
Abstract
Improving the interaction between consumers and marketplaces, focusing on reaching higher conversion rates is one of the main goals of e-commerce companies. Offering better results for user queries is mandatory to improve user experience and convert it into purchases. This paper investigates how named entity recognition can extract relevant attributes from product titles to derive better filters for user queries. We conducted several experiments based on MITIE and BERT applied to smartphones/cellphones product titles from the largest Brazilian retail e-commerce. Both of our strategies achieve outstanding results with a general F1 score of around 95%. We concluded that using a classical machine learning pipeline is still more useful than relying on large pre-trained language models, considering the model’s throughput and efficiency. Future work may focus on evaluating the scalability and reusability capacity of both approaches.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others

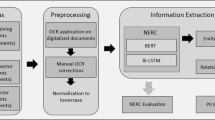

1 Introduction
Improving the interaction between consumers and marketplaces, focusing on reaching higher conversion rates is one of the most significant challenges faced by e-commerce companies. In other words, the primary goal in this scenario is to guide the users to purchase the items they are searching in the platform. Therefore, due to the increasing specificity of search, the shopping experience becomes a bottleneck in this scenario, even for big e-commerce companies.
E-commerce shopping becomes a more daily activity than ever. In the pandemic scenario, Brazilian e-commerces saw an increase of 47% of purchases, according to Ebit|Nelson 2020 reportFootnote 1. Besides, the product assortment, particularly for marketplaces, is getting more complicated since e-commerce is replacing traditional retail settings, like groceries and health care supply. A traditional marketplace strategy to improve product assortment is to introduce more sellers into the marketplace platform. On the one hand, it makes the consumers’ lives easier, since they can acquire their needs in only one platform. On the other hand, it makes the product assortment to be increasingly non-uniform. Product titles broadly vary, either by their sellers or their nature/category.
Consider the following examples from our data to illustrate these problems:
-
1.
Smartphone Samsung Galaxy A01, 32 GB, 2 GB RAM, Tela Infinita de 5.7\(^{\prime \prime }\) , Câmera Dupla Traseira 13MP (Principal) + 2MP (Profundidade), Frontal de 5MP, Bateria de 3000 mAh, Dual Chip, Android - AzulFootnote 2
-
2.
Smartphone Moto G9 Play 64 GB Dual Chip Android 10 Tela 6.5\(^{\prime \prime }\) Qualcomm Snapdragon 4G Câmera 48MP+2MP+ 2MP - Verde TurquesaFootnote 3
-
3.
iPhone SE 128 GB Preto iOS 4G Wi-Fi Tela 4.7\(^{\prime \prime }\) Câmera 12MP + 7MP - AppleFootnote 4
The first title offers the following information: WITFootnote 5 (Smartphone); brand (Samsung); model (Galaxy A01); internal memory (32 GB); display size (5.7\(^{\prime \prime }\)); quality of the cameras (13MP and 5MP); SIM card capacity (Dual chips) and color (Azul – “Blue” in Brazilian Portuguese). In the second example, the brand name is not explicit, but we can find the operational system (Android 10) and processor (Qualcomm Snapdragon) specifications. The last example shows: brand (Apple); model (SE); internal memory (128 GB); color (preto – “black” in Portuguese); display size (4,7\(^{\prime \prime }\)) and quality of the cameras (12MP and 7MP).
From these examples, we can see that the titles from a quite common category (Smartphone) do not follow a standard structure and are not even offering the same information. As a consequence, it is very difficult to specify standard search filters that could fit any title or query in this category.
In this scenario, increasing the products’ retrieval becomes a difficult challenge. A syntax-based search engine is not enough to make all the assortment accessible to the customer. Commonly, e-commerces web pages offer facets to filter customer queries. It becomes a critical task for offering useful filters, having a uniform, vast, and high-quality product attribute extraction in place [11].
Hence, motivated by improving the human interaction with our e-commerce platform, we investigated how named entity recognition could be applied to identify attributes in product titles of the Smartphone categoryFootnote 6. We investigated two approaches: MITIEFootnote 7 and BERT [6].
From our experiments we found that models trained with MITIE and BERT had very similar results, achieving around 95% in F1 scores. MITIE was chosen as the best one for our scenario due to other advantages such as its prediction latency and required infra-structure.
Thus, the main contributions of this work are:
-
The description of an end-to-end approach of corpus annotation, model building and evaluation for attribute-value pairs extraction from product titles;
-
The careful comparison of two state-of-the-art models for named entity recognition – MITIE and BERT – in a not well explored domain (e/commerce);
-
The addressing of a poorly explored scenario of e-commerce language for Brazilian Portuguese.
