
Abstract
Data collection in many engineering fields involves multivariate time series gathered from a sensor network. These sensors often display differing sampling rates, missing data, and various irregularities. To manage these issues, complex preprocessing mechanisms are required, which become coupled with any statistical model trained with the transformed data. Modeling the motion of seabed-anchored floating platforms from measurements is a typical example for that. We propose and analyze a model that uses both recurrent and graph neural networks to handle irregularly sampled multivariate time series, while maintaining low computational cost. In this model, each time series is represented as a node in a heterogeneous graph, where edges depict the relationships between each measured variable. The time series are encoded using independent recurrent neural networks. A graph neural network then propagates information across the time series using attention layers. The outcome is a set of updated hidden representations used by the recurrent neural networks to create forecasts in an autoregressive manner. This model can generate forecasts for all input time series simultaneously while remaining lightweight. We argue that this architecture opens up new possibilities as the model can be integrated into low-capacity systems without needing expensive GPU clusters for inference.
We gratefully acknowledge the support from ANP/PETROBRAS, Brazil (project N. 21721-6), CNPq (grants 310085/2020-9 and 310127/2020-3), CAPES (finance code 001) and C4AI-USP (FAPESP grant 2019/07665-4 and IBM Corporation).
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others

1 Introduction
Although the study of Multivariate Time Series (MTS) spans over 40 years, this area remains relatively unexplored due, in part, to its distinct nature compared to conventional statistical theory. Classical methods primarily rely on random samples and independence assumptions, whereas MTS are characteristically highly correlated [19].
Despite this, the field has recently garnered attention from Machine Learning (ML) researchers, motivated by the recent achievements in token sequence modeling, particularly in tasks related to Natural Language Processing (NLP). Models like the Transformer [17] have generated groundbreaking results in tasks such as question answering and text classification, thereby prompting the question: Can such successes be replicated in the context of time series?
For the majority of applications, ML algorithms currently underperform when compared to traditional statistical methods for univariate time series [9]. One of the main hurdles is that deep learning models, largely responsible for the ML revolution in NLP, are particularly susceptible to overfitting in univariate scenarios. However, multivariate problems exhibiting complex interactions are not easily modeled by classical approaches. This makes it an appealing area for ML research exploration.
This work introduces a cost-effective encoder-decoder architecture founded on Recurrent and Graph Neural Networks (RNNs and GNNs), coupled with vector time representation capable of forecasting MTS. Moreover, this proposed model can process data from sensors with differing sampling rates and missing data profiles without resorting to data imputation techniques. Our dataset consists of motion data from Floating Production, Storage, and Offloading units (FPSOs)—floating sea platforms used for oil extraction. Moored to the seafloor, FPSOs display intricate oscillatory behavior influenced by environmental factors such as wind, currents, and waves.
The key contributions of this work are fourfold:
-
We demonstrate that time encoding enhances forecasting results for complex oscillatory dynamics, especially when large missing data windows are present.
-
We provide evidence that heterogeneous graph neural networks can effectively propagate information between abstract representations of sensor data.
-
We define a comprehensive end-to-end system capable of modeling FPSO hydrodynamic behavior at low computational costs and without the need for elaborate data preprocessing routines.
-
Additionally, we argue that the proposed architecture can be successful in a wide range of applications.
In light of the above, this article is organized as follows: Section 2 presents the foundational concepts underpinning this work and provides a synopsis of how data irregularities can affect common ML architectures. Section 3 outlines the proposed architecture, while Sect. 4 offers a more detailed description of the dataset and experimental setups. Sections 5 and 6, respectively, present the experimental results and offer some conclusions, as well as directions for future work.
2 Background
This section introduces grounding concepts for this work, namely: MTS definitions and terminology, RNNs and GNNs main characteristics as means to restrict the search space for the parameter optimization process, and how FPSO motion forecast context is centered in dealing with data irregularities.
