
Abstract
Exploring label correlations is one of the main challenges in multi-label classification. The literature shows that prediction performances can be improved when classifiers learn these correlations. On the other hand, some works also argue that the multi-label classification methods cannot explore label correlations. The traditional multi-label local approach uses only information from individual labels, which makes it impractical to find relationships between them. In contrast, the multi-label global approach uses information from all labels simultaneously and may miss more specific relationships that are relevant. To overcome these limitations and verify if improving the prediction performances of multi-label classifiers is possible, we propose using Community Detection Methods to model label correlations and partition the label space into partitions between the local and global ones. These partitions, here named hybrid partitions, are formed of disjoint clusters of correlated labels, which are then used to build multi-label datasets and train multi-label classifiers. Since our proposal can generate several hybrid partitions, we validate all of them and choose the one that is considered the best. We compared our hybrid partitions with the local and global approaches and an approach that generates random partitions. Although our proposal improved the predictive performance of the used classifier in some datasets compared with other partitions, it also showed that, in general, independent of the approach used, the classifier still has difficulties learning several labels and predicting them correctly.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others


1 Introduction
Multi-label classification is the task of simultaneously assigning multiple labels to an instance. Thus, a classifier must be induced to predict a set of labels for new instances. As real-world applications, we can mention recognition of sensor activities [13], protein function prediction [39], and drug-target interactions [20].
A multi-label problem can be solved mainly through local and global approaches. The local approach divides the original multi-label dataset into many binary ones, so labels are learned individually. One classifier per label is trained, and the individual predictions are gathered for the final evaluation. Any classification algorithm can be used, and traditional methods are Binary Relevance [25, 36] and Classifier Chains [23]. The global approach creates new methods or modifies existing ones to deal with all classes of the problem at the same time. Therefore, only one multi-label classifier is trained and is responsible for predicting all labels of an instance. Traditional methods in this approach include Back Propagation Multi-Label Learning (BPMLL) [37] and Multi-Label k-Nearest Neighbors (MLkNN) [38].
Among the challenges of multi-label classification, we can highlight class imbalance [33], high dimensionality [3], and label correlations [4]. Learning label correlations can help to predict labels that would probably not be predicted using traditional methods. Works in the literature have shown that modeling label correlations is an important aspect of multi-label classification and can help to build better classification models [12, 19].
The literature presents different strategies to model label correlations, and community detection methods are one of them [7] [32]. The motivation to use them is that the network topology can encode interactions of the data systematically and find relationships between them [17, 31]. Community detection methods are also graph partitioning algorithms: they divide vertices into clusters to minimize the number of edges between them. Roughly speaking, a community (cluster) is a set of vertices with many edges inside and a few edges outside the community, a desired characteristic for this study [31]. In multi-label problems, labels can be considered vertices and the correlations between them, the edges. Hence, we can build a graph of correlated labels, which can then be partitioned to find label communities.
In this paper, we verify if the performance of a classifier can be improved, and if it can better learn label correlations, using a different approach from the conventional global and local ones. We propose an approach that generates and validates several partitions from the label space - which explores the label correlations - and chooses the best one. Such partitions are composed of disjoint correlated label clusters and are called Hybrid Partitions.
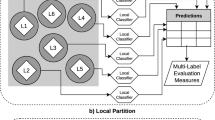
Figure 1 presents our idea of multi-label partitions, where squares are the partitions, circles are label clusters, and diamonds are labels. Figure 1a shows a global partition (global approach) composed of only one cluster with all labels. We induce one global classifier for global partitions, and this classifier simultaneously learns and outputs predictions for all labels. Figure 1b shows a local partition (local approach) composed of one cluster for each label. One local classifier per cluster is induced in local partitions, also with train and test sets, and then we gather those predictions to make the final evaluation for the dataset. Finally, Fig. 1c shows an example of a hybrid partition, where correlated labels are clustered. We need to induce a global-based classifier for clusters with more than one label, in order to learn correlations between those labels. In contrast, we induce a local-based classifier for clusters with a single label. The final prediction is then obtained combining the predictions performed by all global and local-based classifiers.

