
Abstract
College dropout is a concern for educational institutions since it directly impacts educational management and academic results, as well as being directly related to social problems. Therefore, there is significant incentive for studies that use data to support decisions by predicting risk of dropout so that institutions can attempt to prevent such cases. Although machine learning techniques were shown to have potential for this task, there are many steps involved when it comes to the use of real data, which comes from scattered systems and present issues such as need for data cleaning and preparation, high dimensionality of the data requiring adequate feature selection, as well as class imbalance. In this paper, we used data from 32.892 students enrolled between 2008 and 2020 from all courses offered by a public high-education institution. A protocol for data preparation is proposed and found to be more important than designing complex classifiers. We present guidelines when modelling a college dropout classification task using a public university data and experiments using Walk-Forward Validation that showed the predictive capacity for the first years.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others


1 Introduction
Students of higher education are exposed to several positive and negative events in college. The successes often outweigh the efforts from the enrolment until the student effectively earns a degree, however adversities may lead to dropout [36, 39]. This phenomenon also related to college attrition, is common to both public and private higher education, directly interfering in their management and in the results of education quality [29, 35], which consequently generates a necessary concern, as the students’ departure from the study cycle induces several consequences [18, 31]. The costs associated with college attrition include hindering of future job prospects with impacts in the countries’ economy, the personal and professional costs for the former student, waste of institutional and federal resources, potential damage to university reputation and demoralization of students [5, 13].
Several factors may influence dropout [3], the main ones reported in the literature related to financial and family reasons, unfulfilled expectations and lack of motivation [5]. Xenos, Pierrakeas and Pintelas [40] stated that the identification of such specific factors is essential to provide special assistance to students, and categorizes them as related to: (i) internal or students’ perception; (ii) course and professors and; (iii) student demographic characteristics.
Additionally, many studies point out a high prevalence of mental health problems in college students, which are even most common in those exposed to relational stressors and low social support [9, 22]. In a survey conducted by Eisenberg et al. [9] in an university in the US, the prevalence of depressive or anxiety disorders was 15.6% for undergraduate students and 13.0% for graduate students, as well as presence of suicidal ideation reported by 2% of students.
According to Leonhardt and Sahil [18], in North American higher education, in 2018, about one in three students who enrol in college never earn a degree. They looked at data from 368 colleges arranged by what they would expect their graduation rates to be, based on the average for colleges with similar student bodies. They found higher success rates in those that remove hurdles for students. Also, such success was correlated with students having better connection to the college community, having less financial issues, and when the university offered good infrastructure and support.
In Brazil, a special committee on dropout studies was established in 1995, from Ministry of Education ordinance, with the purpose of evaluating the performance of Federal Higher Education Institutions (FHEI; IFES, in Portuguese). In 2002, this became a major concern with the significant increase in the number of places offered by IFES in Brazil [39].
In this context, Data Mining and Machine Learning techniques have been explored to investigate this problem. Previous studies often to use data to identify student’s risk of dropout [1, 7, 15, 16, 21, 25, 32, 34]. Some of those focus on specific patterns such as student’s personal profile [8, 23], others on behavior, e.g. procrastination [11] and others in social issues [6].
In this paper, we use data gathered from different information systems at the Federal University of São Carlos (UFSCar), in the interior of the State of São Paulo - Brazil, to predict the risk of dropout in groups of students. The objective is to integrate it to the university solutions for decision support. When using real world data is not trivial. Thus, we present guidelines to evaluate and deploy predictive models and the necessary preparation steps, including data cleaning. In addition to evaluate the model using Walk-Forward Validation evaluation, we propose four experiments using different subset of data and tests on data not seen during the training of the learning model. Our results represent a milestone in terms of making it possible, in practice, to identify students in higher risk and direct them to services that address issues related to emotional distress, financial problems, among others.
The paper is structured as follows: Sect. 2 describes related works; Sect. 3 describes the main steps of data exploration, as well as what information was collected and processed, the data preparation and cleaning, experiments applied, and the results obtained and, finally, Sect. 4 points out the final remarks.
2 Related Work
Previous studies found that college attrition depend on the type of course [8, 40], student’s year at college [8, 18, 19, 36], social issues such as parental background [2, 8], class-cultural discontinuities [17] and economic profile [28]; as well as quantitative academic data [25].
