
Abstract
The translation of natural language questions to SQL queries has attracted growing attention, in particular in connection with transformers and similar language models. A large number of techniques are geared towards the English language; in this work, we thus investigated translation to SQL when input questions are given in the Portuguese language. To do so, we properly adapted state-of-the-art tools and resources. We changed the RAT-SQL+GAP system by relying on a multilingual BART model (we report tests with other language models), and we produced a translated version of the Spider dataset. Our experiments expose interesting phenomena that arise when non-English languages are targeted; in particular, it is better to train with original and translated training datasets together, even if a single target language is desired. This multilingual BART model fine-tuned with a double-size training dataset (English and Portuguese) achieved 83% of the baseline, making inferences for the Portuguese test dataset. This investigation can help other researchers to produce results in Machine Learning in a language different from English. Our multilingual ready version of RAT-SQL+GAP and the data are available, open-sourced as mRAT-SQL+GAP at: https://github.com/C4AI/gap-text2sql.
Supported by IBM and FAPESP (São Paulo Research Foundation).
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others


1 Introduction
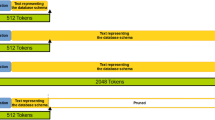
A huge number of data is now organized in relational databases and typically accessed through SQL (Structured Query Language) queries. The interest in automatically translating questions expressed in natural language to SQL (often referred to as NL2SQL) has been intense, as one can observe through a number of excellent surveys in the literature [1,2,3]. Figure 1 depicts the whole flow from a natural language question to a SQL query result; the SQL query refers to database tables and their columns, using primary and secondary keys as appropriate.
Existing approaches for NL2SQL can be divided into entity-based and machine learning ones, the latter dominated by techniques based on deep learning [3].

From a natural language question to a SQL query and to the database query result. Database table names appear in blue (singer) and red (song), while the primary key appears in green (Singer_ID). (Color figure online)
Entity-based approaches focus on the interpretation of input text based on rules so as to translate it to a SQL query. The translation often goes first to an intermediary state and later to a final SQL query. Relevant systems are Bela [4], SODA [5], NaLIR [6,7,8], TR Discover [9], Athena [10, 11], Athena++ [12] and Duoquest [13, 14] .
Machine learning approaches are based on supervised learning, in which training data contains natural language questions and paired SQL queries [3]. Several architectures can be trained or fine-tuned so as to run the translation. Relevant systems are EchoQuery [15], Seq2SQL [41], SQLNet [16], DialSQL [17], TypeSQL [18], SyntaxSQLNet [19], AugmentedBI [21], IRNet [22], RAT-SQL [23], RAT-SQL+GAP [24], GraPPa [25], BRIDGE [26], DBPal [27,28,29], HydraNet [30], DT-Fixup [32] and LGESQL [31].
There are also hybrid approaches that combine entity-based and machine learning [3]; relevant examples are Aqqu [34], MEANS [35] and QUEST [33].
The previous paragraphs contain long lists of references that should suffice to demonstrate that translation from natural language to SQL is a well explored research topic. The field is relatively mature and benchmarks for NL2SQL are now widely used, containing training and testing data and ways to evaluate new proposals. Table 1 shows a few important datasets in the literature, reporting their number of questions, number of SQL queries, number of databases, number of domain and tables per database [20]. Particularly, the Spider dataset is a popular resource that contains 200 databases with multiple tables under 138 domains.Footnote 1 The complexity of these tables allows testing complex nested SQL queries. A solid test suite evaluation package for testing against Spider [46] is available;Footnote 2 in addition, there is a very active leaderboard rank for tests that use Spider.Footnote 3
Currently, the best result in the Spider leaderboard for Exact set match without values, whereby a paper and code are available, is the entry by RAT-SQL+GAP [24].Footnote 4 This system appears in the 6th rank position with Dev 0.718 and Test 0.697.Footnote 5 Note that the Spider leaderboard, as of August 2021, displays in the 1st rank position LGESQL [31] with Dev 0.751 and Test 0.720 for Exact set match without values. Thus RAT-SQL+GAP is arguably at the state-of-art in NL2SQL.