Illustration of the Global, Local and Hybrid Partitions.
To get consistent and coherent results, we must use the same classifier in all clusters; otherwise, we cannot observe how much the classifier learned. Therefore, we emphasize that using a multi-label classifier with local and global versions is necessary for our strategy since we want to compare the improvements from hybrid partitions in relation to local, global, and even random generated partitions. Therefore, the same classifier must be used in all partitions.
As an example, it does not make sense to use a global-based classifier such as ML-C4.5 [8] since it cannot handle clusters containing a single label. In our strategy, using Binary Relevance in clusters with more than one label is not possible, as we would be re-dividing the problem and learning separate labels when we want to learn the clustered labels. Accordingly, the classifier used in our strategy has to deal with all types of partitions.
For this reason, here we used the Clus Framework [34], which induces binary and multi-label decision trees based on Predictive Clustering Trees (PCT), and is considered to be one of the state-of-the-art methods in the literature. We train a binary PCT for each label and combine their outputs to form the final multi-label prediction for the local partition. For the global partition, only one multi-label PCT is necessary. To test our hybrid partitions, a set of multi-label PCTs, or a combination of binary and multi-label PCTs, can be applied, depending on how many labels are in the partition clusters. The individual outputs are then combined to form the final multi-label prediction.
As already pointed out by Basgalupp et al. [1], finding a suitable partition in a set with n labels is a hard task, whose difficulty increases with the number of labels. Considering a set with n labels, the number of possible partitions consisting of k separate and non-empty subsets is given by \(\sum _{k=0}^{n} \left\{ n \atop k\right\} \) [16]. Thus, the number of possible partitions drastically increases with the number of labels. As an example, with \(n=12\) labels, 44.213.597 partitions can be generated.
Our experiments were conducted using 20 benchmark multi-label datasets from five application domains with different characteristics. First, we used Jaccard Index and Rogers-Tanimoto similarity measures to model the label correlations, which are used to build the label co-occurrence graphs. Then, we applied 7 community detection methods that partition the graphs and generate several hybrid partitions. Next, those hybrid partitions were validated, and the best one tested. Finally, the performance results were compared with the global, local, and random generated partitions using the same base classifier.
Our results showed that our approach could improve the classifier’s prediction, be competitive with the local and random generated partitions, and outperform the global approach. However, the results also showed that independent of the partitioning used, the overall performance did not improve much, i.e., we noticed that the average performance remained competitive for most methods and datasets. Thus, the valuable insight we had with our results is that the multi-label classification methods need to improve because regardless of the partitioning used or if the correlations were (or not) explored, we cannot state with absolute certainty that they are correctly learning the labels.
The remainder of this paper is organized as follows: Sect. 2 presents some related studies; Sect. 3 presents our proposed approach; Sect. 4 explains how we conducted our experiments; Sect. 5 presents and discusses our results; and finally, Sect. 6 presents our conclusions and future works.
2 Related Work
A related and similar study was presented by Melo and Paulheim [15]. The authors used local and global feature selection approaches with binary relevance to compare flat and hierarchical problems. They showed that when using multi-label transformation methods, the overall predictive performance of the local feature selection approach was better and superior to the global. However, the authors also elucidated that, in some cases, the results of the best general performance between adaptation or transformation methods are inconclusive. Although the authors used the instance space and feature selection, the results presented go in the same direction as our work.
Rivolli et al. [25] presented a hypothesis that base algorithms can have a more substantial influence than the binary transformation strategies on the predictive performance of multi-label models. The authors demonstrated that despite the performance improvements, all investigated strategies and base algorithms could not predict some labels or mispredict labels for many datasets. Therefore, the conclusions are aligned with our study.