In particular, Lozano et al. [19] found the first and second years to be crucial when it comes to retention, as it allows for more numerous and more intensive interventions. According to Casanova et al. [8], the first years are particularly difficult for students who enrolled in the course as a second option. The authors suggest improving motivation in students who have to adapt to this situation.
A study carried out in Catalan universities used academic data, face-to-face interviews and telephone interviews, concluding that main factors for dropout risk were: lack of motivation; work-related reasons; unfulfilled expectations; time-table mismatch; family reasons; financial reasons and other opportunities [38]. However, the need for individual interviews at the dropout risk assessment stage can hamper scalability.
Interventions may represent a positive approach to improve retention [30]. This was shown at a Brazilian public university, in which dropout decreased 12.3% in 2018 when compared to 2017 [4]. This was due to institutional interventions that increased the number of registered students, accounting for new admissions and the re-inclusion of students who had taken a time off from college.
Data Mining and Data Science techniques are also relevant in the educational context [12]. In da Silva et al. [33], the authors used an ensemble of regressors to predict dropout rate percentage of higher-education institutions. Pal [26], in turn, used a Bayesian Machine Learning (BML) classification method with high school data, income, family position, type of admission, gender, and other school data. Their strategy was to compare the student profile with the classification provided by the model [26]. Manhaes et al. [20] studied academic data of a Brazilian university and found dropout patterns related to the first year, indicating failure in early courses are present in all dropouts.
A study carried out by Tontini and Walter [37] analyzed the effectiveness of an institutional intervention, which consisted of the institution’s contact with the student in order to influence the student to give up dropping out. They observed a decrease of 18% in the semester following the interventions. They also employed descriptive quantitative research with an online questionnaire with the aim of exploring the perception regarding the retention attributes. To predict dropouts using the gathered data, the authors used Radial Basis Function (RBF) neural networks and cluster analysis to group new students by similarity. Although the author had positive results, the techniques and steps for replicating the study were not detailed.
Hippel and Hofflinger [10] conducted a study to identify students at risk of dropping out at 8 Chilean public universities using Logistic Regression (LR). The authors used both personal/family data, e.g. parents’ education, high school grades, and entrance exam scores, as well as academic data collected during college. They studied the effect of programs focused on helping students adapt to university life, develop study skills and manage anxiety. The assisting programs dictated a reduction of 30–40% in the chances of dropping out in 2 of 4 universities where such programs existed. They also found the dropout risk to be inferior for older students, and for those receiving scholarships. This makes it evident there is no clear consensus on the causes of dropout, and also the variety of factors protecting against it.
In this paper, we use data as available at most Brazilian higher education institutions, including personal and academic data. We show the main steps to be considered when designing predictive models to provide educational managers a decision-making support, as well as important insight for similar initiatives in other institutions. In particular, we show there is a significant gap between analyzing historical data and future data, and specific features play a major role in this type of problem. As far as we know, this is the first paper to address a complete pipeline for a data-driven dropout risk assessment tool, including data preparation, feature selection and proper evaluation protocol, as well as feature importance analysis. Therefore, we intend this paper to shed light on the application, and serve as guideline for other higher-education institutions.
3 Data-Driven Dropout Risk Predictive Model
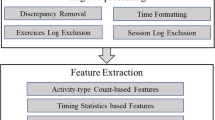
This section describes the exploration of data and the assessment of a predictive model which includes data collection from information systems, pre-processing, experiments using different subsets of the data for training and testing models using Walk-Forward Validation, as summarized in Fig. 1.

Overall flow for the design of our dropout prediction model. First, the maximum values of training data variables are computed for scaling testing data. Then the data undergoes preprocessing, always fitting on training and applying on testing. Finally, the training data is used for training the model, while the preprocessed testing data is used for evaluation.
Formally, let S be a dataset where an instance \(\textbf{s} \in S \) represents a student enrolled in a course, in a given semester, by attributes or variables with \( \gamma \) dimensions, and \( Y = \left\{ 0, 1 \right\} \) represents the label describing the student’s s situation: studying/regular (0 or negative) or avoidant (1 or positive). First, we sought to obtain a subset of the original data to pre-process, transform and obtain X that has \(\gamma \) original characteristics, and \(X' \in R^{m}\) with attributes such that \(m \le \gamma \). From the preprocessed dataset, \(X'\) supervised learning methods are used to infer \(f: X' \rightarrow Y\).