RAT-SQL+GAP is based on the RAT-SQL package (Relation-Aware Transformer SQL) [23]. RAT-SQL was proposed in 2019 as a text to SQL parser based on the BERT language model [47]. Package RAT-SQL version 3 with BERT is currently the 14th entry in the Spider leaderboard rank. RAT-SQL+GAP adds Generation-Augmented Pre-training (GAP) to RAT-SQL. GAP produces synthetic data to increase the dataset size to improve pre-training; the whole generative models are trained by fine-tuning a BART [48] large model.
Despite the substantial number of techniques, systems and benchmarks for NL2SQL, most of them focus on the English language. Very few results can be found for input questions in the Portuguese language, for example. The study by Silva et al. [51] presents an architecture for NL2SQL in which natural language questions in Portuguese are translated to the English language on arrival, and are then shipped to NL2SQL existing packages.
The goal of this paper is simple to state: we present a translator for queries in Portuguese natural language into SQL. We intend to study the effect of replacing the questions in the Spider dataset with translated versions, and also to investigate how to adapt the RAT-SQL+GAP system to the needs of a different language. Using a new version of Spider with RAT-SQL+GAP to train models, we produce inferences and compare results so as to understand the difficulties and limitations of various ideas.
What we found is that, by focusing on Portuguese, we actually produced methods and results that apply to any multilingual NL2SQL task. An important insight (and possibly the main contribution of this paper) is dealing with a non-English language, such as Portuguese, we greatly benefit from taking a multilingual approach that puts together English and the other language—in our case, English and Portuguese. We later stress this idea when we discuss our experiments. We thus refer to our “multilingual-ready” version of RAT-SQL+GAP as mRAT-SQL+GAP; all code and relevant data related to this system are freely availableFootnote 6.
2 Preliminary Tasks
The adaptation to language other than English demands at least the translation of the dataset and changing the code to read and write files UTF-8 encoding.
2.1 Translating the Spider Dataset
The translation to the Portuguese language in the NL2SQL task evolves the natural language part, the questions. The SQL queries must remain the same to make sense. To translate the questions, it is important to extract them from specific .json files. The Spider dataset has three files that contain input questions and their corresponding SQL queries: dev.json, train_others.json, and train_spider.json. We extracted the questions and translated them using the Google Cloud Translation API.Footnote 7. Table 2 presents the number of questions and number of characters per file (just for the questions). The code that reads the original files and that generates translated versions relies on the UTF-8 encoding so as to accept Portuguese characters; several files were generated in the process (.txt just for the translated questions, .csv for the SQL queries and original/translated questions, .json for the translated questions).
We then conducted a revision process by going through the text file and looking for questions in the csv file (together with the corresponding SQL queries). After the revision, a new .json file was generated with these translated and revised questions. Table 3 shows four examples of translated questions.
Adapting the RAT-SQL+GAP System. We had to change the RAT-SQL+ GAP code to allow multilingual processing. For instance, the original Python code is not prepared to handle UTF-8 files; thus, we had to modify the occurrences of “open” and “json.dump” commands, together with a few other changes. We ran a RAT-SQL+GAP test and checked whether all the characters employed in Portuguese were preserved. We also noticed lemmatization errors in preprocessed files. As the original code for RAT-SQL+GAP relies on the Stanford CoreNLP lemmatization tool that currently does not support Portuguese, it was replaced by Simplemma.Footnote 8 The latter package supports multilingual texts, and particularly supports Portuguese and English.