On the problem of learning label correlations, Luaces et al. [14] demonstrated that the level of dependency between labels in benchmark datasets is deficient, so the methods cannot explore the correlations. That was one of the reasons that led them to build a synthetic dataset generator, combining synthetic data with benchmark datasets to better analyze the behavior of multi-label classification methods. They pointed out the difficulty of extracting useful conclusions using only benchmark datasets.
In Gatto et al. [12], the authors modeled label correlations using the Jaccard index and partitioned the label space using Agglomerative Hierarchical Clustering, which was able to find hybrid partitions. They used average, complete, and single linkage as an agglomerative method to build dendrograms and cut them into levels. Different hybrid partitions were generated and validated using the Clus framework, which can deal with local and global partitions. The highest Macro-F1 performance was used to choose the more suitable hybrid partition, compared with local, global, and random generated partitions. The authors concluded that the results from hybrid partitions were competitive, or better in some cases, compared to the local and global approaches. Similar to our work, the authors, in the same direction as Melo and Paulheim [15], observed that the local approach was superior to the global one in most cases.
Also trying to find partitions in-between the global and local ones, the study presented by Basgalupp et al. [1] investigated whether it was possible to obtain better results by learning multi-target models on several partitions of the targets. They used a Genetic Algorithm (GA) and an exhaustive search to find alternate partitions between the global and local ones. They tested those partitions with random forests and decision trees in multi-target regression and multi-label problems and then compared them with the local and global ones. An oracle experiment was also conducted, proving that it is possible to find partitions beyond traditional ones and obtain superior performances. Although the global approach led to better results for the multi-label case with decision trees, the results showed no statistically significant differences among local, global, and alternate partitions, which matches our conclusions. In our work, we also found hybrid partitions that led to better results than the local and global ones for some datasets, and the conclusions from this study are similar to the ones from Melo and Paulheim [15].
From the revised works we can find many open research questions in Multi-Label Classification. Our objective here is not to answer or find solutions for all of them. Instead, we focused on finding partitions between global and local ones and verifying whether they could improve the classifier’s predictions.
3 Proposed Approach
Our approach consists of the following steps: 1) data preprocessing, which divides the dataset into train, validation, and test sets; 2) modeling label correlations, where we build graphs computing Jaccard Index and Rogers-Tanimoto similarity measures on the label space of the train set; 3) applying community detection methods to find hybrid partitions; 4) building the hybrid partitions and the corresponding datasets for each partition; 5) validate the hybrid partitions and choose the best one using the silhouette coefficient; and 6) test the best hybrid partition with the test set. Figure 2 shows an overview of our approach. The complete process is presented in the following subsections.

Overview of the Proposed Approach.
3.1 Steps 1 and 2: Preprocess and Model Label Correlations
Step 1 divides the dataset into the train, validation, and test sets and also splits the label space from the train set, while step 2 models label correlations. According to Silva and Zhao [31], we need a similarity or dissimilarity matrix to build a network from vector-based data, which makes it possible to establish links between pairs of labels with weights according to that matrix. However, links with small weights can lead to poor results and be considered noises that could provide wrong information to the machine learning algorithm. To avoid that, sparsification must be applied, a preprocess that cuts those edges and can improve the learning stage.
One traditional sparsification is based on the concept of k nearest neighbors, where the cuts occur in the links that are not part of the neighborhood. Another type allows a threshold that cuts some percentage of the links [31]. We use both types in our study. We choose Jaccard Index (Eq. 1) and Rogers-Tanimoto (Eq. 2) as similarities measures to build label co-occurrence graphs, as they are well-known and popular measures [6, 11, 35].
In Eqs. 1 and 2, a stands for the number of times labels \(l_{p}\) and \(l_{q}\) occur together, while d stands for the number of times those two labels never occur together. Variables b and c indicate the number of times labels \(l_{p}\) and \(l_{q}\) occur alone. Each measure is applied in the label space of the train set, resulting in similarity matrices. Each matrix represents a complete graph modeled with the label correlations, where an edge (similarity value) connects every pair of distinct vertices (labels).