2.1 Multivariate Time Series
Formally, we can define a multivariate time series context as a (finite) set of time series \({\mathcal {S} = \{\mathbf {Z^i_t}\}^S_{i=1}}\). Each element of this set is a sequence of events of length \(T_z\), \({\mathbf {Z_t} = [Z_1, Z_2, \cdots , Z_{T_z}]}\), such that \(Z_t \in \mathbb {R}^{K_z}\). Note that we choose to represent a time series as a boldface matrix \(\mathbf {Z_t}\) with \(T_z\) observations of \(K_z\) features. This work treats each feature vector \(Z_t\) as an event associated with a scalar timestamp representing t.
The set \(\mathbf {\mathcal {S}}\) is defined over \(\mathbf {\chi }\) which is the input space of the model. Let’s suppose that, in the simplest case, one wishes to forecast the features associated with a single future event \(Z_{T_z+d}\) from a time series \(\mathbf {Z^i_t}\), but making use of all information contained in \(\mathbf {\mathcal {S}}\).
In other words, in this scenario we wish to approximate an unknown function \(f : \chi \rightarrow \mathbb {R}^{K_z}\) such that \(f(\mathbf {\mathcal {S}}) = Z_{T_z+d}\) for all \(\mathbf {\mathcal {S}}\). We call the approximated function \(\tilde{f} \in \mathcal {F}\).
An important concept in this work is the choice of function class \(\mathcal {F}\) that contains the function \(\tilde{f}\). The typical deep learning approach is to use a parametrized function class \(\mathcal {F} = \{f_\theta \in \varTheta \}\). An adequate parametrization guarantees the existence of a function \(\tilde{f}\) that is arbitrarily close to the true function f [6]. This is called the interpolating regime i.e. \(\tilde{f}(\mathbf {\mathcal {S}}) = f(\mathbf {\mathcal {S}})\) for all \(\mathbf {\mathcal {S}}\). Usually, the stochastic gradient descent algorithm is used to optimize the parameters by minimizing a loss function \(L(\tilde{f}(\mathbf {\mathcal {S}}), f(\mathbf {\mathcal {S}}))\).
However, each data point in a time series context typically has little to no information since the process is mainly driven by strong correlations and white noise processes. In this scenario, simple deep neural networks such as Multilayer Perceptrons (MLPs) rapidly pick-up spurious patterns and are unable to generalize to unseen data. Thus, to learn these complex interactions from the data available it is necessary to reduce the size of \(\mathcal {F}\) by restricting it.
2.2 RNNs and GNNs as Means to Restrict \(\mathcal {F}\)
Many successful deep learning models can be described as restricted optimization problems in function classes that represent some kind of symmetry. For example, Convolutional Neural Networks, which is the main architecture for image processing tasks, implement translational symmetry through the convolution operation on grids. Other analogous interpretations can be derived for gated RNNs, Transformers, and others [3].
In this work, we apply gated RNNs, which exhibit time warping symmetry invariance [16]. This symmetry is defined as any monotonically increasing differentiable mapping \(\tau : \mathbb {R}^+ \rightarrow \mathbb {R}^+\) between times. Being invariant to this symmetry means that gated RNNs can associate patterns in time series data even if they are distorted in time as long as order is preserved.
We also apply GNNs to propagate information between different \(\mathbf {Z^i_t}\). The GNN architecture [14] can be described by the message-passing mechanism:
where \(\textbf{x}_i^{(k)} \in \mathbb {R}^{D}\) is the new representation of the features of node i at layer k, \(\phi ^{(k)}\) is a differentiable message function that produces a hidden representation that is sent from node j to node i. \(\square \) denotes a differentiable, permutation invariant aggregation function that aggregates all messages from neighbour nodes. \(\gamma ^{(k)}\) is a differentiable function that updates the node’s hidden representation. Once again the crucial fact is the permutation invariance that restricts the function class \(\mathcal {F}\) with the fact that isomorphic graphs have the same representation.
There are several variants of GNNs and this work does not intend to detail their differences. A comprehensive survey can be found at [21]. In this work we use the Heterogeneous Graph Attention Network architecture. That means we consider the graph that models the MTS as being heterogeneous, i.e., as having different types of nodes and edges. This may become clearer in Sect. 3 that details how these RNNs and a GNN are combined in an end-to-end system.
