings of the Association for Computational Linguistics: EMNLP 2020, pp. 1536–1547. Association for Computational Linguistics (2020). https://doi.org/10.18653/v1/2020.findings-emnlp.139, https://www.aclweb.org/anthology/2020.findings-emnlp.139
Karampatsis, R.M., Babii, H., Robbes, R., Sutton, C., Janes, A.: Big code != big vocabulary. In: Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering (2020). https://doi.org/10.1145/3377811.3380342, http://dx.doi.org/10.1145/3377811.3380342
Kim, S., Zhao, J., Tian, Y., Chandra, S.: Code prediction by feeding trees to transformers. In: 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE), pp. 150–162 (2021). https://doi.org/10.1109/ICSE43902.2021.00026
Li, J., Wang, Y., Lyu, M.R., King, I.: Code completion with neural attention and pointer networks. In: Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (2018). https://doi.org/10.24963/ijcai.2018/578, http://dx.doi.org/10.24963/ijcai.2018/578
Shuai, L., et al.: A machine learning benchmark dataset for code understanding and generation, Codexglue (2021)
Microsoft Code GPT small Java (2021). https://huggingface.co/microsoft/CodeGPT-small-java, Accessed 18 May 2021
Microsoft Code GPT small Java adapted GPT-2 (2021). https://huggingface.co/microsoft/CodeGPT-small-java-adaptedGPT2, Accessed 18 May 2021
Proksch, S., Lerch, J., Mezini, M.: Intelligent code completion with bayesian networks. ACM Trans. Softw. Eng. Methodol. 25(1) (2015). ISSN 1049–331X, https://doi.org/10.1145/2744200
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I.: Language Models are Unsupervised Multitask Learners (2019). https://openai.com/blog/better-language-models/
Svyatkovskiy, A., Deng, S.K., Fu, S., Sundaresan, N.: Intellicode compose: code generation using transformer. In: Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2020, New York, NY, USA, pp. 1433–1443. Association for Computing Machinery (2020). ISBN 9781450370431, https://doi.org/10.1145/3368089.3417058
Svyatkovskiy, A., Zhao, Y., Fu, S., Sundaresan, N.: Pythia: ai-assisted code completion system. In: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (2019). https://doi.org/10.1145/3292500.3330699
Tabnine. Code faster with AI completions (2021). https://www.tabnine.com/, Accessed 18 May 2021
The AI community building the future (2021). https://huggingface.co/, Accessed 18 May 2021
Vaswani, A., et al.: Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, Red Hook, NY, USA, pp. 6000–6010. Curran Associates Inc. (2017). ISBN 9781510860964
Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R.R., Le, Q.V.: Xlnet: generalized autoregressive pretraining for language understanding. In: Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R. (eds.) Advances in Neural Information Processing Systems, vol. 32. Curran Associates Inc. (2019). https://proceedings.neurips.cc/paper/2019/file/dc6a7e655d7e5840e66733e9ee67cc69-Paper.pdf
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Meyrer, G.T., Araújo, D.A., Rigo, S.J. (2021). Code Autocomplete Using Transformers. In: Britto, A., Valdivia Delgado, K. (eds) Intelligent Systems. BRACIS 2021. Lecture Notes in Computer Science(), vol 13074. Springer, Cham. https://doi.org/10.1007/978-3-030-91699-2_15
Download citation
DOI: https://doi.org/10.1007/978-3-030-91699-2_15
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-91698-5
Online ISBN: 978-3-030-91699-2
eBook Packages: Computer ScienceComputer Science (R0)