3.2 Step 3: Apply Community Detection Methods
In this step, we applied seven community detection methods to each graph. The methods are divided into two categories: a) Hierarchical: Waktrap [21], Fast Greedy [9] and Edge Betweenness [18]; and b) Non-Hierarchical: Louvain [2], InfoMap [27], SpinGlass [24] and Label Propagation [22]. Hierarchical methods provide dendrograms that can be used to construct several hybrid partitions. The procedure is similar to hierarchical clustering but uses different techniques to agglomerate vertices: Walktrap, which is based on random walks; Fast Greedy based on modularity gain, and Edge Betweenness based on the number of shortest paths through the edge. Unlike hierarchical methods, non-hierarchical ones provide only one hybrid partition, constructed using different concepts. Louvain and Infomap are multilevel methods and differ in the optimization function used: the former is based on FastGreedy and the latter on map equation. SpinGlass is based on Potts Spin Glass, which uses rotation models to perform clustering, while in Label Propagation, each vertex is assigned to the most frequent label among its neighbors.
3.3 Step 4: Build Hybrid Partitions
After applying community detection methods, only one is chosen to generate hybrid partitions. This choice is performed using a modularity criterion that measures the separation among vertices, quantifying the density of links within communities compared to links between communities [18, 31]. Finally, the method with the highest modularity value is chosen. As an example, consider that between non-hierarchical methods, Louvain obtained the highest modularity value. Hence, each identified community can be considered a cluster of correlated labels. Then, we build a corresponding dataset for each cluster using the train instances assigned to the labels of the cluster, induce a classifier, and test it in the test set. The same occurs with hierarchical methods, but as they generate more than one hybrid partition, we must validate all generated partitions from the chosen community detection method and then choose only one hybrid partition to test.
3.4 Step 5: Validate Hybrid Partitions
This step is executed only in the partitions generated by hierarchical community detection methods since these generate several hybrid partitions. Each hybrid partition created using hierarchical methods in step 4 is now evaluated in a validation dataset. Here we used the silhouette coefficient [28, 30] cluster validation measure. It measures the quality of partitions based on the proximity between, in this case, the labels of a particular cluster and the distance between them and the closest cluster. The partition with the highest silhouette coefficient is then evaluated in a test dataset.
3.5 Step 6: Testing Hybrid Partitions
Finally, the last step is to test the best-validated hybrid partition. As already explained, the Clus Framework was used in our experiments, configured with the hyper-parameters listed below. For a detailed explanation of Clus and its hyper-parameters, the reader can consult the Clus webpageFootnote 1.
-
General: Compatibility = MLJ08
-
Attributes: ReduceMemoryNominalAttrs = yes and Weights = 1
-
Tree: Heuristic = VarianceReduction and
FTest = [0.001,0.005,0.01,0.05,0.1,0.125]
-
Model: MinimalWeight = 5.0
-
Output: WritePredictions = Test
4 Experimental Setup
We evaluated our approach using 20 multi-label datasets from five different application domains, which were chosen to diversify the domain and number of labels. Their characteristics are summarized in Table 1 with the name of each dataset, domain, the total number of instances, attributes, and labels. Cardinality is the average of labels per instance; Density is the average frequency of labels, and TCS (Theoretical Complexity Score) [5] is a measure that computes how difficult it is to learn a predictive model from the dataset.
Our source code and all necessary materials to replicate the experiments are freely availableFootnote 2. We executed our experiments within the 10-fold cross-validation strategy, using an iterative stratification algorithm proposed for multi-label data [29]. Our proposal was compared with three approaches to generate partitions: local, global, and random. Global and local partitions were already explained in Sect. 1. Random partitions were generated similarly to hybrid partitions. The main difference is in Step-2: given an adjacency matrixFootnote 3 obtained from the label space, k-NN sparsification is executed with a random chosen k value.