Training. The original language model at the heart of RAT-SQL+GAP is BART-largeFootnote 9 [48], a language model pretrained for the English language. We had to change that model to another one that was pretrained for the Portuguese language. A sensible option was to work with a multilingual Sequence-to-Sequence BART model; the choice was mBART-50Footnote 10 [50] because it covers Portuguese and English languages (amongst many others). Another language model we investigated was the BERTimbau-baseFootnote 11 [49], as RAT-SQL works with BERT; the move to BERTtimbau, a Portuguese-based version of BERT, seemed promising.
Dataset. A total of 8,659 questions were used for training (7,000 questions in train_spider.json and 1,659 questions in train_others.json). The 1,034 questions in dev.json were used for testing. We later refer to three scenarios:
-
English train and test: questions are just in English for training and testing.
-
Portuguese train and testFootnote 12: questions are just in Portuguese for training and testing.
-
English and Portuguese (double-size) train and test(see footnote 12): questions are in English and Portuguese for training and testing (in this case, we thus have twice as much data as in each of the two previous individual scenarios).
Evaluation Metrics. The main evaluation metric with respect to Spider is Exact Set Match (ESM). We here present results for Exact Set Match (ESM) without values, as most results in the Spider leaderboard currently adopt this metric. Some Spider metrics are also used to classify the SQL queries into 4 levels: easy, medium, hard and extra hard. Table 4 shows an example for each level; these queries correspond to the four questions in Table 3 in the same order.
To evaluate the results, we used the Spider test suite evaluation [46]. An aside: the suite must receive a text file with the SQL query generated and another one with the gold-standard SQL query. These files obviously do not change when we move from English to any other input language.
As a digression, note that it is possible to plug values during evaluation. A query with a value looks like this:
SELECT Count(*) FROM airlines JOIN airports WHERE airports.City = “Abilene"
A query without values has the word “terminal" instead of the value:
SELECT Count(*) FROM airlines JOIN airports WHERE airports.City = “terminal"
3 Experiments
Experiments were run in a machine with AMD Ryzen 9 3950X 16-Core Processor, 64 GB RAM, 2 GPUs NVidia GeForce RTX 3090 24 GB running Ubuntu 20.04.2 LTS. Figure 2 shows the architecture of the training, inference and evaluation processes described in this section.
Results can be found in Table 5. This table shows the results of Exact Set Match without Values for RAT-SQL+GAP trained locally for all models. We have 3 datasets, 5 trained model checkpoints and 7 distinct relevant results.
The first line corresponds to the original model BART and original questions in English. Note that the result in line #1 achieved the same performance reported by [24] for Exact Set Match without values in Spider: 0.718 (All) for Dev. This indicates that our testing apparatus can produce state-of-the-art results. Moreover, line #1 shows a well-tuned model in English that can be attained.

Architecture of the training, inference, evaluation. Results related to Table 5: each line in that table appears here as a square at the bottom of the figure.
Our first experiment was to change the questions to Portuguese and the model to BERTimbau-base which is pretrained in Portuguese. In Table 5 the result in line #2 for BERTimbau 0,417(All) is quite low when compared to the result in line #1. This happens for many reasons. The model is BERT and the best result uses BART. Another important difference is that the Portuguese content used in fine-tuning has a mixture of Portuguese and English words because the SQL query inevitably consists of English keywords, see examples of SQL queries in Table 4. In fact, some questions demand untranslated words to make sense, for example “Boston Red Stockings” in the translated question: Qual é o salário médio dos jogadores da equipe chamada "Boston Red Stockings"?. This suggested that a multilingual approach might be more successful. The mBART-50 language model was then tested within the whole architecture.
mBART-50 was in fact fine-tuned in three different ways: with questions only in English, only in Portuguese, and with questions both in English and in Portuguese (that is, a dataset with questions and their translations). Inferences were run with English test questions and Portuguese test questions, while the model was fine-tuned with the corresponding training questions language. For the mBART-50 model fine-tuned with the train dataset with two languages, three inferences were made: only English, only Portuguese, and the combined English Portuguese test dataset.
mBART-50 fine-tuned with questions in English in line #3 achieved 0.651 (All) when tested with questions in English. The same model mBART-50 fine-tuned with questions in Portuguese in line #4 achieved 0.588(All) when tested with questions in Portuguese.