Then, S was evaluated in different subsets grouped by the current semester of the student, with the test data being used only to test the generalization of the models for a group of students of a certain semester not seen during the training.
3.1 University Data Exploration
Data Description. The UFSCar has several computational information systems for managing institutional processes. Those are separated by purpose such as: undergraduate studies; postgraduate studies; university restaurant; library, among others. The main systems used to manage academic and student data from which we gathered data were:
-
Integrated Academic Management System: responsible for the academic processes related to the student, lecturers and the main activities, such as course enrolments, registration of grades and frequencies, teaching plans, subjects, courses, among other activities;
-
Integrated University Management Support System: general management of the university including registration of people, permissions, and applications student cards;
-
Dean of Extension: management of outreach and extension courses, as well as postgraduate courses lato sensu e stricto sensu.
In order to collect and analyze the students’ academic, economic and personal data, in addition to the approval of the UFSCar ethics committee (CAAE number: 34343920.5.0000.5504), a formal request was made to the department responsible for the database, which was stored in a single database management system. To maintain data secure, the stored files were encrypted and the access to the computer and the database was granted only for authorized users.
Data Gathering. The UFSCar information technology team defined business rules related to undergraduate students in order to define the data to be gathered and integrated into a single dataset S. In this way, the source database schema was simplified by querying the target data into just two schemas, both of them totalling 222 tables and 15 views.
We follow the empirical evidence found by Pal [26], Hippel and Hofflinger [10]; and de Souza [35] for filtering relevant data to be used. Those authors indicate that personal data, academic information prior to college enrolment, academic information collected during college, as well as economic information, are sufficient to investigate college attrition and student dropout. In this paper we included:
-
Personal information: city, genre, age, color/race declared and marital status;
-
Academic information: undergraduation course, grades and frequency for each course taken, current semester, grade obtained in the national college admission test (acronym: ENEM, in Portuguese).
-
Economic and social information: category of admission (which is defined by lower income levels, if previous education was on public schools, ethnic/racial information, special needs); and also whether self-claimed to below income during registration at the college admission test.
Note that, Brazilian federal universities have affirmative actions, so that the category of admission define quotas of student places related to social/economic status of the student as well as race.
Our analysis obtained data from students who entered the UFSCar between 2008 and 2020, from all undergraduate courses offered by the institution during this period. In each year, between 2000 and 3000 students are admitted. In total, information was collected from 32.892 students, separated by course, year and period/semester.
Guidelines: include personal, academic and economic/social data available in the information systems, taking into account opinions from the information technology team, as well as the team of the dean of undergraduate students. In principle, sensible personal data should not be included, and be encoded if needed. Also, the resulting data should be encrypted and not given broad access.
3.2 Data Preparation
As we show later in results, such step significantly improves the quality of dropout prediction. Below, we describe the data preparation/cleaning and standardization in detail.
Some important characteristics of the source data to be observed when designing a Machine Learning model are:
-
1.
students in the first period still have no grades and attendance therefore cannot be used to train the model;
-
2.
there are missing values in particular for personal data, in our case for the attributes: Marital Status, Lower income and declared Color/Race;
-
3.
data for active students includes status from different academic periods (semester) of all courses, while data for those that concluded the degrees are complete, and those that abandoned are partial;
-
4.
class imbalance: around 70% of students are regularly enrolled or earned a degree, and around 30% are considered dropouts – value referring to all data collected (all years and all academic periods, including students who are out of regular period);
-
5.
Academic periods: most courses have a regular curriculum of 4 years and 8 academic periods, except for a few courses that have a curriculum of 5 years.
Data Preparation and Cleaning. Below we list the cleaning procedures carried out only when those showed to improve results in validation sets within a 10-fold cross-validation experiment using the training data only:
-
Instances removed: students without grade or attendance information recorded;
-
Attributes removed: Start year, Registration number; City of birth of the student; Name of the country; Start period; Has lower income were removed because they are not related to the classification task, possible insertion of bias, because they have missing values and/or have only one value for all students;
-
Obtaining the binary label: the original database contains different status for the student which will represent the positive label. Following the university’s guidelines, all status indicating the student left college were defined as Evader (positive), i.e.: Change of area, Cancelled, Loss of vacancy, Retired and External Transfer. On the other hand: Studying, Undergraduate Candidate, Internal Transfer, In Appeal, Graduated and Graduating were considered Studying (negative), in which the student still maintains a relationship with the university.
