
Abstract
In this paper, we present a new corpus for Rhetorical Role Identification in Portuguese legal documents. The corpus comprises petitions from 70 civil lawsuits filed in TJMS court and was manually labeled with rhetorical roles specifically tailored for petitions. Since petition documents are created without a standard structure, we had to deal with several issues to clean the extracted textual content. We assessed classic and deep learning machine learning methods on the proposed corpus. The best performing method obtained an F-score of 80.50. At the best of our knowledge, this is the first work to deal with rhetorical role identification for petitions, given that previous works focused only on judicial decisions. Additionally, it is also the first work to tackle this task for the Portuguese language. The proposed corpus, as well as the proposed rhetorical roles, can foster new research in the judicial area and also lead to new solutions to improve the flow of Brazilian court houses.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others

1 Introduction
Brazilian judicial system has usually adopted a conservative stance regarding its lawsuit bureaucracy. However, in the last two decades, it started to adopt information technology systems to improve its underlying procedures. In 2006, Brazilian Congress passed a lawFootnote 1 to rule electronic lawsuit systems. Since then, all Brazilian courts started to digitize their lawsuit bureaucracy. This process has greatly accelerated the filing and intermediary procedures of a lawsuit which, for instance, allowed a 22% increase in the number of cases filed in 2019 when compared to 2009 [18]. Although this effect is mostly beneficial, it presents its own challenges. One issue is that the main bottleneck of Brazilian judicial system has shifted from the intermediary procedures performed by civil registries to judges’ offices.
Nowadays, most documents in a lawsuit in Brazil are either originally digital or digitized before inclusion in the judicial system. Nevertheless, several tasks within a lawsuit procedure still depend on direct human intervention. In general, every time a party (judge, complainant, defendant, etc.) is requested to pronounce within a case, this party may need to carefully analyse different documents. In particular, the petition (petição inicial, in Portuguese) is the first document presented by the complainant in order to file a civil lawsuit in Brazilian courts. In this document, the complainant needs to identify the involved parties, expose facts that are relevant to the case, present the legal basis and relevant prior cases, describe the requested remedy, among other aspects. After a petition is filed, it needs to be carefully analysed by staff of a judge’s office in order to verify different aspects. For instance, it is necessary to check if the petition presents the minimal requirements specified in the Brazilian civil procedure (Código de Processo Civil) [4]. Ultimately, the petition must be fully considered by the assigned judge, when another careful analysis is required. Although it is virtually impossible to mechanize all these manual analytic steps, in most of these cases if not all, machine learning (ML) and natural language processing (NLP) techniques can be leveraged to assist humans in such analyses.
Rhetorical role identification (RRI) is an NLP task that consists of labeling the sentences of a document according to a given set of semantic functions (rhetorical roles). This task is useful to applications like document summarization [11, 19,20,21, 26], semantic search [15], document analysis [22], among others. Different approaches have been proposed to solve this task for court decisions [2, 20, 21]. These previous works have proposed to segment a court decision into rhetorical roles such as facts, court arguments, prior related cases, ruling, among others. As far as we know, all previous RRI methods have tackled only court decisions and are limited to the English language. Although the benefits of analytic tools of judicial decisions are undisputed, it is also important to provide similar tools for other legal documents and languages, particularly petitions in Brazilian legal system. As mentioned before, a judge’s office in Brazil handle a high volume of work, and petition analysis represents a substantial portion of it. Therefore, rhetorical role identification for petitions represents an opportunity to improve Brazilian judges’ offices efficiency.
In this paper, we propose to segment petitions into eight rhetorical roles by mainly considering the analytic needs of judges’ offices in Brazil. We present a corpus of 70 petitions comprising more than 10 thousand sentences manually labeled with the proposed rhetorical roles. These petitions were taken from civil lawsuits filed in the court of the Brazilian state of Mato Grosso do Sul (TJMS). Additionally, we report on experiments to assess classic and modern machine learning methods on the created corpus. In order to propose relevant rhetorical roles, we considered the Brazilian civil procedure [4] which defines the minimal requirements of a petition. The proposed rhetorical roles are: identification of parties, facts, arguments, legal basis, precedents, requests, remedy, and others. The corpus was anonymized and is publicly available. We trained and evaluated six machine learning methods, including classic and deep learning models, on the developed corpus. The best performing method was an end-to-end-trained BERT-based [6] method that obtained a sentence-level micro-averaged F-score of 80.50. This method outperformed a fixed-representation BERT-based model by five points and the best classic algorithm (SVM with TF-IDF representation) by 25 points of F-score.