To evaluate the results, we focused mainly on two multi-label measures: a) Macro-F1 (MaF1), which is the harmonic mean of the Macro-Precision (MaP) and Macro-Recall (MaR), and b) Missing Label Problem (MLP). MaF1 is a good measure for multi-label problems since it considers the individual performances in each class. Furthermore, its analysis is complemented by MLP, which calculates the proportion of labels that are never predicted [26].
Analyzing the results with the MLP measure is important since traditional multi-label measures cannot correctly identify when some individual labels are not correctly predicted for any given instance. However, it is possible to identify the predictive performance of each label for each instance individually. Thus, MLP is an important measure to identify labels the classifiers could not learn and thus are never predicted. Equations 3, 4, 5, and 6 show the evaluation measures used in the experiments where: \(\mathcal {L}\) is the set of all labels in the label space, and \(tp_{j}\), \(fp_{j}\) and \(fn_{j}\) are, respectively, the number of true positives, false positives, and true negatives for class \(y_j\).


5 Results, Analysis and Discussion
We generated 20 different variations of our proposal (Table 2). Considering k-NN sparsification, we experimented three values for k (k = 1, k = 2 and k = 3). Considering threshold sparsification, we considered two alternatives: T0, which cuts only the self-loops from the graphs, and T1, which cuts 10% of edges from the graphs. Table 2 also shows the global and local methods and two variations of random methods, one using hierarchical community detection methods and another using non-hierarchical community detection methods.
5.1 Community Detection Methods Selected
For the Rogers-Tanimoto similarity measure, the most chosen hierarchical community detection methods were Edge Betweenness for threshold sparsification and WalkTrap for \(k-\)NN sparsification. In contrast, for Jaccard Index, Walktrap was the most chosen in both sparsification types. In the case of the non-hierarchical methods, InfoMap was the most chosen community detection method for both similarity measures and sparsification types. Finally, for Random Communities, the hierarchical method most chosen was WalkTrap, while InfoMap was the most chosen for non-hierarchical methods.
5.2 Hybrid Partitions Selected
For birds, emotions, EukaryotePseAAC, and yeast datasets, the best partitions chosen were close to the local partition. In contrast, eisen, GnegativeGO, GpostiviGO, scene, and Yelp datasets had the best partitions chosen close to the global partition. Considering the Langlog dataset, the partition most frequently chosen was similar to the local. In contrast, in pheno dataset, there is a balance between partitions near the global or local ones. Finally, the best partitions for the other datasets vary, but a partition close to the global partition configuration was more frequently chosen. Our experiments observed that the best hybrid partitions generated by the chosen community detection methods are similar to the global partition. This can be one reason our performance results are competitive compared with other partitions, overcome the global, and are not superior to the local ones for some datasets.
5.3 Classifier’s Performance
Figure 3 presents the number of wins, losses, and ties considering the 24 methods and 20 datasets. In the figure, blue indicates wins, purple indicates losses, and green indicates ties. Considering the performances over the 20 datasets in both MaF1 and MLP measures, the local approach tends to obtain the best results, followed by the results obtained with the hybrid partitions. On the other hand, the global approach obtained the worst results. Furthermore, the Theoretical Complexity Score (Table 1) presents high values for all datasets except emotions and flags. This indicates that it is hard to learn label correlations in most of the datasets.

Graphical representations of wins, losses, and ties for each method.
The classifier’s performance resultsFootnote 4, in several datasets, using random partitions outperformed its performance when using global partitions. When comparing H.Ra and NH.Ra with Lo, the random partitions led to competitive results. Regarding the sparsification methods, k-NN obtained slightly better performances when compared to threshold sparsification.