A multilingual model such as mBART-50 can be trained with the two languages at the same time. This is certainly appropriate for data augmentation and to produce a fine-tuning process that can better generalize. The results in Table 5 lines #5, #6 and #7 were obtained with mBART-50 fine-tuned with the double-size training dataset (English and Portuguese); the three inferences were made using the same model checkpoint. The test datasets were in English for line #5, in Portuguese for line #6, and the double-size test dataset in English and Portuguese for line #7. The results demonstrate improvements, if we compare inferences with English test dataset lines #3 and #5. Results went up from 0.651 (All) to 0.664 (All), better for all levels of questions. If we compare inferences with the Portuguese test dataset in lines #4 and #6, the results went from 0.588 (All) to 0.595 (All). However, they are better just for an easy level of questions; this was enough to influence the overall results for line #6.

Examples of keywords in the prediction of the SQL query in English and Portuguese languages. Top pair: question in English and corresponding SQL query predicted from it. Bottom pair: question in Portuguese and corresponding SQL query predicted from it.
The inference made with the double-size test dataset in English and Portuguese, in line #7, cannot be compared with the other inferences because they used just one language. Nevertheless, the model mBART-50 trained with English and Portuguese (double-size training dataset) produced good results with this rather uncommon testing dataset.
All the detailed results presented in this paper are openly availableFootnote 13.
4 Analysis and Discussion
These experiments indicate that multilingual pretrained transformers can be extremely useful when dealing with languages other than English. There is always the need to integrate English processing with the additional languages of interest, in our case, with Portuguese.
Overall, questions in the English language have a closer similarity with SQL queries, thus simplifying inferences. Conversely, questions in Portuguese require further work. Figure 3 show a real example of correct predictions in English (Table 5 line #5) and in Portuguese (Table 5 line #6). In Fig. 3, words such as song, names, singers, average in the English question are keywords needed to resolve the query, and they are very close to the target word in the query. In Portuguese, the same keywords are músicas, nomes, cantores, média that must respectively match song, name, singer, and avg. This introduced an additional level of difficulty that explains the slightly worse results for inference with questions in Portuguese: 0.595 (Table 5 line #6). This is to be compared with questions in English: 0.664 (Table 5 line #5). In any case, it is surprising that the same model checkpoint resolved the translation with such different questions.

Example of words that represent the value in the prediction of the SQL query. En Q: English question, Pt Q: Question translated to Portuguese, P: SQL query predicted, and G: Gold SQL query.
Some translations actually keep a mix of languages, because some words represent the value and cannot be translated. Figure 4 shows an example. There the show name “The Rise of the Blue Beetle” should not be translated to maintain the overall meaning of the question; these words in English must be part of the Portuguese question. This successful SQL query inference was produced with mBART-50 fine-tuned with the English and Portuguese training dataset (Table 5 line #6) and mBART-50 fine-tuned in the Portuguese-only training dataset (Table 5 line #4). The show name was then replaced with “terminal” during the RAT-SQL+GAP prediction process, as it is processed through the Spider Exact Set Match without Values evaluation. In any case, the show name is part of the input and will introduce difficulties in the prediction.
In addition, for real-world databases, it is a practice, at least in Brazil, to name tables and columns with English words even for databases with content in Portuguese. This practical matter is another argument in favor of a multilingual approach.
Figure 5 shows a sample of failed translations evaluated by the Spider Exact Set Match for inferences using mBART-50 (Table 5 line #6). It is actually difficult to find the errors without knowing the database schema related to every query. The objective of this figure is to show that even when the query is incorrect, it is not composed of random or nonsensical words. Our manual analysis indicates that this is true for queries failing with all other models.