This paper is organized as follows. In Sect. 2 we describe the task of named entity recognition and the approaches proposed to perform it. In Sect. 3 we describe the set of attribute products that we found relevant for our problem. The experiments and results are presented in Sect. 4 and Sect. 5 finishes the paper with some final remarks.
2 Background and Related Work
Named Entity Recognition. (NER) is a subtask of natural language processing (NLP) or information extraction (IE) that tries to identify and classify “named entities” present in unstructured text. Named entities are well-known predefined categories such as people’s names (e.g., Bill), organizations (e.g., United Nations), locations (e.g., Brazil), time expressions (e.g., yesterday), quantities (e.g., liter), monetary values (e.g., dollar), among others. In the scope of e-commerce, our named entities will be renamed to attributes, and the attributes that are of our interest will be specified in Sect. 3.
As noted by More [11], extracting attributes from product titles in e/commerce is a difficult task since titles, in this context, lack syntactic structure. For this purpose, the author proposes a NER-based method and demonstrates results on the particular attribute “brand”. More’s proposal consists of combining Structured Perceptron and Conditional Random Fields to predict BIO (B = begin, I = in, O = out) tags in product titles in English. The author used an automatically labeled (by regex) dataset to train the models and increased its volume and quality by a post-processing step, which includes augmenting a normalization dictionary and manual feedback from domain experts. The author reports a F1-score of 92% for the attribute “brand”.
Xu et al. [18] proposed an approach to support value extraction, scaling up to thousands of attributes with no loss of performance. The approach proposed by those authors uses: (i) a global set of BIO tags, (ii) a model of semantic representation for attributes and titles, and (iii) an attention mechanism to capture the semantic relations. The proposed model processes up to 8,906 attributes with an overall F1 score of 79.12%.
Cheng et al. [4] explored NER in the e-commerce context, proposing an end-to-end procedure to query annotation and extraction for English language, using BIO as a sequence tagging format and establishing two important entities to investigate: “brand” and “product type”. The annotation process was carried out with 16k queries. The proposed model reached a F1 score of 99.49% for the validation data and 93.30% for the test data.
Real et al. [14] presented the use of NER in the process of title generation in the fashion e-commerce context. The experiments showed that using a context-specific human-annotated data set for training, even though small (only 358 examples), achieved an overall F1 score of 71%. The solution proposed uses MITIE.
Recently, one of the greatest revolutions in NLP area was the development of the contextualized language models such as the Bidirectional Encoder Representations from Transformers (BERT) [6]. This language model encodes the text to a vector space where words with similar meanings are close to each other through a series of bidirectional self-attention heads. Unlike other well-known word embedding models, such as GloVe [13] and Word2Vec [10], BERT is capable of embedding words considering their specific contexts. BERT has been used successfully in several NLP tasks as an off-the-shelf solution. To achieve these results, BERT was trained in an unsupervised procedure, using corpora that sum up billions of words.
Souza et al. [15] trained a BERT-CRF to the NER task on the Portuguese language, and explored feature-based and fine-tuning training strategies for the BERT model. Their fine-tuning approach obtained new state-of-the-art results on the HAREM I dataset [1], improving the F1-score by 1 point on the selective scenario (5 Named Entities classes) and by 4 points on the total scenario (10 classes of Named Entities).
Besides BERT, we also investigate how the well-known MIT Information Extraction tool (MITIE) perform for the extraction of attributes from product titles. Geyer et al. [7] used MITIE to recognize named entities on a corpus consisting of 5,991 tweets in English, which have been annotated on seven different categories: person, organization, location, event, product, character, and thing. They varied the number of training documents and tested on the remainder of the documents, utilizing 5-fold cross-validation and only in-domain data. Their results showed that training with in-domain data began to show diminishing returns with 500 training documents across all of the entity types other than character and thing.
To the best of our knowledge this is the first work to investigate, in depth, the attribute-value extraction for the e-commerce domain in Brazilian Portuguese.
3 Attribute Set
To define which attributes are relevant in Smartphone category, after an initial analysis of Smartphone titles, 10 attributes were selected for being investigated in this work:
-
1.
WIT: WIT stands for “What Is This” and is attached to the expression that better represents the product. In this work, the possible values for this attribute are: “smartphone”, “celular” (cell phone), “iphone” and other spelling variations. For exampleFootnote 8:

-
2.
Brand: The brand is one of the most relevant attributes in a customer query. Common values for this attribute are: “Motorola”, “Apple”, “Samsung”, “Xiaomi”, “Blu”, among others. For example:

-
3.
Model: The model is also an important attribute for queries in this category and should be extracted in its maximum extension. For example:

-
4.
Internal memory: The internal memory capacity is usually an important attribute for this category and must be extracted together with its unit measure in gigabytes (GB). Common values for this attribute are: 4 GB, 8 GB, 16 GB, 32 GB, 64 GB, 128 GB, 256 GB and 512 GB. For example:

-
5.
Display size: The display size should also be extracted with its unit measure in inches (”). The values for this attribute generally range from 4.7” to 6.1”. For example:

-
6.
Processor: Common values for this attribute are: “Dual-Core”, “Quad-Core”, “Hexa-Core”, “Octa-Core”, “Helio”, among others. For example:

-
7.
Camera quality: The quality of the smartphone camera is usually an attribute of great interest to customers. Subsequently, the resolution in megapixels (MP) must be extracted with its unit measure. The values for this attribute usually range from 5.0 MP to 18.0 MP. For example:

-
8.
Color: When the color of the product appears in the title, it must be extracted as a relevant attribute. For example:

-
9.
Operating system: The operational system is an extremely relevant attribute for the smartphone category. The version of the operational system must also be extracted. Common values for this attribute are: “Android”, “IOS”, “Windows Phone”, “Blackberry OS”, among others. For example:

-
10.
SIM card capacity: When the SIM card capacity is present in the title, it must be extracted. The most common value for this attribute is “Dual Chip”. For example:











These are the ten most relevant attributes for the Smartphone category that we found in our database. From this set, we built a small annotated sample and trained supervised named entity recognition approaches, aiming at automatically extracting attribute-value pairs from product titles for the Smartphone category as explained in the Sect. 4.
4 Experiments and Results
In this section we describe the corpus used in our experiments and the annotation process (Sect. 4.1) carried out to feed the supervised named entity recognition (NER) approaches we investigated in this work. These approaches are detailed in Sect. 4.2 and their results presented in Sect. 4.3.
It is worth mentioning that we used the source code available in the official open repositories of each specific tool applied here and that the corpus is not freely available due to the americanas s.a.’s police we worked with.
4.1 Corpus Pre-processing and Annotation
To analyze the viability of NER to extract attributes from product titles of the Smartphone category, we defined a criterion to select a subset from the original data set of around 7 million products of general categories. We removed from the data set all the products with WIT not labeled as “smartphone”, “celular” (cell phone), or “iphone”. This selection resulted in a data set of 7,432 products.
From this set, we extracted only the product titles. The titles were, then, pre-processed by performing the following tasks: (i) Conversion of the text to lowercase; (ii) Removal of special characters such as: bars, parentheses, brackets and hyphens; (iii) Tokenization by white space; (iv) Stop wordsFootnote 9 removal; and (v) Removal of duplicate titles.
Then, we removed the outliersFootnote 10 by excluding all titles that did not contain “smartphone”, “celular” or “iphone” and some possible misspelling variations (such as “smatphone”). In the end, 58 outliersFootnote 11 were removed. Most of them were battery cells, biological cells or money bills probably wrongly categorized as “celular” due to the orthographic similarity between the word “celular” (cell phone) and the words “célula” (cell) or “cédula” (bill).
The remaining 7,374 product titles were then clusterized. To start the clustering task, the tokens “smartphone”, “celular” and related spelling variants were removed from the data setFootnote 12. Then, the titles were vectorized using the TF-IDF vectorizer, using default parameter values. Using the Elbow Method, the number of clusters was set to be 16 and the Mini Batch K-Means clustering method was executed to group the product titles of the same brand, with a few deviations. The clustering was performed using scikit-learn [12].
From each cluster, 26 items were selected: 13 being the closest to the centroid and 13 being other ones randomly selected. As a result, a total of 416 product titles were selected to be annotated by two linguists. The annotation was performed using the Prodigy [3] tool. A third linguist was responsible for resolving the discrepancy cases. The percentagesFootnote 13 of agreement between the two annotators can be seen in Table 1.
The annotation of the title “Smartphone blu grand m dual sim 3g 5.0” 5mp 3.2mp prata” is illustrated in Fig. 1 using the Prodigy [3] tool. As a result, the following attributes were marked: WIT (Smartphone), brand (blue grand m), SIM card capacity (dual sim), internal memory (3g), display size (5.0”), camera quality (5mp 3.2mp) and color (prata).

