
Abstract
Federated Learning (FL) is a decentralized machine learning approach developed to ensure that training data remains on personal devices, preserving data privacy. However, the distributed nature of FL environments makes defense against malicious attacks a challenging task. This work proposes a new attack approach to poisoning labels using Bayesian neural networks in federated environments. The hypothesis is that a label poisoning attack model trained with the marginal likelihood loss can generate a less complex poisoned model, making it difficult to detect attacks. We present experimental results demonstrating the proposed approach’s effectiveness in generating poisoned models in federated environments. Additionally, we analyze the performance of various defense mechanisms against different attack proposals, evaluating accuracy, precision, recall, and F1-score. The results show that our proposed attack mechanism is harder to defend when we adopt existing defense mechanisms against label poisoning attacks in FL, showing a difference of 18.48% for accuracy compared to the approach without malicious clients.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others


1 Introdution
The Internet of Things (IoT) has become increasingly impactful, empowering diverse applications [14]. Approximately 5.8 billion IoT devices are estimated to be in use this year [6]. Moreover, privacy issues are becoming increasingly relevant for distributed applications, as seen recently in General Data Protection Regulation (GDPR). A decentralized machine learning approach called Federated Learning (FL) was proposed to guarantee that training data remains on personal devices and facilitates complex models of collaborative machine learning on distributed devices.
The training of a federated model is performed in a distributed fashion where data remains on users’ local devices while the model is updated globally [15]. During training, the global model is sent to users’ devices, which evaluate the model with local estimates. Furthermore, local updates are sent back to the server, aggregating them into a central model. Data privacy tends to be preserved as no actual data is shared, only model updates.
With the increasing use of machine learning algorithms in federated environments, it is necessary to ensure user data privacy and security and the constructed models’ reliability. However, the distributed nature of these environments and the heterogeneity of user data make this process challenging. Furthermore, these techniques still present vulnerabilities, as the model is trained based on data from multiple users, including potential attackers.
Developing defense strategies against malicious attacks in federated environments becomes crucial to ensure the security and privacy of users. A promising approach to this issue is the construction of malicious models that can be used to attack other models and, therefore, test the robustness of the federation. Furthermore, these malicious models are built to exploit the vulnerabilities of models in federated environments, making them helpful in evaluating the effectiveness of defense techniques.
In federated learning, neural networks are commonly used as a machine learning model due to their ability to learn and generalize complex patterns in large datasets. However, despite their promising results, neural networks have limitations that can restrict their applications, such as difficulty in model calibration and overconfidence in predictions, especially when the data distribution changes between training and testing [10].
This overconfidence problem is where neural networks exhibit excessively high confidence levels in their predictions, even when these predictions are incorrect. This happens because neural networks are trained to maximize the accuracy of their predictions without considering the uncertainty associated with the input data. As a result, neural networks may exhibit overconfidence in their predictions, even when the input data is ambiguous or noisy.
Bayesian neural networks (BNNs) are models capable of quantifying uncertainty and using it to develop more accurate learning algorithms [9]. In addition, BNNs tend to mitigate the problem of neural networks’ overconfidence [8]. This approach allows neural networks to produce a probability distribution for the output rather than just a single output, considering the uncertainty associated with the input data. This allows the network to assess its confidence in the prediction and make more informed decisions, improving its generalization and making it more robust and reliable. Although implementing Bayesian neural networks may be more complex, the advantages in terms of accuracy and confidence in their predictions are significant [11]. For example, we can see an illustration in Fig. 1, an example of the decision region of neural networks (Bayesian). In this example, we observe that BNNs present smoother decision regions, which implies more realistic confidence about predictions. Furthermore, neural networks are typically confident even in regions where the uncertainty is high, such as on the borders of regions.

Illustration of decision region of (bayesian) neural network. The dataset used in this experiment is synthetic and consists of 200 samples. Each sample has two features (2D dimension) randomly generated from a normal distribution. The output variable is determined by applying the XOR logical operation to the two input features. The goal is to train a (Bayesian) neural network model to make accurate predictions.
This work proposes a novel attack approach to poisoning labels using Bayesian neural networks in federated environments. Label poisoning attacks change training data labels, deviating the model from its original goal. As BNNs incorporate the principle of parsimony (Occam’s razor), we hypothesize that a label poisoning attack model trained using the uncertainty quantification provided by BNNs can maximize the adherence of malicious data to the model while also estimating a poisoned model with lower complexity, making it difficult to detect attacks in federated environments. This work aims to propose and evaluate this approach, presenting experimental results that demonstrate its effectiveness in generating poisoned models in federated environments.