In addition to cleaning, we filled the null values for the features: Civil Status, Declared Color/Race, Type of School in High School, Gender, Type of Admission were filled using the value Not informed, while the features Course, Course Regime, Course City, Marital Status, Declared Color/Race, Type of High School, Nationality Type, Course Shift, Degree, Admission Type, Admission Form and Sexuality attributes were one-hot-encoded. The decision for one-hot-encoding transforming was also made based on cross-validation results.
The min-max normalization of the numerical data was applied in order to maintain the range from 0 to 1 of all values and, consequently, to avoid that larger scale variables were considered of greater importance during the training of the algorithms. The following transformations were performed: a) Expected values between 0 and 10 were divided by 10; b) Expected values between 0 and 100 were divided by 100; c) Values of Profile; Total number of courses enrolled, cancelled, approved and disapproved; Income coefficient; Workload completed and Classification obtained in Enem were divided by the maximum value found in the database. In this case, the maximum values obtained in the training of the classifiers were stored in memory and used for data normalization in the inference (test) step.
The target variable Status was designed as binary. However, the original dataset has 17 distinct status, so we grouped those into class “Dropout” (positive) for the statuses Area Change, Canceled, Loss of Vacancy, Temporary Academic Leave and External Transfer). The class “Studying” (negative) included Studying, Under Graduation Candidate, Internal Transfer, In Appeal and Forming.
Guidelines: remove instances that do not provide representative information, and study cases of missing values, filling those if those account for a significant number of instances. Convert attributes using one-hot-encoding approaches depending on their nature (categorical). Normalize the numeric data to eliminate larger scales from the values.
4 Experiments and Results
Three classification algorithms were used in the experiments: Support Vector Classification, Decision Tree (CART) and LightGBM.
We do not aim at comparing which is the best classifier, but instead use their results to understand the problem in terms of the available data and the features. The SVM offers a proxy measure for the linear separability of the classes, therefore its performance allows us to draw conclusions about the difficulty of the problem in terms of the given variables [24]. On the other hand, the Decision Tree allows understanding if it is possible to infer a single set of rules based on the features that allow to estimate dropout for all students. Finally, LightGBM [14] would be the attempt to combine several decision trees and, the more its results surpass the other methods, it means different students require different decision trees, needing different ways of shattering the feature space [27].
The following hyperparameters were used:
-
Support Vector Classification: linear kernel, cost 1 and maximum of 100 iterations;
-
Decision Tree: gini criterion, best divisor and 2 minimum samples to split;
-
LightGBM: binary target and 100 iterations.
The experiments consisted of training the models and applying the tests using the techniques of WFV (Walk-Forward Validation), in which the methodology is applied to data that have time intervals with the possibility of making good forecasts in each period. We sought to use this methodology to simulate the real scenario of application of an AM algorithm at the university, in which it will learn temporally according to the years and also, validate the behavior of the algorithms with the training of different time windows. Table 1 shows the number of instances per year and class (1st to 5th year) of the dataset used in the experiments, and Fig. 2 illustrates all the experiments performed.

Experiments carried out using the WFV methodology.
The first experiment aimed to evaluate whether the use of data from students from all previous years allows for the prediction of dropout, simulating learning from year to year successively according to the results in Table 2. The second experiment verified whether the use of data from students from the immediately previous year is sufficient to classify those from the current year, without the accumulation of all previous years, with results in Table 3. The third experiment followed the methodology of the second experiment, but with the use of instances with up to 2 years prior to the test, as shown in Table 3. Finally, we sought to assess whether the first years would provide enough signal to allow predicting dropout in instances beyond the 2nd and 3rd year, see Table 5 (Table 4).
Because the second test of the first experiment had the best result in general, a list of the most relevant features was obtained according to the LightGBM classifier. Thus, it was possible to observe that the relevant features are, for the most part, academic data and have a direct relationship with the student’s performance in the subjects and in the course. Table 6 displays the 10 features.