As far as we know, this is the first paper to approach rhetorical role identification of petitions, instead of court decisions. Moreover, this is also the first work on this task that considers the Portuguese language and legal domain. We hope this paper will foster research about this important subject, especially in Brazil.
2 Related Work
One of the first works to deal with text segmentation based on rhetorical function was proposed by Teufel [25]. In this work, Teufel proposed a segmentation approached called argumentative zoning that is based on the rhetorical function that an excerpt plays within a scientific article. This approach was later applied to extractive summarization [5, 12, 26].
Hachey and Grover [11], inspired by Teufel’s work, proposed a method to legal text summarization based on rhetorical role text segmentation. The proposed roles were: fact, proceedings, background, framing, disposal, textual, and other. They assessed the proposed method on the HOLJ dataset [10] which consists of 40 manually-labeled decisions from the House of Lords, the highest court in the United Kingdom until 2009. They employed a C4.5 classifier that achieved an accuracy of \(65.4\%\).
Saravanam [19] also followed Teufel’s work to study the generation of headnotes (a type of summary) for decisions from Indian courts. He argued that rhetorical roles proposed by Teufel were not appropriate in the legal domain. Thus, he proposed the following rhetorical roles for legal decisions: case identification, facts, arguments, chronology, argument analysis, ratio decidendi, and final decision. Later, based on these roles, Saravanam et al. [21] created a corpus out of 200 decisions from the Indian Court of Justice spanning three different domains. They developed and evaluated a Conditional Random Field (CRF) classifier to perform sentence-level rhetorical role identification which obtained the following F-scores on the considered domains: 84.9 on rent control, 81.7 on income tax, and 78.7 on sales tax domain.
Nejadgholi et al. [15] leveraged rhetorical role identification to perform semantic search. They defined eight rhetorical roles and manually labeled the sentences in 150 decisions taken from immigration and refugee cases from Canada’s Federal and Supreme Court. They assessed a simple classifier based on fastText that obtained an accuracy of 90%.
Walker et al. [28] proposed six rhetorical roles to aid a system for argument mining. They produced a corpus of 50 decisions extracted from the U.S. Board of Veterans’ Appeals comprising 6,153 sentences. They evaluated three different classification algorithms on this sentence classification corpus. The best performing classifiers (based on logistic regression and SVM) achieved 85.7% accuracy.
Bhattacharya et al. [2] annotated 50 decisions from the Supreme Court of India using the same rhetorical roles proposed by Saravanam [19]. They trained a hierarchical BiLSTM model with CRF on this corpus, obtaining an F-score of 82.0.
Yamada et al. [29] leveraged the argumentation structure in legal decisions from Japanese justice system to improve a summarization system. They manually annotated a corpus of 209 decisions based on seven rhetorical roles. By means of BiLSTM-CRF model, they obtained a macro-averaged F-score of 65.4 on this corpus.
All papers mentioned above are based on legal decisions. Although this kind of documents is of high importance, there are other types of documents that are also relevant to different applications in the legal domain. Another aspect that is worth mentioning is that all previous works on rhetorical role identification were performed on documents from legal systems based on the common law paradigm. However, the Brazilian legal system is based on the civil law paradigm, which implies some key differences in the structure of the documents within a legal case. Therefore, it is worth studying rhetorical role identification within the Brazilian legal system.
A few previous works [7,8,9] have tackled rhetorical role identification in Portuguese. However, as far as we know, there is no RRI work for legal documents in this language. Recently, some papers have proposed resources and systems to tackle NLP problems involving Portuguese legal documents, mainly for document classification [1] and named entity recognition [13, 24]. As far as we know, our work is the first one on rhetorical role identification for Portuguese legal documents, and also the first one to perform this task on petitions regardless of language. Moreover, we propose some novel rhetorical roles that are specific for petitions.