2.3 FPSO Dynamics and Irregularities in MTS
While the contributions of this work apply to a general MTS context, it was developed to address the challenge of maintaining stable positions of floating platforms in deep water. FPSO units have been employed for years to safely extract offshore oil reserves. These floating platforms enable the extraction and storage of crude oil while being held in place using mooring lines anchored to the ocean floor. Mooring systems play a critical role in ensuring the positional stability, personnel safety, and smooth functioning of various operations on a platform, such as extraction, production, and oil offloading.
The constant exposure of floating structures to offshore environmental conditions like waves, currents, and wind leads to continuous stresses and strains on the platforms. Consequently, the structural integrity and mooring lines of these platforms degrade over time. Understanding and modeling the complex dynamics of the floating platform allows for real-time detection of unexpected oscillatory patterns, which could assist in assessing the mooring lines’ integrity. In this work, we analyze four variables: UTMN and UTME, which are north and east coordinates from a GPS, heading, which measures the rotation movement around the vertical axis, and roll, which measures the rotation along the longitudinal axis of the platform. These four variables are the most significant to characterize the platform movement.
The ever-increasing amount of data generated by sensors can be used to train ML algorithms for this task, but the same environment characteristics that deteriorate the mooring system also affect the sensors which are reflected in the measurements. Typical sensor data from FPSOs suffers from long-missing data windows, different polling rates between sensors, and other deformities.
Several data imputation approaches to achieve grid-like data structure have been proposed [5]. A regular grid structure allows for the usage of simple RNNs or even MLPs [13], but also causes the model behavior to be highly dependent on the data imputation technique used. Furthermore, achieving grid-like structure in complex sensor networks becomes rapidly unfeasible due to missing data points and shifted time series as shown in Fig. 1. Our proposal aims to offer a simple and robust solution that does not rely in any imputation process.

White balls denote observations from sensors. \(\mathbf {Z^1_t}\) is represented by a single feature and has two missing data points, denoted in dark gray, while \(\mathbf {Z^2_t}\) also has one feature, but a different frequency, and is shifted. Red balls denote data that would have to be imputed to achieve a grid-like structure. (Color figure online)
3 Architecture
The proposed architecture consists of a set of single-layered RNNs, a single layer of a Heterogeneous Graph Attention Network [2, 18], a time encoding module, and a linear projection layer.
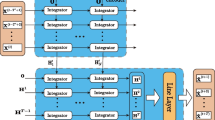
Each input time series is processed by a different RNN instance into a fixed-size representation as shown in Fig. 2. In this work, we use Gated Recurrent Units (GRUs) [4] which is a proven gated RNN architecture. This is a design choice that allows both \(T_z\) and \(K_z\) to vary between time series since RNNs can process arbitrary sequence lengths and each RNN instance has its width predefined based on the number of features of its input time series.

Encoding each time series with a different RNN instance provides flexibility to handle irregularities without the need for data imputation. Each time series is encoded into a fixed-size representation.
A central aspect in this work is the encoding of timestamps. Instead of feeding RNNs with only feature values, we also encode the time scalar for each observation using the positional encoding mechanism from [17]. The process can be visualized in Fig. 3.

Detailed view of encoding of a single time series. An RNN can ingest a sequence of arbitrary length \(T_z\). Instead of just feeding it with \(K_z\) features (1 in this example), the model adds the encoded timestamps as additional information. RNNs generate an output for each element in the input sequence, but our architecture only makes use of the last as a fixed-size representation of the whole input sequence.
More formally, the time encoder can be defined as a function \(T: \mathbb {R}^{T_z} \rightarrow \mathbb {R}^{T_z \times \mathcal {T}}\) that encodes each scalar \(t-t_0\), where \(t_0\) represents the instant of inference, into a representation of size \(\mathcal {T}\). Each RNN encoder can be defined as \(E^i: \mathbb {R}^{T_z \times (K_z + \mathcal {T})} \rightarrow \mathbb {R}^{\mathcal {H}}\) that encodes a sequence of \(T_z\) vectors with \(K_z\) features enriched by \(\mathcal {T}\) time features into a single hidden representation of size \(\mathcal {H}\).