Sample of failed queries evaluated by Spider Exact Set Match for inferences from mBART-50 (Table 5 line #6) . Q: question, P: SQL query predicted, and G: Gold SQL query.
5 Conclusion and Future Work
In sum, we have explored the possible ways to create a translator that takes questions in the Portuguese language and outputs correct SQL queries corresponding to the questions. By adapting a state-of-the-art NL2SQL to the Portuguese language, our main conclusion is that a multilingual approach is needed: it is not enough to do everything in Portuguese; rather, we must simultaneously work with English and Portuguese.
In Table 5, our best result is in line #5 0.664 (All) whereby we test with questions in English (original test set from Spider) using mBART-50 model fine-tuned with a double-size training dataset (English and Portuguese). This yields 92% of the English-only performance of 0.718 (All) in line #1. Testing with questions in Portuguese (using our translation) with the same BART-50 model fine-tuned with a double-size training dataset (English and Portuguese), we achieve instead 0.595 (All) line #6. Now this is 83% of the English-only performance of 0.718 (All). These results should work as a baseline for future NL2SQL research in Portuguese.
Our multilingual RAT-SQL+GAP, or mRAT-SQL+GAP for short, the translated datasets, the trained checkpoint, and the results; are open-source availableFootnote 14.
Future work should try other multilingual transformers (and possibly other seq-to-seq models), always seeking ways to use English and Portuguese together. Another possible future work is to fine-tune BERTimbau-largeFootnote 15 [49] so as to better understand the effect of the size of the language model. Lastly, a translation of the Spider dataset to other languages so as to work with several languages at the same time should produce valuable insights.
Notes
- 1.
Spider dataset: https://yale-lily.github.io/spider.
- 2.
Spider test suite evaluation github:https://github.com/taoyds/test-suite-sql-eval.
- 3.
Spider leaderboard rank: https://yale-lily.github.io/spider.
- 4.
RAT-SQL+GAP gitHub: https://github.com/awslabs/gap-text2sql.
- 5.
Dev results are obtained locally by the developer; to get official score and Test results, it is necessary to submit the model following guidelines in “Yale Semantic Parsing and Text-to-SQL Challenge (Spider) 1.0 Submission Guideline” at https://worksheets.codalab.org/worksheets/0x82150f426cb94c17b861ef4162817399/.
- 6.
mRAT-SQL+GAP Github: https://github.com/C4AI/gap-text2sql.
- 7.
Cloud Translation API: https://googleapis.dev/python/translation/latest/index.html.
- 8.
Simplemma: a simple multilingual lemmatizer for Python at https://github.com/adbar/simplemma.
- 9.
Facebook BART-large: https://huggingface.co/facebook/bart-large.
- 10.
FacebookmBART-50manyfordifferentmultilingualmachinetranslations: https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt.
- 11.
BERTimbau-base: https://huggingface.co/neuralmind/bert-base-portuguese-cased.
- 12.
Spider dataset translated to Portuguese and double-size (English and Portuguese together): https://github.com/C4AI/gap-text2sql.
- 13.
mRAT-SQL+GAP Github: https://github.com/C4AI/gap-text2sql.
- 14.
mRAT-SQL+GAP Github: https://github.com/C4AI/gap-text2sql.
- 15.
BERTimbau-large: https://huggingface.co/neuralmind/bert-large-portuguese-cased.