3 Corpus and Rhetorical Roles
We created a corpus of petitions based on the court of the Brazilian State of Mato Grosso do Sul (TJMS) which receives hundreds of thousands lawsuits every year. During 2017, for example, more than 340 thousand cases have been filed in TJMS among different types such as civil, criminal, fiscal, and others. We initially considered civil cases that were judged between 2014 and 2018 and are not under judicial secrecy. We then took the petitions of such cases which are usually written by a lawyer that represents the complainant. The system used to file cases in TJMS accepts a petition only as a PDF file. However, there is no requirement as how this document is created. It can even be produced by scanning a paper document. Therefore, such documents present great variation regarding encoding, content structure, background watermark, headings, footers, among others. Since these aspects may generate a lot of noise in the content extracted from the petitions, we selected 70 petitions and, after extracting its textual content by means of PDFBoxFootnote 2, a manual inspection was performed in order to remove noisy content. We split each petition into sentences and tokens by means of the NLTK library [3]. We obtained a total of 10,784 sentences comprising 249,105 tokens (20,914 unique tokens). The average length of a petition is 154 sentences, and the average length of a sentence is 23.1 tokens. In Fig. 1, to provide a better understanding of this corpus, we present the histogram of sentence length.

Frequency of sentences per length
For all documents, personal information were manually identified and anonymized by means of random procedures. More specifically, names of people, institutions, streets and cities were replaced by random names taken from a database containing two thousand names. Personal identification numbers and telephone numbers were replaced by random numbers.
In order to define the rhetorical roles used to label sentences, we took some inspiration from the Brazilian civil procedure (Código de Processo Civil) [4]. More specifically, we considered articles 319, 320 and 321 from this law, which state the minimum requirements regarding the content of a petition within Brazilian legal system. In addition to these legal requirements, we considered two possible applications for this corpus: (i) support to staff of a judge’s office (including the judge) when analysing a filed petition; and (ii) petition summarization to support the generation of headnotes that need to be included in the judge’s pronouncement within the legal case.
In the following, we list the eight proposed rhetorical roles for sentences within a petition. The terms between parenthesis correspond to Portuguese translations of the rhetorical roles. For each rhetorical role, we also present some exemplary sentences.
-
1.
Identification (identificação das partes): Identification of the parties (complainant, appellant, judge, among others) involved in the case. Usually such sentences occur at the beginning of the document.
-
ADEMIR CANTAREIRA E PAULA, brasileiro, solteiro, auxiliar de produção, portador do CPF n\(^{\underline{\mathrm{o}}}\).
-
179.939.452 - 04 e do RG n\(^{\underline{\mathrm{o}}}\).
-
103673421 SSP/MS, residente e domiciliado sito á Rua do Carapicuibano, n\(^{\underline{\mathrm{o}}}\).
-
-
2.
Facts (fatos): Factual account that gave rise to the lawsuit. Usually these sentences occur right after the identification, but they can be presented interspersed with the arguments.
-
No dia 28/01/2013 o funcionário da Requerida, Sr. Jorge, realizou serviços de substituição de válvulas no apartamento do síndico do condomínio, Sr. Ailton Cesar, que aproveitando o ensejo contratou verbalmente o profissional para verificar os hidrômetros do prédio e, se necessário, consertar ou substituir dois registros de água do condomínio.
-
-
3.
Arguments (argumentos): Pronouncement to persuade the judge to adopt a certain line of thought. These are the sentences that present the greatest variation in linguistic styles. It is common to interconnect these sentences with facts and legal basis.
-
O presente pleito tem como objetivo, entre tantos outros, ressarcir o condomínio autor pelos danos morais, coibindo a atitude abusiva da Requerida, em razão do constrangimento sofrido pelo síndico, Sr. Leandro Musk, o qual se sente lesado porque ficou extremamente constrangido ao ter que pagar e explicar perante os condôminos do prédio um gasto exorbitante de R$ 1.660,00 para trocar apenas dois castelos de registros.
-
-
4.