Once each input time series has now a fixed-size representation, the information is shared between nodes using the message-passing mechanism defined in Eq. 1. Note that this expression denotes a homogeneous message passing. In a pure heterogeneous case, a different pair of functions \(\phi \) and \(\gamma \) would be trained for each edge type. That means for a graph with N nodes there would be \(N^2\) pairs of learnable parametrized message-passing functions. To prevent overfitting due to this quadratic increase of parametrized functions the regularization technique proposed in [15] is applied. In it instead of training a new pair of functions for each new edge type a fixed set of function pairs is trained and each edge type applies a different learnable linear combination of this set of bases.
The structures of \(\phi \) and \(\gamma \) are determined by the choice of GNN architecture, this work applies the Graph Attention Network v2 [2] that calculates attention masks for the incoming messages of each node. This allows nodes to incorporate the most relevant neighborhood information dynamically.
The GNN part of the encoder can be defined as \(\mathcal {G}: (\mathbb {R}^{N \times \mathcal {H}}, \mathcal {E}) \rightarrow \mathbb {R}^{N \times \mathcal {H}}\) that updates the hidden representation of each node \(i \in N\) based on the set of edges \(\mathcal {E}\). A fully-connected graph representation for our problem can be visualized in Fig. 4.

Heterogeneous GNN takes as input the fixed-size representation of each time series and propagates the information through the graph using the message-passing mechanism. Outputs are the updated vector representations for each node.
Finally, the decoding process uses the same RNNs used for encoding, but now in an autoregressive configuration coupled with a linear layer. The initial hidden state \(h^i_{t_0}\) is given by the updated hidden representation obtained from \(\mathcal {G}\). Each forecasted data point \(y^i_{t+1}\) is obtained by projecting the hidden representation that is iteratively updated. During this process, we also enrich the input features for the RNN with the encoded representations of the distance to the target timestamp \((t+1) - t_0\). The whole decoding process can be visualized in Fig. 5. Formally, each decoding step \(\mathcal {D}^i: (\mathbb {R}^{\mathcal {H}},\mathbb {R}^{K_z},\mathbb {R}) \rightarrow (\mathbb {R}^{\mathcal {H}},\mathbb {R}^{K_z})\) receives a hidden state \(h^i_{t}\), the last forecasted label \(y^i_t\) and a target time \(t+1\). It outputs an updated state \(h^i_{t+1}\) and its related output forecast \(y^i_{t+1}\).
It is important to note that each module-specific implementation could be replaced. Adopting alternatives for time encoding such as Time2Vec [8], different RNN architectures, such as LSTMs [7], or different GNN architectures would not change the grounding principles behind this work but could bring further performance gains.

The decoder uses the same RNN instances from the encoder. It takes the updated representations as its initial state and uses a linear projection to produce \(y^i_{t+1}\) in an autoregressive manner.
4 Experimental Setup
Three variants of the model were trained: a complete version including the timestamp encoding method and a fully connected graph (named full model); a second version without the timestamp encoding strategy (named no time enconding model); and a third version with a totally disconnected graph (named disconnected graph model). With these comparisons, we intend to evaluate the effectiveness of GNN in propagating information between abstract representations of sensor data and the improvement in regression performance provided by timestamp encoding.
For each model, 3 sets of tests were evaluated, varying the proportion of missing data points: 40%, 20% and 0%, in order to verify the model’s robustness in addressing the irregularities that usually occur in real sensor data. Long windows of 5% missing data were randomly inserted into the test dataset before inference. Often, missing data in sensor networks appear in the form of long missing data windows instead of isolated missing data points [1].
The dataset is obtained from numerical simulations that applies partial differential equations to model environmental conditions acting onto a 3D model of an existing FPSO. The simulator generates three-hour MTS with 1 s frequency for 7003 different environmental conditions, of which we separated 50% for training, 20% for validation and 30% to test. This represents 14,006 h of simulated data.