Annotation example using the annotation tool prodigy [3]
As Table 1 makes evident, WIT was the attribute with the highest agreement, being labeled equally in 386 of the 414 instances. On the other hand, Processor, Model and Display size were the attributes with the highest disagreement between annotators, with about 73% to 76% of the instances annotated equally.
4.2 Experimental Setup
In this section, we describe the tools for NER investigated in this work: BERT and MITIE. BERT is a recent approach which has achieved significant results in many NLP tasks [6]. MITIE, in turn, is an earlier well-known and widely used tool for NER and binary relation extraction. While the former is a neural network based approach, which relies on contextualized word vectors, the latter applies traditional machine learning algorithms and static word embeddings to identify named entities.
BERT. (Bidirectional Encoder Representations from Transformers) [6] is a neural approach which outputs deep contextualized language representations derived from unlabeled text. Although training a big BERT model from scratch can be too computationally expensive, pre-trained BERT models can be fine-tuned to several NLP tasks without substantial task-specific architecture modifications.
Some freely available, pre-trained BERT models are: (i) the BERT-base Multilingual CasedFootnote 14, which is a pre-trained model for 104 languages including Portuguese; and (ii) BERTimbau-BaseFootnote 15 [16], which was trained with the Brazilian Portuguese corpus brWaC [17], widely used in open-source projects.
Besides BERTimbau-Base, some pre-trained models are also available for NER [15], which use BERTimbau-Base as a start point and were optimized for NER using HAREMFootnote 16 dataset. Two approaches were applied for NER by the BERTimbau authors: the feature-based and the fine-tuning.
In the feature-based approach, a pre-trained model is used as a starting point, but the weights for the BERT’s network layers did not change. A Long Short Term Memory (LSTM) layer, when possibly combined with a Conditional Random Fields (CRF) layer, is trained and used to classify the sentences.Footnote 17 In the fine-tuning approach, a pre-trained model is also used as a starting point, but its weights are adjusted during the training to achieve better results for NER. Following the fine-tuning approach, it is possible to add a CRF layer at the end of the network to help with sentence classification.
In this work we fine-tuned two models for NER in our dataset: one fine-tuning only with BERTimbau-Base (BERTimbau) and another one starting from the BERTimbau-Base trained for NER with HAREM dataset and also adding a CRF layer (BERTimbau-HAREM).Footnote 18
To evaluate the robustness of these methods to random variations, two random seeds (seed1 and seed2) were extracted from the data set for generating training (50%), validation (25%) and test (25%) partitions. In total, 4 models were trained using the BERT approach: BERTimbau in seed1, BERTimbau in seed2, BERTimbau-HAREM in seed1 and BERTimbau-HAREM in seed2. For both pre-trained BERT models, the hyperparameters used were the default values.
MITIE. (MIT Information Extraction) frameworkFootnote 19 [9] was designed to be a simple, easy and intuitive tool with no parameters. The current version of MITIE includes tools for performing NER, binary relationship extraction, as well as tools for training custom models.
The MITIE NER model uses the WordRep benchmark for building word representations (word embeddings), word morphology and traditional machine learning algorithms such as Structural Support Vector Machines [8]. MITIE comes with some previously generated word embeddings for English, Spanish and German. In our experiments we generated new word embeddings, using WordRep, which is publicly available in the MITIE repository [2]. We used a dataset containing around 7 thousand titles from the Smartphone category. This word representation was called celular.