Legal basis (fundamentação legal): Description of legal doctrine that gives the ground for the decision making process. It usually includes citations to laws and texts by jurisprudential authors. This is usually interspersed with the arguments and precedents, but we decided to create this specific label since its nature is more objective than arguments.
-
CC. Art. 186.
-
Aquele que, por ação ou omissão voluntária, negligência ou imprudência, violar direito e causar dano a outrem, ainda que exclusivamente moral, comete ato ilícito.
-
-
5.
Precedents (jurisprudência): This part is based on citations to headnotes of similar or relevant previous cases. Some sentences within this part are in capital letters since this is the typical format of headnotes in Brazilian legal system. It also occurs interspersed with the arguments.
-
(STJ - REsp 927727 / MG, RECURSO ESPECIAL, 2007/0038830-3, Dês.
-
Rel.
-
Ministro JOSÉ DELGADO, Primeira Turma, 06/05/2008).
-
-
6.
Requests (pedidos): This corresponds to the main requests by the complainants about which the judge must pronounce. It is usually the last by one section of the petition.
-
Ante o exposto com supedâneo nos motivos de fato e nos fundamentos do direito pátrio, requer a Vossa Excelência se digne de.
-
a) citar a Ré, na pessoa de seu representante legal, para que, assim desejando, compareça á audiência designada e apresente defesa, sob pena de revelia e confissão (art.
-
-
7.
Remedy (valor da causa): Normally contained in one or two sentences in the end of the petition, this part provides a monetary estimate to remedy the complainant’s claims. This is usually the last section of the petition.
-
Dá-se á presente o valor de R$ 4.450,00 (quatro mil quatrocentos e cinquenta reais), para fins de alçada e fiscais.
-
-
8.
Others (outros): Other textual elements like section and page headings.
-
DOS REQUERIMENTOS.
-
DO DIREITO.
-
In Table 1, we present the number of sentences and the average number of tokens per sentence for each rhetorical role in our corpus. In the first column of this table, we provide a label for each rhetorical role to ease further references.
By means of the doccano tool [14], an expert labeled each sentence of a petition with one of the eight rhetorical roles aforementioned. The sequence of sentences in a petition was preserved in the corpus, so that future approaches can leverage this structure.
4 Text Representation and Machine Learning Approaches
Rhetorical role identification is usually modeled as a sentence classification task. Following this modeling, there are two broad types of methods in literature: the ones that treat each sentence independently, and the ones that treat a document as a sequence of sentences leveraging the inter-dependencies among sentences. Although the later type considers a relevant piece of information that is ignored by the former, in this work we focus only on the former type of methods. Our motivation for this decision is that our main goal here is to investigate the feasibility of the proposed RRI task. And we indeed experimentally show that, even ignoring the sequential aspect of the given sentences, it is possible to achieve a highly effective rhetorical role classifier (F-score over 80%) for sentences within petitions from a Brazilian court. Besides that, we also make progress on assessing different text representations and machine learning algorithms on this task.
4.1 Baseline Methods
We considered some standard text classification approaches as baseline methods. More specifically, we combined Naive Bayes (NB) and Support Vector Machine (SVM) models with two standard text representation techniques, namely bag of words (BoW) and term frequency-inverse document frequency (TFIDF). BoW and TFIDF are among the most used text representation techniques. Although deep learning representations have dominated the latest advances in text processing tasks, BoW and TFIDF can still be competitive, mainly in text classification problems. Thus, these classic representations represent strong baselines in order to evaluate the incremental contribution of more complex methods, like the ones based on deep learning.
NB is a probabilistic ML model specially appropriate for text classification tasks. While linear SVM is an effective model to tackle problems with sparse input data like texts. Both models offer competitive performance in many text classification problems.
4.2 Deep Learning Methods
In the last decade, deep learning models have represented the most prominent approaches for NLP problems. And, following the proposal of the seminal Transformer architecture [27], models based on attention mechanisms [6, 16, 17] became the standard approach for text tasks. BERT [6] is probably the most popular model among such approaches. For instance, among the more than 10 thousand NLP models available in the popular Hugging Face libraryFootnote 3, approximately 25% are based on BERT or some of its variants. Among those BERT-based models, there are 18 models were trained with Portuguese data.