In this work validation data is only used for training convergence plots, i.e., no hyperparameter optimization was performed. All experiments used the following settings: \(\mathcal {T}=50, \mathcal {H}=200\). For the Heterogeneous GNN, the number of bases for regularization is 6 and the number of attention heads is 16. A single 10% dropout layer is applied to GNN outputs during training. Optimizing these hyperparameters may be beneficial, but it is not in the scope of this work.
To prepare the data, we applied a differentiation in each time series such that \(ds_{t} = s_{t} - s_{t-1}\). This is a common technique in autoregressive models and is especially relevant for GPS data, since FPSO initial offset can vary widely with environmental conditions. In addition, we applied a Z-Score normalization to the differential time series.
The instant of inference is denoted \(t_0\). The model builds the input MTS \(\mathcal {S}\) by filtering measurements within a certain context window c in seconds so that \(t_0 - c \le t < t_0\). This architecture allows for each time series to adopt a different context window length c based on its characteristics. Longer context windows of 1800 s are chosen for UTMN and UTME since their signals present lower frequencies, while shorter 600 s windows are enough to characterize the spectrum of heading and roll motions, which mostly consist of high frequencies. Such as the input, the model builds the target MTS \(\mathbf {\mathcal {S}}_{o}\) by filtering the measurements within a certain forecast window d in seconds so that \(t_0 \le t < t_0 + d \). For all the four variables we adopted forecast windows of \(d=\) 100 s.
The loss function \(L(\mathbf {\mathcal {S}_o}, \hat{\mathbf {\mathcal {S}_o}})\) used for training was based on the Index of Agreement [20] that provides a fit measurement between two time series that falls within the unit interval. This metric had been used successfully in the ML for MTS context by [10] since it provides a common range for all time series losses. For a MTS context it can be precisely defined as:
In each training epoch, the model chooses randomly a \(t_0\) from the three-hour MTS for doing the forecasting. With this, the model avoids becoming specialized in forecasting at some specifics inference times. For testing, we determined a set of inference times beforehand so each model can be consistently compared.
All models were trained for 2000 epochs. For the full model that corresponds to 22 h of training in a single NVIDIA RTX 3060Ti GPU. This inexpensive training is possible since the model is only four layers deep and contains 8.35M parameters taking up only 33.4 MB of disk space. The inference can be run in a consumer-level CPU in around 0.2 s while consuming 100 MB of memory.
5 Results and Analysis
Figure 6 displays each model’s results for the time series in a randomly selected environmental condition and \(t_0\), for different levels of missing data. The full model proved to be resistant to the increase of missing data points, and managed to maintain a consistent performance as the prediction horizon increased.

Illustration of the three models predictions (full model, no time enconding model, and disconnected model) with distinct missing data proportions for the four time series (UTMN, UTME, Roll, and Heading) in the same random environmental condition, considering a forecast window of 100 s.
Additionally, the model using disconnected graphs performed worst than both the full model and no-time encoding model, since in several cases the model was not able to correctly learn the movement tendency, and produced forecasts with significant offsets. In other cases, it failed to represent high frequency components of the MTS.
From this qualitative view it is noticeable that the full model also outperforms the no-time encoding model, especially as missing data windows increase. This is the hypothesized behavior since the time encoding provides a way for the RNN to recognize a time gap and adjust for it. Thus, the model was able to better extrapolate temporal patterns of motion.
Box plots in Fig. 7 present the evolution of the regression’s mean absolute error in the forecast window using the full model. For better visualization we omit the outliers, limiting the whiskers to comprehend the range of 5% to 95% percentiles. It is observed that as the temporal distance increases the error increases, as expected.

Boxplots of the absolute error versus the time distance to target in the forecast window for all the test environmental conditions. The whiskers are limited to comprehend the range of 5% to 95% percentiles.