The same seeds (seed1 and seed2) used for training BERT NER models were also used for training MITIE NER models with one difference: MITIE does not explicitly use a validation set. Thus, the seeds were divided only into training and test, following the proportion of 75% for training and 25% for testing. In this way, the training instances of MITIE correspond to the training and the validation instances used by BERT, and the test cases are the same for both models.
In addition to the celular word representation created in this work, existing ones for English (English) and Spanish (Spanish) available with MITIE were also used. We also generated a huge word representation from 7.5 million titles for products from diverse categories (not only Smarthphone). This representation was called all. Finally, we also generated two versions of the celular word representation removing the titles from seed1 (cel-seed1) and seed2 (cel-seed2). Ergo, ten different models were trained in total using these 6 word representations.
4.3 Results
In this section we present the results for BERT and MITIE separately, then a comparison of both approaches will be made in the next section by drawing some conclusions about their performances on solving the investigated problem.
BERT Results. As described in Sect. 4.2, two BERT models were fine-tuned for NER (attribute extraction) in product titles: the original BERTimbau (BERTimbau) and the BERTimbau trained for NER with the HAREM dataset and a CRF layer (BERTimbau-HAREM).
Table 2 shows that the BERT models present F1 scores of around 94–95%, proving to be very robust independently of the random seed, indicating the absence of overfitting.
It is interesting to notice that, although by a little difference, the model fine-tuned from the BERTimbau-Base performed better than the one fine-tuned from a version trained for NER in HAREM dataset.
Table 3 provides the detailed results for the best scenario: the BERTimbau model in the test set of seed2. The “support” column indicates the amount of evaluated instances in each class. The classes with the worst F1 scores were Model and Processor. The former one, probably due to labelling errors for the boundaries of the entity and the latter one maybe due to the small amount of training instances (less than 40).
MITIE Results. As described in Sect. 4.2, ten MITIE models were trained using 6 different word representations: English, Spanish, all, celular, cel/seed1 and cel/seed2. Table 4 shows the F1 scores for these models.
From F1 scores we can see, again, that the values obtained for seed1 and seed2 are very close – again around 94–95%. Regarding the wordreps (word embeddings), the English and celular were the ones with best results and removing the titles from seed1 or seed2 did not significantly impact the results. Thus, it is possible to conclude that having the titles used in training for the generation of the word representations did not significantly bias the model. Therefore, the model trained with celular for seed2 was the one chosen for further analysis.
In order to do that, Table 5 presents the detailed results for the evaluation of the MITIE model trained with celular and seed2 in the test set. It can be noticed that, as happened with the BERT models, the MITIE model also performed poorly in the Model class. Again, we believe that this is due to entity labelling errors.
Example. To finish our results and discussion section, Table 6 shows the MITIE’s predictions output by the model trained with celular and seed2 for the three product titles:
-
1.
smartphone samsung galaxy j6, 32 GB, dual chip, android, tela 5.6 pol, octa core, 4g, 13mp, tv prat;
-
2.
iphone 7 apple, ouro rosa, tela 4.7\(^{\prime \prime }\), 4g+wifi, ios 11, 12mp, 32 GB;
-
3.
celular up 3 chip quad cam mp3 4 fm preto cinza p3274 multilaser
The only differences between BERT and MITIE’s outputs for these examples were: for title 1, BERT did not output a value for Color attribute; for title 2, in the Internal Memory, the only output of BERT was “32 GB” and the “ios 11” was tagged as Operating system. For title 3, “quad” token was tagged as Brand, the Display size attribute was left empty, and the Model attribute values were “up” and “p3274”.
4.4 Comparison Between the Models
Figure 2 shows a graph of F1 scores for the best BERT (BERTimbau in seed2) and MITIE (trained with celular and seed2) models.