The clusters of the partitions found by the community detection methods for each dataset were similar and sometimes the same. By all indications, our method is not significantly affected by sparsification with k-NN. We also notice that the results from graphs built with the Jaccard index and Hierarchical methods outperformed the ones with the Rogers-Tanimoto similarity, while in Non-Hierarchical methods, Rogers-Tanimoto were generally better than the Jaccard index. Finally, in a method-by-method pairwise comparison, the local partitions performed better than all other partitions on an average of 16 datasets. Meanwhile, hybrid and random partitions achieved the best results on an average of 10 datasets.
For the MLP measure, the resulting values for many datasets are about 0.9. As the best value for this measure is 0.0, a value near 1.0 indicates that not all labels were correctly learned nor predicted by the classifier. The pheno dataset had the worst result when using the local partition, 0.977, which means that the classifier did not correctly predict 97% of all labels. In contrast, at least 40% of the labels were predicted by the other methods, indicating that the correlated labels were helpful in the learning process.
Considering the MaF1 average values over the 20 datasets, most of the methods obtained performance values between 0.3 and 0.2, which is considered low. The best results (close to 1.0) were obtained in the datasets GpositiveGO and GnegativeGO, which have few labels. Similar results can also be found in related studies, where the authors showed that multi-label classifiers could not correctly learn and predict the labels and correlations. Finally, our results show that the traditional local and global approaches cannot correctly learn label correlations since random generated partitions led to very similar results in many cases.
5.4 Statistical Tests
To verify the statistical significance of our results, we executed the Friedman test (\(\alpha = 0.05\)), followed by the Nemenyi post-hoc test. They are adequate when comparing many classifiers over multiple datasets [10]. The respective Friedman p-values were 5.75e-09 and 9.27e-14, and the critical distances are shown in Figs. 4 and 5. No statistically significant differences were detected between the results obtained with the local approach and those obtained with the random partitions generated with non-hierarchical community detection methods. There were also no significant differences when comparing the global partition and the random partitions generated with hierarchical community detection methods.

Critical Diagram for the MaF1 Results.

Critical Diagram for the Missing Label Problem Results.
When comparing local and hybrid partitions from hierarchical community methods, there were no significant differences, meaning that hybrid partitions led to competitive results. The same occurs with global partitions and hybrid partitions from non-hierarchical community methods. Given that random generated partitions led to results equal or superior to the local and global approaches, we can conclude that local and global-based methods still need many improvements. Thus, our results show that the conventional and widely-used local and global approaches may not correctly learn label correlations.
6 Conclusions and Future Works
In this paper, we presented an approach that aims to improve multi-label classifiers’ performances by partitioning the multi-label dataset into in-between local and global partitions. These so-called hybrid partitions are obtained with community detection methods by learning label correlations in the label space. First, we modeled label correlations with the Jaccard Index and the Rogers-Tanimoto similarity measures and used the resulting similarity matrices to model graphs. Next, we applied k-NN and threshold sparsification methods to prune edges from the graphs. We then applied seven community detection methods, three hierarchical and four non-hierarchical.
For the non-hierarchical methods, we generated hybrid partitions directly using a training set and tested them with a test set. For hierarchical methods, we obtained dendrograms that were cut into levels to generate several hybrid partitions, also using a training set. Then, we validated those partitions with a silhouette coefficient using a validation set. Finally, the hybrid partition with the highest coefficient value was tested.
Our results showed that our proposed approach could obtain better or more competitive results in several datasets when compared to conventional local and global approaches. We also compared the results obtained by the global and local approaches with the ones obtained using random generated partitions. We could verify if the partitioning improved the prediction power of the classifier. We concluded that there is no vast improvement besides our competitive results, and independently of the partitioning used. According to the results obtained when using the Missing Label Problem measure, this probably occurred because most labels were not learned by the classifier, even by traditional approaches. Therefore, we can conclude that the local and global approaches still need many improvements and may not correctly learn label correlations.