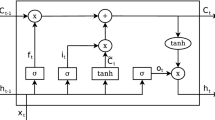
In this work, we assessed two BERT-based models for rhetorical role identification by training and evaluating them on our proposed corpus. Both models are based on the BERTimbau Base model [23], a BERT language model pre-trained on Portuguese texts which is available in the Hugging Face libraryFootnote 4. In Fig. 2, we depict these two models. Both of them employ a BERT language model (LM) to compute a sentence representation (black part of the figure). This part, which is the same for both models, is represented in black at the bottom of the figure. Before applying a BERT LM, the input sentence is first tokenized into N tokens \((T_1, \ldots , T_N)\), then two special tokens [CLS] and [SEP] are added, respectively, at the beginning and in the end of the tokenized sentence. The resulting sequence of tokens ([CLS], \(T_1, \ldots , T_N\), [SEP]) is then fed in the language model, which outputs a 768-dimensional representation for each input token: \((E_\mathrm {[CLS]}, E_{T_1}, \ldots , E_{T_N}, E_\mathrm {[SEP]})\). When dealing with sentence classification tasks, like is the case for rhetorical role identification, one needs to compute a fixed-length representation for the variable-length input sentence. In this work, we use a common sentence representation approach which consists of simply taking \(E_\mathrm {[CLS]}\), thus ignoring the representations of all remaining tokens. Since BERT is composed of a sequence of self-attention layers, the output \(E_\mathrm {[CLS]}\) is directly connected to all tokens of the sentence. Therefore, this representation is robust for sentence classification tasks, regardless of which part of the input sentence is more important for the task at hand.

Two BERT-based models for sentence classification. Black: BERT language model computes a sentence representation \(E_\mathrm {[CLS]}\). This part is identical in both models, except that, for the model on the left, the BERT LM is fine tuned during supervised training. On the other hand, for the model on the right, the BERT LM is kept fixed and only the remaining layers are updated during supervised training. Blue: The BERT-based sentence representation \(E_\mathrm {[CLS]}\) is fed to a single linear layer followed by a softmax function that outputs a probability distribution over the eight labels. This model is trained in an end-to-end fashion, i.e., the BERT model is fine-tuned together with the linear layer. Red: The sentence representation is fed to a MLP comprising two 512-neuron layers followed by a softmax function which outputs the label distribution. When training this model, the BERT LM is kept fixed and only the MLP parameters are updated. (Color figure online)
In the upper part of Fig. 2, we present the remaining layers of the two sentence classification models used in our work. In blue (upper-left of the figure), we represent the model that takes the BERT-based sentence representation \(E_\mathrm {[CLS]}\), passes it through a linear layer and then applies a softmax activation function which outputs a probability distribution over the eight rhetorical roles proposed in our work. This corresponds to the original BERT architecture for text classification problems. This model is trained in an end-to-end fashion, i.e., during supervised training the parameters of both the output linear layer and the BERT language model are jointly learned. This approach performs the so called LM fine tuning because the BERT LM parameters are updated using labeled data for the final task.
The red part of Fig. 2 represents a model that feeds the BERT-based sentence representation \(E_\mathrm {[CLS]}\) to a two-layer Multi-Layer Perceptron (MLP). The output of this MLP is then passed to a softmax function that provides the output label distribution. When training this model, we keep fixed the parameters of the BERT language model. In that way, we can evaluate the benefit of fine tuning the BERT LM in the rhetorical role identification task.
5 Experimental Evaluation
In this section, we describe the experimental evaluation of the developed ML models on the proposed RRI corpus. We model RRI as a sentence classification problem. In order to perform model selection and still report meaningful performance estimates, we randomly split the proposed corpus into three splits: train containing 6, 901 sentences, validation containing 1, 726 sentences, and test containing 2, 157 sentences.