Comparison of F1 scores for the best models (BERTimbau and MITIE trained with celular) trained with seed2 in the test set
As we can see from Fig. 2, the performances are very close with little highlights to: BERTimbau in Color class and MITIE celular in Processor class. In fact, it is worth highlighting the good performance of the MITIE model in the Processor class, which has only less than 40 training instances.
Regarding the training time, we can point out that , when using the CPU, both MITIE and BERT took a considerable amount of time, however MITIE was still faster than BERT. BERT took around 7 h against 5 h from MITIE to train each model. However, the BERT training can be speed up using GPUs as accelerators: with a median GPU, the fine-tuning of BERTimbau took only 28 min.
Regarding the prediction latency (that is, the time for inferring new entities), the BERTimbau model took 97 min and 15 s to infer all the entities in the dataset containing 7,374 titles running (only on CPU) in a machine with a Intel(R) Xeon(R) Silver 4210 CPU @ 2.20 GHz processor and 40 cores. Using a GPU Gigabyte NVIDIA GeForce RTX 2060 Windforce OC (6 GB), the time needed to finish all inferences decreased considerably: the model took only 11 min e 52 s to complete the inference for the same set of 7,374 instances.
On the other hand, for the same dataset and the same CPU machine, the MITIE model trained with celular and seed2 took approximately 3.64 s to make all the inferences, showing an extremely better throughput when compared to BERT model. This mean 4 s from MITIE \(\times \) 11 min from BERT. So, MITIE offers not only accuracy, but also efficiency as had already been pointed out as one of its great advantages by its developers.
Regarding the size of the model when stored on disk, BERT uses an average of 1.3 GB to store the model as a whole. For MITIE, the storage size of the model varies a lot and it is directly proportional to the size of the word representation used. For English, Spanish and all the model sizes are around 338 MB, for celular, cel-seed1 and cel-seed2, the final size of the models is about 29 MB. In light of that, the MITIE model wins again when the size of the model is considered.
In general, both BERT and MITIE models achieved satisfactory results on the pursued task. The difference in F1 score between these methods is not significant. However, a few points need to be considered. First, MITIE performs better where BERT achieved the worst scores. Specifically in the processor and model classes. In the classes where BERT performs slightly better than MITIE, the differences are minor, and the scores obtained by MITIE were considered adequate. Moreover, the computational resources required by MITIE are notably lower than those demanded by BERT. Considering these points and, particularly, the fact that the prediction latency is crucial for the application, we considered the MITIE model trained on celular and seed2 as the most appropriate to generate the standardization dictionary that will give rise to search filters for the Smartphone category.
5 Final Remarks
This paper addressed the problem of attribute-value extraction from product titles of the Smartphone category in Brazilian Portuguese. By automating this process, the e-commerce companies are able to have a unified treatment to their product assortment, improving query matching, product recommendation and the use of facets to enhance product discoverability.
Several models were investigated in this paper based on BERT and MITIE approaches. After a careful analysis based on accuracy and efficiency, we concluded that, for our scenario, a solution based on MITIE is still more interesting than one based on pre-trained language models.
As future work, we want to investigate how scalable our approach is: would a MITIE-based model still get competitive accuracy when applied to different categories? Considering a sparsely annotated data scenario, which approach would be quick to deploy, keeping high-quality predictions? All in all, a question that remains is, across the 35MI products americanas s.a. sells now, will a classical machine learning approach still be competitive with deep learning approaches?
Notes
- 1.
- 2.
In English: Samsung Galaxy A01 Smartphone, 32 GB, 2 GB RAM, 5.7\(^{\prime \prime }\) Infinite Screen, 13MP Dual Rear Camera (Main) + 2MP (Depth), 5MP Front, 3000 mAh Battery, Dual Chip, Android - Blue.
- 3.
In English: Moto G9 Play 64 GB Smartphone Dual Chip Android 10 Screen 6.5\(^{\prime \prime }\) Qualcomm Snapdragon 4G Camera 48MP+2MP+2MP - Turquoise Green.
- 4.
In English: iPhone SE 128 GB Black iOS 4G Wi-Fi Screen 4.7\(^{\prime \prime }\) 12MP + 7MP Camera - Apple.
- 5.
WIT stands for “What Is This” and is used to define the product being sold.
- 6.
The Smartphone category encompasses cell phones, smartphones and iPhones sold by the largest Brazilian e-commerce marketplace, B2W Digital.
- 7.
- 8.
In this paper, the tags associated with the attributes are presented between brackets and the values associated to them, in bold.
- 9.