In future works, we intend to explore other multi-label evaluation measures, such as Wrong Label Problem and Constant Label Problem [26], and also use other base classifiers to test the generated partitions. With this, we will be able to compare the results from different classifiers, verify possible improvements, and recommend the best classifier and label partition for a given dataset.
Notes
- 1.
- 2.
- 3.
Computes the number of instances classified in all pairs of labels.
- 4.
For the sake of space and better presentation, the tables with all the performance values were not included in this paper but are available in the repository.
References
Basgalupp, M., Cerri, R., Schietgat, L., Triguero, I., Vens, C.: Beyond global and local multi-target learning. Inf. Sci. 579, 508–524 (2021)
Blondel, V.D., Guillaume, J.L., Lambiotte, R., Lefebvre, E.: Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, P10008 (2008)
Bogatinovski, J., Todorovski, L., Džeroski, S., Kocev, D.: Comprehensive comparative study of multi-label classification methods. Expert Syst. Appl. 203, 117215 (2022)
Chang, W., Yu, H., Zhong, K., Yang, Y., Dhillon, I.S.: A modular deep learning approach for extreme multi-label text classification. CoRR abs/1905.02331 (2019)
Charte, F., Rivera, A., del Jesus, M.J., Herrera, F.: On the impact of dataset complexity and sampling strategy in multilabel classifiers performance. In: Hybrid Artificial Intelligent Systems, pp. 500–511. Springer International Publishing (2016)
Choi, S., Cha, S., Tappert, C.C.: A survey of binary similarity and distance measures. J. Systemics Cybern. Inform. 8, 43–48 (2010)
Chu, Y., et al.: DTI-MLCD: predicting drug-target interactions using multi-label learning with community detection method. Briefings in Bioinform. 22, bbaa205 (2020)
Clare, A., King, R.D.: Predicting gene function in saccharomyces cerevisiae. In: Proceedings of the European Conference on Computational Biology (ECCB 2003), September 27–30, 2003, Paris, France, pp. 42–49 (2003)
Clauset, A., Newman, M.E.J., Moore, C.: Finding community structure in very large networks. Phys. Rev. E 70, 066111 (2004)
Demšar, J.: Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 7, 1–30 (2006)
Garg, A., Enright, C.G., Madden, M.G.: On asymmetric similarity search. In: 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA) (2015)
Gatto, E.C., Ferrandin, M., Cerri, R.: Exploring label correlations for partitioning the label space in multi-label classification. In: 2021 International Joint Conference on Neural Networks (IJCNN) (2021)
Lin, S.C., Chen, C.J., Lee, T.J.: A multi-label classification with hybrid label-based meta-learning method in internet of things. IEEE Access 8, 42261–42269 (2020)
Luaces, O., Díez, J., Barranquero, et al., J.: Binary relevance efficacy for multilabel classification. Progress in Artificial Intelligence (2012)
Melo, A., Paulheim, H.: Local and global feature selection for multilabel classification with binary relevance an empirical comparison on flat and hierarchical problems (2017)
Mezo, I.: The r-bell numbers. J. Integer Sequences 14, A11 (2011)
Mittal, R., Bhatia, M.P.S.: Classification and comparative evaluation of community detection algorithms. Archives of Computational Methods in Engineering (2020)
Newman, M.E.J., Girvan, M.: Finding and evaluating community structure in networks. Phys. Rev. E 69, 026113 (2004)
Nguyen, T.T., Nguyen, T.T.T., Luong, A.V., Nguyen, Q.V.H., Liew, A.W.C., Stantic, B.: Multi-label classification via label correlation and first order feature dependance in a data stream. Pattern Recogn. 90, 35–51 (2019)
Pliakos, K., Vens, C., Tsoumakas, G.: Predicting drug-target interactions with multi-label classification and label partitioning. IEEE/ACM Trans. Comput. Biol. Bioinform. 18 1596–1607 (2021)