We use Naive Bayes and SVM models, combined with bag of words and TFIDF representations, to define meaningful baselines for this task. In these approaches, each sentence was preprocessed with NLTKFootnote 5, the Natural Language Toolkit, to tokenize and remove stopwords.We represent input sentences using BoW and TFIDF representations by means of the scikit-learn libraryFootnote 6. Then, we train and evaluate NB and SVM models using both input representations, again making use of scikit-learn. The performances of these four baseline methods on our test set are reported in Table 2. We can observe that the best performing baseline method is SVM with TFIDF representation which obtains a F-score of 60.66. But this method is only slightly better than NB with the same representation.
We also evaluated the four NB/SVM-based models when the input comprised all words (including stopwords), but the achieved results were substantially worse (F-score values were 5% lower on average). Thus, we do not report these performances.
In order to train and evaluate the two BERT-based methods, we did not employ any preprocessing steps but the corresponding tokenization. By means of the Hugging Face (HF) library, we trained and evaluated the end-to-end-trained BERT-based model. For the MLP-based classifier, we again employed the HF library to extract sentence representations, but then we used the Keras library to train the MLP model, since the BERT LM is kept fixed. In Table 2, we refer to this fixed BERT LM as BERT\(^f\). The MLP network comprises two hidden layers with 512 neurons each. This network was trained by the NAdam optimizer for 500 epochs using a batch size of 32 sentences and the categorical cross-entropy loss. The original (end-to-end) model was trained by the default HF AdamW optimizer for 10 epochs using a batch size of 4 sentences. From the results in Table 2, we can observe that fine-tuning the BERT LM brings a 5 point increase in F-score. The best performing method achieved an F-score of 80.50, which is almost 20 points higher than the performance achieved by the best baseline method.
In Table 2, we also report per-class F-scores. Untypically, the class with best results is Remedy, which is the least frequent class. Although there are only 71 sentences labeled as Remedy in the whole corpus (including the three splits), such sentences have a very specific vocabulary (“Dá-se o valor da causa ...”, for instance). This characteristic obviously facilitates the identification of these sentences. Besides that, we also observe that some frequent classes – namely Facts (2), Arguments (3), and Legal Basis (4) – present the worst performances.
In order to investigate this fact, we present the confusion matrix for our best model predictions in Fig. 3. First, we can see that there are 73 sentences labeled as Facts (Fac) but classified by the model as Arguments (Arg). And other 73 sentences labeled as Arguments (Arg) but classified as Facts (Fac). We also see that there are 181 sentences labeled as Arguments (Arg), Legal Basis (LB) or Precedents (Pre) that are misclassified among these same three classes. As mentioned in Sect. 3, sentences from these four roles (Fac, Arg, LB and Pre) are frequently interspersed among them. Thus, these interspersed sentences are probably more difficult to classify.

Confusion matrix
6 Conclusions and Future Work
In this paper, we present a new corpus comprising 70 petitions (petiÇão inicial) from civil lawsuits filed in TJMS. Based on the Brazilian civil procedure, we proposed eight categories representing the rhetorical roles of text sentences within the petitions. We manually labeled the sentences of the proposed corpus using these eight categories. Since TJMS does not require any specific structure for the digital files of petitions, we had to deal with several issues to extract the textual content from these files. As far we know, this is the first work to consider rhetorical role identification of petitions in Portuguese language. The proposed corpus is availableFootnote 7 and we hope that it can foster research on this important subject.
We also analysed the performance of classic and deep learning machine learn methods on the proposed Rhetorical Role Identification corpus. The best performing method was an end-to-end-trained BERT-based sentence classifier. This model achieved 80.50 of F-score on our test set.
As future work, we intend to pre-train a BERT language model on judicial documents. The models evaluated in this work classify sentences independently, i.e. disregarding the sequence of sentences within a petition. Thus, we also intend to improve the obtained classification performance by employing deep learning models that consider the sequential structure of sentences. Nevertheless, the obtained results are promising. Therefore, we are working on the development of a new corpus for summarization of petitions, which will leverage the rhetorical role labels in the proposed corpus.
As we have stated, the contributions of this paper can open new research possibilities for judicial NLP. Additionally, our work can lead to solutions with potential to relieve the current bottleneck in Brazilian judges’ offices.