Stop words list in Portuguese: de, a, o, que, e, do, da, em, os, no, na, por, as, dos, ao, das, á, ou, ás, com.
- 10.
Outliers refers to those product titles that do not belong to the Smartphone category.
- 11.
Examples of removed outliers, in Portuguese: “célula vegetal ampliada aproximadamente 20 mil vezes”, “celula carga 10 kg sensor peso arduino” and “cédula foleada ouro 100 euros coleção notas moedas euro”.
- 12.
We didn’t remove the token“iphone” and its spelling variations since the format of iPhone titles is very different from the other items in the data set and the experiments removing “iphone” led to results worse than those not removing it.
- 13.
- 14.
- 15.
- 16.
- 17.
From previous experiments, we concluded that the feature-based models as well as the ones trained with the multilingual BERT did not reach results as good as the fine-tuned models trained with BERTimbau-Base, so these options are not described here.
- 18.
These two configurations were the ones which achieved the best results in previous experiments with product tiles from Fashion category.
- 19.
References
HAREM linguateca datasets. https://www.linguateca.pt/HAREM/. Accessed 08 Jan 2021
Repositório oficial - MITIE. https://github.com/mit-nlp/MITIE
Prodigy: An annotation tool for AI, machine learning, and NLP (2017). https://prodi.gy. Accessed 08 Jan 2021
Cheng, X., Bowden, M., Bhange, B.R., Goyal, P., Packer, T., Javed, F.: An end-to-end solution for named entity recognition in ecommerce search. arXiv preprint arXiv:2012.07553 (2020)
Deleger, L., et al.: Building gold standard corpora for medical natural language processing tasks. In: AMIA Annual Symposium Proceedings (2012)
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: pre-training of deep bidirectional transformers for language understanding. In: Conference of the North American Chapter of the Association for Computational Linguistics, pp. 4171–4186 (2019)
Geyer, K., Greenfield, K., Mensch, A.C., Simek, O.: Named entity recognition in 140 characters or less (2016)
Joachims, T., Finley, T., Yu, C.J.: Cutting-plane training of structural SVMs. Mach. Learn. 77, 27–59 (2009)
King, D.E.: Dlib-ml: a machine learning toolkit. J. Mach. Learn. Res. 10, 1755–1758 (2009)
Mikolov, T., Sutskever, I., Chen, K., Corrado, G.S., Dean, J.: Distributed representations of words and phrases and their compositionality. In: Burges, C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K. (eds.) Advances in Neural Information Processing Systems 26, pp. 3111–3119 (2013)
More, A.: Attribute extraction from product titles in ecommerce. In: Workshop on Enterprise Intelligence - ACM SIGKDD Conference on Knowledge Discovery and Data Mining (2016)
Pedregosa, F., et al.: Scikit-learn: machine learning in Python. J. Mach. Learn. Res. 12, 2825–2830 (2011)
Pennington, J., Socher, R., Manning, C.D.: GloVe: global vectors for word representation. In: Empirical Methods in Natural Language Processing, vol. 14, pp. 1532–1543 (2014)
Real, L., Johansson, K., Mendes, J., Lopes, B., Oshiro, M.: Generating e-commerce product titles in Portuguese. In: Anais do XLVIII Seminário Integrado de Software e Hardware, pp. 299–304. SBC, Porto Alegre, RS, Brasil (2021). https://doi.org/10.5753/semish.2021.15835. https://sol.sbc.org.br/index.php/semish/article/view/15835
Souza, F., Nogueira, R., Lotufo, R.: Portuguese named entity recognition using BERT-CRF. arXiv preprint arXiv:1909.10649 (2019). http://arxiv.org/abs/1909.10649
Souza, F., Nogueira, R., Lotufo, R.: BERTimbau: pretrained BERT models for Brazilian Portuguese. In: 9th Brazilian Conference on Intelligent Systems, BRACIS, Rio Grande do Sul, Brazil, October 20–23 (2020)
Wagner, J., Wilkens, R., Idiart, M., Villavicencio, A.: The brWaC corpus: a new open resource for Brazilian Portuguese. In: International Conference on Language Resources and Evaluation, pp. 4339–4344 (2018)
Xu, H., Wang, W., Mao, X., Jiang, X., Lan, M.: Scaling up open tagging from tens to thousands: comprehension empowered attribute value extraction from product title. In: Annual Meeting of the Association for Computational Linguistics, pp. 5214–5223 (2019). https://doi.org/10.18653/v1/P19-1514
Acknowledgment
This paper and the research behind it would not have been possible without the support of americanas s.a. Digital Lab, specially José Pizani, Ester Campos and Thiago Gouveia Nunes, who closely followed this research. This work is part of the project “Dos dados ao conhecimento: extração e representação de informação no domínio do e-commerce” (Projeto de extensão - UFSCar #23112.000186/2020-97).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Silva, D.F. et al. (2021). Named Entity Recognition for Brazilian Portuguese Product Titles. In: Britto, A., Valdivia Delgado, K. (eds) Intelligent Systems. BRACIS 2021. Lecture Notes in Computer Science(), vol 13074. Springer, Cham. https://doi.org/10.1007/978-3-030-91699-2_36
Download citation
DOI: https://doi.org/10.1007/978-3-030-91699-2_36
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-91698-5
Online ISBN: 978-3-030-91699-2
eBook Packages: Computer ScienceComputer Science (R0)