Pons, P., Latapy, M.: Computing communities in large networks using random walks (long version) (2005)
Raghavan, U.N., Albert, R., Kumara, S.: Near linear time algorithm to detect community structures in large-scale networks. Phys. Rev. E 76, 036106 (2007)
Read, J., Pfahringer, B., Holmes, G., Frank, E.: Classifier chains: a review and perspectives. J. Artif. Intell. Res. 70, 683–718 (2021)
Reichardt, J., Bornholdt, S.: Statistical mechanics of community detection. Phys. Rev. E 74, 016110 (2006)
Rivolli, A., Read, J., Soares, C., Pfahringer, B., de Leon Ferreira de Carvalho, A.C.P.: An empirical analysis of binary transformation strategies and base algorithms for multi-label learning. Machine Learning (2020)
Rivolli, A., Soares, C., Carvalho, A.C.P.d.L.F.d.: Enhancing multilabel classification for food truck recommendation. Expert Systems (2018)
Rosvall, M., Bergstrom, C.T.: Maps of random walks on complex networks reveal community structure. Proceedings of the National Academy of Sciences 105 (2008)
Rousseeuw, P.: Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 20, 53–65 (1987)
Sechidis, K., Tsoumakas, G., Vlahavas, I.: On the stratification of multi-label data. In: Gunopulos, D., Hofmann, T., Malerba, D., Vazirgiannis, M. (eds.) ECML PKDD 2011. LNCS (LNAI), vol. 6913, pp. 145–158. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-23808-6_10
Shahapure, K.R., Nicholas, C.: Cluster quality analysis using silhouette score. In: 2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA) (2020)
Silva, T.C., Zhao, L.: Machine Learning in Complex Networks. Springer Publishing Company, Incorporated (2016)
Szymański, P., Kajdanowicz, T., Kersting, K.: How is a data-driven approach better than random choice in label space division for multi-label classification? Entropy 18 (2016)
Tahir, M.A.U.H., Asghar, S., Manzoor, A., Noor, M.A.: A classification model for class imbalance dataset using genetic programming. IEEE Access 7, 71013–71037 (2019)
Vens, C., Struyf, J., Schietgat, L., Džeroski, S., Blockeel, H.: Decision trees for hierarchical multi-label classification. Mach. Learn. 73, 185–214 (2008)
Warrens, M.J.: Similarity coefficients for binary data: Properties of coefficients, coefficient matrices, multi-way metrics and multivariate coefficients. Master’s thesis, Leiden University (2008)
Zhang, M.L., Li, Y.K., Liu, X.Y., Geng, X.: Binary relevance for multi-label learning: an overview. Front. Comput. Sci. 12, 191–202 (2018)
Zhang, M.L., Zhou, Z.H.: Multi-label neural networks with applications to functional genomics and text categorization. IEEE Trans. Knowl. Data Eng. 18, 1338–1351 (2006)
Zhang, M.L., Zhou, Z.H.: Ml-knn: a lazy learning approach to multi-label learning. Pattern Recogn. 40, 2038–2048 (2007)
Zhou, J.P., Chen, L., Guo, Z.H., Hancock, J.: Iatc-nrakel: an efficient multi-label classifier for recognizing anatomical therapeutic chemical classes of drugs. Bioinformatics 36, 1391–1396 (2020)
Acknowledgments
This study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - Brasil (CAPES) - Finance Code 001. The authors also thank the Brazilian research agencies FAPESP and CNPq for financial support.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Gatto, E.C., Valejo, A.D.B., Ferrandin, M., Cerri, R. (2023). Community Detection for Multi-label Classification. In: Naldi, M.C., Bianchi, R.A.C. (eds) Intelligent Systems. BRACIS 2023. Lecture Notes in Computer Science(), vol 14195. Springer, Cham. https://doi.org/10.1007/978-3-031-45368-7_6
Download citation
DOI: https://doi.org/10.1007/978-3-031-45368-7_6
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-45367-0
Online ISBN: 978-3-031-45368-7
eBook Packages: Computer ScienceComputer Science (R0)