References
de Araujo, P.H.L., de Campos, T.E., Braz, F.A., da Silva, N.C.: VICTOR: a dataset for Brazilian legal documents classification. In: Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, pp. 1449–1458. European Language Resources Association (May 2020). https://www.aclweb.org/anthology/2020.lrec-1.181
Bhattacharya, P., Paul, S., Ghosh, K., Ghosh, S., Wyner, A.: Identification of rhetorical roles of sentences in Indian legal judgments. CoRR abs/1911.05405 (2019). http://arxiv.org/abs/1911.05405
Bird, S., Loper, E., Klein, E.: Natural Language Processing with Python. O’Reilly Media Inc. (2009)
Brasil: Lei n. 13.105 de 16 de março de 2015 (Código de Processo Civil)
Contractor, D., Guo, Y., Korhonen, A.: Using argumentative zones for extractive summarization of scientific articles. In: Proceedings of COLING 2012, Mumbai, India, pp. 663–678. The COLING 2012 Organizing Committee (December 2012). https://www.aclweb.org/anthology/C12-1041
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, Minnesota, pp. 4171–4186. Association for Computational Linguistics (June 2019). https://doi.org/10.18653/v1/N19-1423. https://www.aclweb.org/anthology/N19-1423
Feltrim, V.D., Aluísio, S.M., Nunes, M.G.V.: Analysis of the rhetorical structure of computer science abstracts in Portuguese. In: Corpus Linguistics (2003)
Feltrim, V.D., Nunes, M.G.V., Aluísio, S.M.: Um corpus de textos científicos em português para a análise da estrutura esquemática (2001)
Feltrim, V.D., Teufel, S., das Nunes, M.G.V., Aluísio, S.M.: Argumentative zoning applied to critiquing novices’ scientific abstracts. In: Shanahan, J.G., Qu, Y., Wiebe, J. (eds.) Computing Attitude and Affect in Text: Theory and Applications. The Information Retrieval Series, vol. 20. Springer, Dordrecht (2006). https://doi.org/10.1007/1-4020-4102-0_18
Grover, C., Hachey, B., Hughson, I.: The HOLJ corpus: supporting summarisation of legal texts. In: Proceedings of the 5th International Workshop on Linguistically Interpreted Corpora, Geneva, Switzerland, pp. 47–54. COLING, 29 August 2004. https://www.aclweb.org/anthology/W04-1907
Hachey, B., Grover, C.: A rhetorical status classifier for legal text summarisation. In: Text Summarization Branches Out, Barcelona, Spain, pp. 35–42. Association for Computational Linguistics (July 2004). https://www.aclweb.org/anthology/W04-1007
Liu, H.: Automatic argumentative-zoning using word2vec. CoRR abs/1703.10152 (2017). http://arxiv.org/abs/1703.10152
Luz de Araujo, P.H., de Campos, T.E., de Oliveira, R.R.R., Stauffer, M., Couto, S., Bermejo, P.: LeNER-Br: a dataset for named entity recognition in Brazilian legal text. In: Villavicencio, A., Moreira, V., Abad, A., Caseli, H., Gamallo, P., Ramisch, C., Gonçalo Oliveira, H., Paetzold, G.H. (eds.) PROPOR 2018. LNCS (LNAI), vol. 11122, pp. 313–323. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-99722-3_32
Nakayama, H., Kubo, T., Kamura, J., Taniguchi, Y., Liang, X.: doccano: text annotation tool for human (2018). Software available from https://github.com/doccano/doccano
Nejadgholi, I., Bougueng, R., Witherspoon, S.: A semi-supervised training method for semantic search of legal facts in Canadian immigration cases. In: Wyner, A.Z., Casini, G. (eds.) The 30th Annual Conference on Legal Knowledge and Information Systems, JURIX 2017. Frontiers in Artificial Intelligence and Applications, Luxembourg, 13–15 December 2017, vol. 302, pp. 125–134. IOS Press (2017). https://doi.org/10.3233/978-1-61499-838-9-125
Radford, A., Narasimhan, K., Salimans, T., Sutskever, I.: Improving language understanding by generative pre-training. OpenAI (2018)
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I.: Language models are unsupervised multitask learners. OpenAI (2019)