Numerical results are presented in Table 1, displaying absolute errors’ statistics calculated upon the last predicted point in the inference horizon of 100 s. The results confirm the analysis for Fig. 6, showing that the full model outperformed the other two models in the vast majority of the cases, except for the 25% and 50% percentiles for the Roll series without missing data, that were better predicted by the no-time encoding model.
Here it is emphasized the resilience of the full model to the increase in missing data. This occurs because missing windows are recognized by the time encoding mechanism and missing information can be filled in by neighbouring nodes in a latent space, allowing for an “intrinsic data imputation” to occur. This effect of feature completion in GNNs was previously described by [12].
All three models displayed forecast outliers where errors were several times larger than the 95% percentile. Preventing or recognizing these outliers is an important task to enable these type of models for operating in mission critical tasks. Nevertheless, the full model also exhibited fewer and less extreme outliers.
To conclude, the evolution of the IoA during training calculated over the validation dataset is provided in Fig. 8. The results are evidence that both graph connectivity and time encoding act together to improve convergence speed and stability during training.

Evolution of Index of Agreement loss during training. This plot denotes IoA loss running mean for all time series for the last 30 epochs calculated over the validation dataset.
6 Conclusion
Results provide evidence that heterogeneous GNNs can effectively propagate information between abstract representations of sensor data, exploiting the relationship between them. This work also demonstrates that GNNs can be associated with RNNs and time encoders to tackle missing data windows in MTS.
This general architecture is a simple, cost-effective, yet robust solution for restricting the function class \(\mathcal {F}\) and allowing the stochastic gradient optimization to converge faster and more accurately in complex multivariate time series contexts. We argue, based on the results and conveniences of this model, that this architecture could be successful in a multitude of applications making it a strong one-fits-all model in the MTS context.
As future research directions, we note that other works have been successful on modeling MTS as abstract networks. We believe that approaches treat each single measurement as a different node such as [22] can be combined with latent graph inference techniques, allowing for dynamic inference of an underlying optimized graph topology.
Creating specialized functions that are able to store relevant information from hidden states into persistent vector representations for nodes between different inference times such as proposed by [11] is also an interesting direction for long-term predictions.
Finally, we believe a more comprehensive study on the choice of loss function and how known MTS losses affect this architecture could bring other insights on its capabilities and weaknesses.
This work was financed in part by ANP/PETROBRAS, Brazil (project N. 21721-6). We also gratefully acknowledge partial support from CNPq (grants 310085/2020-9 and 310127/2020-3).
References
Adhikari, D., Jiang, W., Zhan, J.: Imputation using information fusion technique for sensor generated incomplete data with high missing gap. Microprocess. Microsyst., 103636 (2021). https://doi.org/10.1016/j.micpro.2020.103636
Brody, S., Alon, U., Yahav, E.: How attentive are graph attention networks? CoRR abs/2105.14491 (2021). https://arxiv.org/abs/2105.14491
Bronstein, M.M., Bruna, J., Cohen, T., Velickovic, P.: Geometric Deep Learning Grids, Groups, Graphs, Geodesics, and Gauges. CoRR abs/2104.13478, 160 (2021)
Cho, K., et al.: Learning phrase representations using RNN encoder-decoder for statistical machine translation, September 2014. https://doi.org/10.48550/arXiv.1406.1078. arXiv:1406.1078 [cs, stat]