4.1 Discussion
-
Data engineering and processing: as in every real-world problem, and unlike databases benchmark prepared and cleaned, knowledge of the data available in the databases is necessary to extract and prepare them. The variables have different ranges, many are categorical, data have missing or inconsistencies values, and is unbalanced. Thus, it is necessary to make decisions to treat the data in order to allow the subsequent modeling;
-
Training regime: if it is necessary to obtain a model capable of predicting whether a student is a potential dropout, the training regime must consider the temporal aspect, always using past data to predict a current instance. Experiments show that accumulating all past history is beneficial for up to the third year, but for the fourth year, using only the previous year is better;
-
Predictive ability: The predictive ability is higher for students in the first and second years. From the third stage, the capacity is degraded, making it more difficult to differentiate evaders from non-evaders. For the best f1-score result in the third and fourth years, a lower recall than precision was observed, indicating a greater presence of false negatives. Thus, a specific study may be necessary to define the training set for each year;
-
Classification method: the decision tree ensemble LightGBM showed the best results. The results with SVC indicate the difficulty of finding a linear separation with the available features, in particular for the third and fourth years, confirming the conclusions about the predictive capacity. A single decision tree is also insufficient to solve the problem, so that there is no single set of rules that is suitable for all students, needing ensembles as to better tackle the problem;
-
Features: in terms of importance of features, considering the result for S2, the ENEM grade and classification is one of the most important, indicating the need for the university to have specific programs for students with grades lower and, possibly, have entered advanced calls and with the initial semester already started. The importance of the dispersion of grades and attendance (measured by the standard deviation) and the mean of attendance, indicates that the student with very different results for some subjects may be less motivated to continue. Next, it was observed the coefficient of performance, higher grade and the features that relate to how much of the course is already completed (subjects, workload and percentage), which may indicate that the greater the student’s success and the shorter the time to complete, the less likely you are to drop out. Age in years also appears to be important, showing that younger people are less likely to drop out. Finally, it is worth noting that the difficulty in a single (or a few) subjects can induce dropout as indicated by the lower grade, lower frequency and the features related to the cancellation of subjects.
About the importance of the variables and factors for dropout, Hippel and Hofflinger [10] mentioned that enrolment variables (high school grades, entrance exam grades) are not sufficient for the prediction. They also suggested the use of variables like family income, high school, first, second or third option course and financial assistance to influence the prediction. In this study, we confirm that actual academic data, directly related to the student experience during undergraduation is needed, including grades, attendance, admission modality and workload. Although we did not obtain some of the attributes related to financial aid and course option (as in [10]), as these data do not exist in the UFScar systems.
5 Conclusions
This paper offered guidelines for the design of a college dropout risk prediction model. We used real data and proposed a protocol for data preparation and a study of classification models by modelling the task as a binary classification problem. It was possible to show the difficulties of processing the data and its challenges. By using the real data available at the college database, the best results for second and third year students (which is still early allowing for interventions), had an accuracy of 0.83 and F1-Score of 0.80 (S2) and 0.83 (S3) in a realistic scenario. This represents a milestone in terms of making it viable to use as a tool in practice.
We can also interpret the results of classifiers in such context: the SVC method is comparable to the decision tree in particular for early years, which indicates there is some degree of linear separability but not sufficient to solve the problem. The LightGBM was in general better than using a single decision tree, showing that some instances might have conflicting patterns and that a single set of rules based on the available features is not sufficient to classify the students according to their risk of dropout.
Because the systems and databases studied in this paper are often available in institutions, our proposal is scalable for other educational institution that wishes to improve its college attrition management. It allows providing statistical reports for university management, as well as defining dropout risk thresholds so that to apply interventions, anticipating and avoiding dropouts.
Future work may investigate the role of fees from academic centers and evasion by type of admission. Also, we believe there is space for improvement by segmenting the data to study it in a more fine-grained level, such as into different course areas and specific degrees.