References
Kim, H., So, B.H., Han, W.S., Lee, H.: Natural language to SQL: where are we today? Proc. VLDB Endow. 13, 1737–1750 (2020). https://doi.org/10.14778/3401960.3401970
Affolter, K., Stockinger, K., Bernstein, A.: A comparative survey of recent natural language interfaces for databases. VLDB J. 28, 793–819 (2019). https://doi.org/10.1007/s00778-019-00567-8
Ozcan, F., Quamar, A., Sen, J., Lei, C., Efthymiou, V.: State of the art and open challenges in natural language interfaces to data. In: Proceedings of the ACM SIGMOD International Conference on Management of Data, pp. 2629–2636 (2020). https://doi.org/10.1145/3318464.3383128
Walter, S., Unger, C., Cimiano, P., Bär, D.: Evaluation of a layered approach to question answering over linked data. In: Cudré-Mauroux, P., et al. (eds.) ISWC 2012. LNCS, vol. 7650, pp. 362–374. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-35173-0_25
Blunschi, L., Jossen, C., Kossmann, D., Mori, M., Stockinger, K.: SODA: generating SQL for business users. Proc. VLDB Endow. 5, 932–943 (2012). https://doi.org/10.14778/2336664.2336667
Li, F., Jagadish, H. V: Constructing an interactive natural language interface for relational databases. Proc. VLDB Endow. 8, 73–84 (2014). https://doi.org/10.14778/2735461.2735468
Li, F., Jagadish, H. V.: NaLIR: an interactive natural language interface for querying relational databases. In: Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, New York, pp. 709–712. ACM (2014). https://doi.org/10.1145/2588555.2594519
Li, F., Jagadish, H.V.: Understanding natural language queries over relational databases. ACM SIGMOD Rec. 45, 6–13 (2016). https://doi.org/10.1145/2949741.2949744
Song, D., et al.: TR discover: a natural language interface for querying and analyzing interlinked datasets. In: Arenas, M., et al. (eds.) ISWC 2015. LNCS, vol. 9367, pp. 21–37. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-25010-6_2
Saha, D., Floratou, A., Sankaranarayanan, K., Minhas, U.F., Mittal, A.R., Özcan, F.: ATHENA: an ontology-driven system for natural language querying over relational data stores. Proc. VLDB Endow. 9, 1209–1220 (2016). https://doi.org/10.14778/2994509.2994536
Lei, C., et al.: Ontology-based natural language query interfaces for data exploration. IEEE Data Eng. Bull. 41, 52–63 (2018)
Sen, J., et al.: ATHENA++: natural language querying for complex nested SQL queries. Proc. VLDB Endow. 13, 2747–2759 (2020). https://doi.org/10.14778/3407790.3407858
Baik, C., Arbor, A., Arbor, A., Arbor, A., Jagadish, H.V: Constructing expressive relational queries with dual-specification synthesis. In: Proceedings of the 10th Annual Conference Innovations Data Systems Research (CIDR 2020) (2020)
Baik, C., Jin, Z., Cafarella, M., Jagadish, H. V.: Duoquest: a dual-specification system for expressive SQL queries. In: Proceedings of the ACM SIGMOD International Conference on Management of Data, pp. 2319–2329 (2020). https://doi.org/10.1145/3318464.3389776
Lyons, G., Tran, V., Binnig, C., Cetintemel, U., Kraska, T.: Making the case for query-by-voice with echoquery. In: Proceedings of the ACM SIGMOD International Conference on Management of Data, 26-June-20, pp. 2129–2132 (2016). https://doi.org/10.1145/2882903.2899394
Xu, X., Liu, C., Song, D.: SQLNet: generating structured queries from natural language without reinforcement learning. \({\rm arXiv}\). pp. 1–13 (2017)
Gur, I., Yavuz, S., Su, Y., Yan, X.: DialSQL: dialogue based structured query generation. In: ACL 2018–56th Annual Meeting of the Association for Computational Linguistics Proceedings of the Conference (Long Paper 1), pp. 1339–1349 (2018). https://doi.org/10.18653/v1/p18-1124