Rotta, M.J.R., Vieira, P., Rover, A.J., Sewald, E., Jr.: Aceleração processual e o processo judicial digital: Um estudo comparativo de tempos de tramitação em tribunais de justiça. Democracia Digital e Governo Eletrônico 1(8), 125–154 (2013)
Saravanan, M.: Ontology-based retrieval and automatic summarization of legal judgments. Ph.D. thesis, Indian Institute of Technology Madras (2008)
Saravanan, M., Ravindran, B.: Identification of rhetorical roles for segmentation and summarization of a legal judgment. Artif. Intel. Law 18(1), 45–76 (2010)
Saravanan, M., Ravindran, B., Raman, S.: Automatic identification of rhetorical roles using conditional random fields for legal document summarization. In: Proceedings of the 3rd International Joint Conference on Natural Language Processing: Volume-I (2008). https://www.aclweb.org/anthology/I08-1063
Savelka, J., Ashley, K.D.: Segmenting U.S. court decisions into functional and issue specific parts. In: Palmirani, M. (ed.) The 31st Annual Conference on Legal Knowledge and Information Systems, JURIX 2018. Frontiers in Artificial Intelligence and Applications, Groningen, The Netherlands, 12–14 December 2018, vol. 313, pp. 111–120. IOS Press (2018). https://doi.org/10.3233/978-1-61499-935-5-111
Souza, F., Nogueira, R., Lotufo, R.: BERTimbau: pretrained BERT models for Brazilian Portuguese. In: 9th Brazilian Conference on Intelligent Systems, BRACIS, Rio Grande do Sul, Brazil, 20–23 October (2020, to appear)
Souza, F., Nogueira, R.F., de Alencar Lotufo, R.: Portuguese named entity recognition using BERT-CRF. CoRR abs/1909.10649 (2019). http://arxiv.org/abs/1909.10649
Teufel, S.: Argumentative zoning: information extraction from scientific text. Ph.D. thesis, University of Edinburgh (1999). http://www.cl.cam.ac.uk/users/sht25/az.html
Teufel, S., Moens, M.: Sentence extraction and rhetorical classification for flexible abstracts. In: Intelligent Text Summarization, pp. 16–25 (1998)
Vaswani, A., et al.: Attention is all you need. In: Guyon, I., et al. (eds.) Advances in Neural Information Processing Systems, vol. 30. Curran Associates, Inc. (2017). https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
Walker, V.R., Pillaipakkamnatt, K., Davidson, A.M., Linares, M., Pesce, D.J.: Automatic classification of rhetorical roles for sentences: comparing rule-based scripts with machine learning. In: Ashley, K.D., et al. (eds.) Proceedings of the 3rd Workshop on Automated Semantic Analysis of Information in Legal Texts co-located with the 17th International Conference on Artificial Intelligence and Law, ICAIL 2019, Montreal, QC, Canada, 21 June 2019. CEUR Workshop Proceedings, vol. 2385. CEUR-WS.org (2019). http://ceur-ws.org/Vol-2385/paper1.pdf
Yamada, H., Teufel, S., Tokunaga, T.: Neural network based rhetorical status classification for japanese judgment documents. In: Araszkiewicz, M., Rodríguez-Doncel, V. (eds.) The 32nd Annual Conference on Legal Knowledge and Information Systems, JURIX 2019. Frontiers in Artificial Intelligence and Applications, Madrid, Spain, 11–13 December 2019, vol. 322, pp. 133–142. IOS Press (2019). https://doi.org/10.3233/FAIA190314
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Aragy, R., Fernandes, E.R., Caceres, E.N. (2021). Rhetorical Role Identification for Portuguese Legal Documents. In: Britto, A., Valdivia Delgado, K. (eds) Intelligent Systems. BRACIS 2021. Lecture Notes in Computer Science(), vol 13074. Springer, Cham. https://doi.org/10.1007/978-3-030-91699-2_38
Download citation
DOI: https://doi.org/10.1007/978-3-030-91699-2_38
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-91698-5
Online ISBN: 978-3-030-91699-2
eBook Packages: Computer ScienceComputer Science (R0)