References
Abu-Oda, G.S., El-Halees, A.M.: Data mining in higher education: university student dropout case study. Int. J. Data Min. Knowl. Manage. Process 5(1), 15 (2015)
Aina, C.: Parental background and university dropout in Italy. High. Educ. 65(4), 437–456 (2013)
Aina, C., Baici, E., Casalone, G., Pastore, F.: The determinants of university dropout: a review of the socio-economic literature. Socioecon. Plann. Sci. 79, 101102 (2022)
Advisory at the Federal University of Alagoas, C.: Ufal comemora a redução do índice de evasão de estudantes de graduação. Technical report (2019). https://ufal.br/ufal/noticias/2019/10/ufal-comemora-a-reducao-do-indice-de-evasao-de-estudantes-de-graduacao
Ataíde, J., Lima, L., de Oliveira Alves, E.: A repetência e o abandono escolar no curso de licenciatura em física: um estudo de caso. Physicae 6, 21–32 (2006)
Bayer, J., Bydzovská, H., Géryk, J., Obsivac, T., Popelinsky, L.: Predicting drop-out from social behaviour of students. Int. Educ. Data Min. Soc. (2012)
Burgos, C., Campanario, M.L., de la Peña, D., Lara, J.A., Lizcano, D., Martínez, M.A.: Data mining for modeling students’ performance: a tutoring action plan to prevent academic dropout. Comput. Electr. Eng. 66, 541–556 (2018)
Casanova, J.R., Cervero Fernández-Castañón, A., Núñez Pérez, J.C., Almeida, L.S., Bernardo Gutiérrez, A.B., et al.: Factors that determine the persistence and dropout of university students. Psicothema 30 (2018)
Eisenberg, D., Gollust, S., Golberstein, E., Hefner, J.: Prevalence and correlates of depression, anxiety, and suicidality among university students. Am. J. Orthopsychiatry 77, 534–542 (2007)
Hippel, P.T.V., Hofflinger, A.: The data revolution comes to higher education: identifying students at risk of dropout in Chile. J. High. Educ. Policy Manage. 1–22 (2020)
Hooshyar, D., Pedaste, M., Yang, Y.: Mining educational data to predict students’ performance through procrastination behavior. Entropy 22(1), 12 (2020)
Huo, H., et al.: Predicting dropout for nontraditional undergraduate students: a machine learning approach. J. Coll. Student Retent.: Res. Theory Pract. 24(4), 1054–1077 (2023)
Ivankova, N.V., Stick, S.L.: Students’ persistence in a distributed doctoral program in educational leadership in higher education: a mixed methods study. Res. High. Educ. 48(1), 93–135 (2007)
Ke, G., et al.: LightGBM: a highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 30 (2017)
Kelly, J.D.O., Menezes, A.G., de Carvalho, A.B., Montesco, C.A.: Supervised learning in the context of educational data mining to avoid university students dropout. In: 2019 IEEE 19th International Conference on Advanced Learning Technologies (ICALT), vol. 2161, pp. 207–208. IEEE (2019)
Kotsiantis, S.: Educational data mining: a case study for predicting dropout-prone students. Int. J. Knowl. Eng. Soft Data Paradigms 1(2), 101–111 (2009)
Lehmann, W.: “I just didn’t feel like i fit in”: The role of habitus in university dropout decisions. Can. J. High. Educ. 37(2) (2007)
Leonhardt, D., Chinoy, S.: The college dropout crisis. The New York Times (2019). https://www.nytimes.com/interactive/2019/05/23/opinion/sunday/college-graduation-rates-ranking.html
Lozano, J.M., Rua Vieites, A., Bilbao-Calabuig, P., Casadesús-Fa, M.: University student retention: best time and data to identify undergraduate students at risk of dropout. Innov. Educ. Teach. Int. 57, 1–12 (2018)
Manhaes, L., Manhães, B., Cruz, S., Costa, M., Zavaleta, J., Silva, G.: Identificação dos fatores que influenciam a evasão em cursos de graduação através de sistemas baseados em mineração de dados: uma abordagem quantitativa. In: VIII Simpósio Brasileiro de Sistemas de Informação (2012)
Martins, L.C.B., Carvalho, R.N., Carvalho, R.S., Victorino, M.C., Holanda, M.: Early prediction of college attrition using data mining. In: 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), pp. 1075–1078. IEEE (2017)
da Matta, K.W.: Evasão Universitária Estudantil: Precursores Psicológicos do Trancamento de Matrícula por Motivo de Saúde Mental. Master’s thesis, Universidade de Brasília (2011)