Yu, T., Li, Z., Zhang, Z., Zhang, R., Radev, D.: TypeSQL: knowledge-based type-aware neural text-to-SQL generation. In: NAACL HLT 2018 - 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies - Proceedings of the Conference, vol. 2, pp. 588–594 (2018). https://doi.org/10.18653/v1/n18-2093
Yu, T., Yasunaga, M., Yang, K., Zhang, R., Wang, D., Li, Z., Radev, D.R.: SyntaxSQLNet: syntax tree networks for complex and cross-domain text-to-SQL task. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 1653–1663. Association for Computational Linguistics, Brussels, Belgium (2018)
Yu, T., et al.: Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. arXiv:1809.08887v5 (2018)
Francia, M., Golfarelli, M., Rizzi, S.: Augmented business intelligence. In: CEUR Workshop Proceedings, vol. 2324 (2019)
Guo, J., et al.: Towards Complex Text-to-SQL in Cross-Domain Database with Intermediate Representation (2019)
Wang, B., Shin, R., Liu, X., Polozov, O., Richardson, M.: RAT-SQL: Relation-aware schema encoding and linking for text-to-SQL parsers. arXiv. (2019). https://doi.org/10.18653/v1/2020.acl-main.677
Shi, P., et al.: Learning Contextual Representations for Semantic Parsing with Generation-Augmented Pre-Training (2020)
Yu, T., et al.: GraPPa: Grammar-Augmented Pre-Training for Table Semantic Parsing (2020)
Lin, X.V., Socher, R., Xiong, C.: Bridging Textual and Tabular Data for Cross-Domain Text-to-SQL Semantic Parsing, pp. 4870–4888 (2020). https://doi.org/10.18653/v1/2020.findings-emnlp.438
Utama, P., et al.: DBPal: An End-to-end Neural Natural Language Interface for Databases (2018)
Basik, F., et al.: DBPal: a learned NL-interface for databases. In: Proceedings of the ACM SIGMOD International Conference on Management of Data, pp. 1765–1768 (2018). https://doi.org/10.1145/3183713.3193562
Weir, N., et al.: DBPal: a fully pluggable NL2SQL training pipeline. In: Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, New York, pp. 2347–2361. ACM (2020). https://doi.org/10.1145/3318464.3380589
Lyu, Q., Chakrabarti, K., Hathi, S., Kundu, S., Zhang, J., Chen, Z.: Hybrid ranking network for text-to-SQL. arXiv. pp. 1–12 (2020)
Cao, R., Chen, L., Chen, Z., Zhao, Y., Zhu, S., Yu, K.: LGESQL: Line Graph Enhanced Text-to-SQL Model with Mixed Local and Non-Local Relations, pp. 2541–2555 (2021). https://doi.org/10.18653/v1/2021.acl-long.198
Xu, P., et al.: Optimizing Deeper Transformers on Small Datasets, pp. 2089–2102 (2021). https://doi.org/10.18653/v1/2021.acl-long.163
Bergamaschi, S., Guerra, F., Interlandi, M., Trillo-Lado, R., Velegrakis, Y.: Combining user and database perspective for solving keyword queries over relational databases. Inf. Syst. 55, 1–19 (2016). https://doi.org/10.1016/j.is.2015.07.005
Bast, H., Haussmann, E.: More accurate question answering on freebase. In: Proceedings of the International on Conference on Information and Knowledge Management, 19–23-October 2015, pp. 1431–1440 (2015). https://doi.org/10.1145/2806416.2806472
Ben Abacha, A., Zweigenbaum, P.: MEANS: a medical question-answering system combining NLP techniques and semantic Web technologies. Inf. Process. Manag. 51, 570–594 (2015). https://doi.org/10.1016/j.ipm.2015.04.006
Iyer, S., Konstas, I., Cheung, A., Krishnamurthy, J., Zettlemoyer, L.: Learning a neural semantic parser from user feedback. In: ACL 2017–55th Annual Meeting of the Association for Computational Linguistics Proceeding Conference (Long Paper 1), pp. 963–973 (2017). https://doi.org/10.18653/v1/P17-1089
Giordani, A., Moschitti, A.: Translating questions to SQL queries with generative parsers discriminatively reranked. In: Coling, pp. 401–410 (2012)