Emmanuel, T., Maupong, T., Mpoeleng, D., Semong, T., Mphago, B., Tabona, O.: A survey on missing data in machine learning. J. Big Data 8(1), 140 (2021). https://doi.org/10.1186/s40537-021-00516-9
Hartman, E.J., Keeler, J.D., Kowalski, J.M.: Layered neural networks with Gaussian hidden units as universal approximations. Neural Comput. 2(2), 210–215 (1990). https://doi.org/10.1162/neco.1990.2.2.210
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9, 1735–80 (1997). https://doi.org/10.1162/neco.1997.9.8.1735
Kazemi, S.M., et al.: Time2Vec: learning a vector representation of time (2019). https://doi.org/10.48550/arXiv.1907.05321. arXiv:1907.05321 [cs]
Makridakis, S., Spiliotis, E., Assimakopoulos, V.: Statistical and machine learning forecasting methods: concerns and ways forward. PLoS ONE 13(3), e0194889 (2018). https://doi.org/10.1371/journal.pone.0194889. https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0194889. Publisher: Public Library of Science
Netto, C.F.D., et al.: Modeling oceanic variables with dynamic graph neural networks, June 2022. https://doi.org/10.48550/arXiv.2206.12746. arXiv:2206.12746 [cs]
Rossi, E., Chamberlain, B., Frasca, F., Eynard, D., Monti, F., Bronstein, M.: Temporal graph networks for deep learning on dynamic graphs. arXiv:2006.10637 [cs, stat], October 2020. arXiv: 2006.10637
Rossi, E., Kenlay, H., Gorinova, M.I., Chamberlain, B.P., Dong, X., Bronstein, M.: On the unreasonable effectiveness of feature propagation in learning on graphs with missing node features, May 2022. https://doi.org/10.48550/arXiv.2111.12128. arXiv:2111.12128 [cs]
Saad, A.M., et al.: FPSO mooring line failure detection based on predicted motion. In: Proceedings of the ASME 2021 40th International Conference on Ocean, Offshore and Arctic Engineering. American Society of Mechanical Engineers Digital Collection, October 2021. https://doi.org/10.1115/OMAE2021-62413
Scarselli, F., Gori, M., Tsoi, A.C., Hagenbuchner, M., Monfardini, G.: The graph neural network model. IEEE Trans. Neural Netw. 20(1), 61–80 (2009). https://doi.org/10.1109/TNN.2008.2005605. http://ieeexplore.ieee.org/document/4700287/
Schlichtkrull, M., Kipf, T.N., Bloem, P., van den Berg, R., Titov, I., Welling, M.: Modeling relational data with graph convolutional networks. In: Gangemi, A., et al. (eds.) ESWC 2018. LNCS, vol. 10843, pp. 593–607. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-93417-4_38
Tallec, C., Ollivier, Y.: Can recurrent neural networks warp time? In: International Conference on Learning Representation 2018, February 2018. https://openreview.net/forum?id=SJcKhk-Ab
Vaswani, A., et al.: Attention is all you need. In: Guyon, I., et al. (eds.) Advances in Neural Information Processing Systems, vol. 30. Curran Associates, Inc. (2017)
Veličković, P., Cucurull, G., Casanova, A., Romero, A., Lió, P., Bengio, Y.: Graph attention networks. arXiv:1710.10903 [cs, stat], February 2018. http://arxiv.org/abs/1710.10903
Wei, W.W.S.: Multivariate Time Series Analysis and Applications. Wiley, p. 528 (2019)
Willmott, C.J.: On the validation of models. Phys. Geogr. 2(2), 184–194 (1981). https://doi.org/10.1080/02723646.1981.10642213. Publisher: Taylor & Francis _eprint
Wu, Z., Pan, S., Chen, F., Long, G., Zhang, C., Yu, P.S.: A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 32(1), 4–24 (2021). https://doi.org/10.1109/TNNLS.2020.2978386. https://ieeexplore.ieee.org/document/9046288/
Zhang, X., Zeman, M., Tsiligkaridis, T., Zitnik, M.: Graph-guided network for irregularly sampled multivariate time series, March 2022. https://doi.org/10.48550/arXiv.2110.05357. http://arxiv.org/abs/2110.05357 [cs]
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
de Barros, M.R. et al. (2023). Embracing Data Irregularities in Multivariate Time Series with Recurrent and Graph Neural Networks. In: Naldi, M.C., Bianchi, R.A.C. (eds) Intelligent Systems. BRACIS 2023. Lecture Notes in Computer Science(), vol 14195. Springer, Cham. https://doi.org/10.1007/978-3-031-45368-7_1
Download citation
DOI: https://doi.org/10.1007/978-3-031-45368-7_1
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-45367-0
Online ISBN: 978-3-031-45368-7
eBook Packages: Computer ScienceComputer Science (R0)