Meedech, P., Iam-On, N., Boongoen, T.: Prediction of student dropout using personal profile and data mining approach. In: Lavangnananda, K., Phon-Amnuaisuk, S., Engchuan, W., Chan, J. (eds.) Intelligent and Evolutionary Systems. Proceedings in Adaptation, Learning and Optimization, vol. 5, pp. 143–155. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-27000-5_12
Mello, R.F., Ponti, M.A.: Machine Learning: A Practical Approach on the Statistical Learning Theory. Springer, Heidelberg (2018). https://doi.org/10.1007/978-3-319-94989-5
Nistor, N., Neubauer, K.: From participation to dropout: quantitative participation patterns in online university courses. Comput. Educ. 55(2), 663–672 (2010)
Pal, S.: Mining educational data using classification to decrease dropout rate of students. Int. J. Multidisc. Sci. Eng. 3, 35–39 (2012)
Ponti, M.: Combining classifiers: from the creation of ensembles to the decision fusion. In: 2011 24th SIBGRAPI Conference on Graphics, Patterns, and Images Tutorials, pp. 1–10. IEEE (2011)
Powdthavee, N., Vignoles, A.: The socio-economic gap in university dropout. BE J. Econ. Anal. Policy 9(1) (2009)
Ribeiro, M.: O projeto profissional familiar como determinante da evasão universitária: um estudo preliminar. Rev. Brasileira Orientacao Prof. 6, 55–70 (2005)
Santos, R.S., Ponti, M.A., Rodrigues, K.R.H.: Evasão universitária e estratégias para retenção de alunos com base em intervenções remotas. In: Anais Estendidos do Simpósio Brasileiro de Fatores Humanos em Sistemas Computacionais (IHC) (2022)
dos Santos Baggi, C.A., Lopes, D.A.: Evasão e avaliação institucional no ensino superior: uma discussão bibliográfica. Avaliação: Rev. Avaliação Educação Superior (Campinas) 16, 355–374 (2011)
Sarra, A., Fontanella, L., Di Zio, S.: Identifying students at risk of academic failure within the educational data mining framework. Soc. Indic. Res. 146(1), 41–60 (2019)
da Silva, P.M., Lima, M.N., Soares, W.L., Silva, I.R., Roberta, A.D.A., de Souza, F.F.: Ensemble regression models applied to dropout in higher education. In: 2019 8th Brazilian Conference on Intelligent Systems (BRACIS), pp. 120–125. IEEE (2019)
Solís, M., Moreira, T., Gonzalez, R., Fernandez, T., Hernandez, M.: Perspectives to predict dropout in university students with machine learning. In: 2018 IEEE International Work Conference on Bioinspired Intelligence (IWOBI), pp. 1–6. IEEE (2018)
de Souza, A.M.: Machine learning e a evasão escolar: análise preditiva no suporte à tomada de decisão. Master’s thesis, Faculdade de Ciências Empresariais (2020). https://repositorio.fumec.br/xmlui/handle/123456789/420
Stein, C.: The push for higher education: college attrition rates. PA Times Org (2018). https://patimes.org/the-push-for-higher-education-college-attrition-rates/
Tontini, G., Walter, S.: Pode-se identificar a propensão e reduzir a evasão de alunos? ações estratégicas e resultados táticos para instituições de ensino superior. Avaliação Rev. Avaliação Educação Superior (Campinas) 19, 89–110 (2014)
Triado, X., Sallán, J., Feixas, M., Figuera, P., Chueca, P., Fonseca, M.: Student dropout rates in catalan universities: profile and motives for disengagement. Qual. High. Educ. 20, 165–182 (2014)
Veloso, T.C.M.A., de Almeida, E.P.: Evasão nos cursos de graduação da universidade federal de mato grosso, campus universitário de cuiabá - um processo de exclusão. Série-Estudos - Perioódico Mestrado Educação UCDB (13), 133–148 (2002)
Xenos, M., Pierrakeas, C., Pintelas, P.: A survey on student dropout rates and dropout causes concerning the students in the course of informatics of the hellenic open university. Comput. Educ. 39(4), 361–377 (2002)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Santos, R.S., Ponti, M.A., Rodrigues, K.R. (2023). Analyzing College Student Dropout Risk Prediction in Real Data Using Walk-Forward Validation. In: Naldi, M.C., Bianchi, R.A.C. (eds) Intelligent Systems. BRACIS 2023. Lecture Notes in Computer Science(), vol 14195. Springer, Cham. https://doi.org/10.1007/978-3-031-45368-7_19
Download citation
DOI: https://doi.org/10.1007/978-3-031-45368-7_19
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-45367-0
Online ISBN: 978-3-031-45368-7
eBook Packages: Computer ScienceComputer Science (R0)