Popescu, A.M., Etzioni, O., Kautz, H.: Towards a theory of natural language interfaces to databases. In: International Conference on Intelligent user Interfaces, Proceedings of the IUI, pp. 149–157 (2003). https://doi.org/10.1145/604050.604070
Zelle, J.M., Mooney, R.J.: Learning to parse database queries using inductive logic programming. In: Proceedings of the National Conference on Artificial Intelligence, pp. 1050–1055 (1996)
Zettlemoyer, L.S., Michael, C.: Learning to map sentences to logical form: structured classification with probabilistic categorial grammars. In: Proceedings of the 21st Conference on Uncertain Artificial Intelligence, UAI 2005, pp. 658–666 (2005)
Zhong, V., Xiong, C., Socher, R.: Seq2Sql: Generating Structured Queries From Natural Language Using Reinforcement Learning. arXiv:1709.00103v7. pp. 1–12 (2017)
Zettlemoyer, L.S., Collins, M.: Online learning of relaxed CCG grammars for parsing to logical form. In: EMNLP-CoNLL 2007 - Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, pp. 678–687 (2007)
Price, P.J.: Evaluation of spoken language systems. In: Proceedings of the workshop on Speech and Natural Language - HLT 1990, pp. 91–95. Association for Computational Linguistics, Morristown, NJ, USA (1990). https://doi.org/10.3115/116580.116612
Dahl, D.A., et al.: Expanding the scope of the ATIS task 43 (1994). https://doi.org/10.3115/1075812.1075823
Hemphill, C.T., Godfrey, J.J., George, R.D.: The ATIS spoken language systems pilot corpus. In: Proceedings of the DARPA Speech and Natural Language Workshop., Hidden Valley, Pennsylvania (1990)
Zhong, R., Yu, T., Klein, D.: Semantic evaluation for Text-to-SQL with distilled test suites. arXiv. (2020). https://doi.org/10.18653/v1/2020.emnlp-main.29
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: pre-training of deep bidirectional transformers for language understanding. In: NAACL HLT 2019–2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies - Proceedings of the Conference, vol. 1, pp. 4171–4186 (2019)
Lewis, M., et al.: BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension (2019)
Souza, F., Nogueira, R., Lotufo, R.: BERTimbau: pretrained BERT models for Brazilian Portuguese. In: Cerri, R., Prati, R.C. (eds.) BRACIS 2020. LNCS (LNAI), vol. 12319, pp. 403–417. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-61377-8_28
Tang, Y., et al.: Multilingual Translation with Extensible Multilingual Pretraining and Finetuning. arXiv:2008.00401 (2020)
da Silva, C.F.M., Jindal, R.: SQL query from portuguese language using natural language processing. In: Garg, D., Wong, K., Sarangapani, J., Gupta, S.K. (eds.) IACC 2020. CCIS, vol. 1367, pp. 323–335. Springer, Singapore (2021). https://doi.org/10.1007/978-981-16-0401-0_25
Acknowledgment
This work was carried out at the Center for Artificial Intelligence (C4AI-USP), supported by the São Paulo Research Foundation (FAPESP grant #2019/07665-4) and by the IBM Corporation. The second author is partially supported by the Conselho Nacional de Desenvolvimento Científico e Tecnológico (CNPq), grant 312180/2018-7.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
José, M.A., Cozman, F.G. (2021). mRAT-SQL+GAP: A Portuguese Text-to-SQL Transformer. In: Britto, A., Valdivia Delgado, K. (eds) Intelligent Systems. BRACIS 2021. Lecture Notes in Computer Science(), vol 13074. Springer, Cham. https://doi.org/10.1007/978-3-030-91699-2_35
Download citation
DOI: https://doi.org/10.1007/978-3-030-91699-2_35
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-91698-5
Online ISBN: 978-3-030-91699-2
eBook Packages: Computer ScienceComputer Science (R0)