We organized this paper as follows: Sect. 2 presents the related works to security in FL environments; Sect. 3 describes our proposal and some notations review for a good understanding of our proposal; Sect. 4 describes the experimental setup used to analyze the data; Sect. 5 presents the main results and discussions; and Sect. 6 concludes this work.
2 Related Work
The security issues in machine learning systems, and consequently federated learning, have been extensively studied [17, 21, 27]. In traditional machine learning, the learning phase is typically protected and centralized in a unique system [13]. Specifically, the approaches in literature usually consider that malicious clients act during inference, i.e., the attacked model is already in production [12]. In FL, malicious clients usually exploit the vulnerability of the models during the learning phase [3]. In general, malicious clients attacking an FL model have one of two adversarial goals:
-
Case I.
Reconstruct or learn client/model information based on data transmitted in the federated training process, and
-
Case II.
Force the model to behave differently than intended, invalidate or train it for a specific purpose (e.g., poisoning attack).
In this proposal, we focus on the problems related to attacks that aim to degrade the performance of the aggregated model (type II attacks), especially in the untargeted attack. Among these types of attacks, data poisoning (i.e., poisoning in the training dataset) is one of the most common forms of poisoning attack.
Several works in the literature propose a poisoning attack method to FL models to degrade the training process. Zhang et al. [25] propose using generative adversarial networks (GANs) to generate examples without any assumption on accessing the participants’ training data. Similarly, Zhang et al. [26] then inserts adversarial poison samples assigned with the wrong label to the local training dataset to degrade the aggregate model. Sun et al. [19] studies the vulnerability of federated learning models in IoT systems. Thus, the authors use a bilevel optimization consideration, which injects poisoned data samples to maximize the deterioration of the aggregate model. In addition, Defense mechanisms for distributed poisoning attacks typically draw ideas from robust estimation and anomaly detection [1, 18]. Some works are based on aggregation functions robust to outliers, such as median [22], mean with exclusion [23], geometric mean [16], and clustering of nearby gradients [4].
Additionally, assuming scenarios, where all clients train the network model but use their data is paramount. More often than not, we observe that data models differ across clients. Therefore, the resulting models will be abstractions of different real-world conditions. Ultimately, we need to propose solutions that handle such situations bearing in mind the challenges of accounting for such differences without considering them malicious, especially when only a small subset of clients present data models apart from the majority.
3 Our Proposal
3.1 Bayesian Neural Network
A BNN is a neural network \(f(\textbf{x}, \textbf{w})\) that maps inputs \(\textbf{x}\) to outputs y, where \(\textbf{w} \in \mathbb {R}^{M}\) is a vector of random variables representing the weights and biases of the network. The BNN assumes a prior distribution over \(\textbf{w}\), denoted \(p(\textbf{w})\), and learns a posterior distribution \(p(\textbf{w}\mid \mathcal {D})\) over the weights and biases given the training data \(\mathcal {D} = \{(\textbf{x}_i, y_i)\}_{i=1}^N\). Thus, for a dataset \(\mathcal {D}\), we have \(p(\mathcal {D} \mid {\textbf {w}}) = \varPi _{i=1}^N p(y_i \mid f({\textbf {x}}_i, {\textbf {w}}))\). Bayesian inference techniques such as Markov Chain Monte Carlo (MCMC), variational inference, and Laplace approximation can approximate the posterior distribution.
Given the posterior distribution, the network can make predictions by computing the predictive distribution \(p(y\mid \textbf{x}, \mathcal {D})\) over the output given the input and the training data. The BNN approach provides a probabilistic framework for modeling uncertainty in the network’s predictions and can be particularly useful in applications where knowing the level of uncertainty is essential. In addition, the regularization effect of the prior distribution can also prevent overfitting and improve the generalization performance of the network.
3.2 Laplace Approximation
In Bayesian inference, we are interested in computing the posterior distribution of the model parameters \({\textbf {w}}\) given the observed data \(\mathcal {D}\), which is given by
where \(p(\mathcal {D} \mid {\textbf {w}})\) is the data likelihood, \(p({\textbf {w}})\) is the prior distribution of the parameters, and the integral in the denominator is the normalization constant.
Unfortunately, \(\int p(\mathcal {D} \mid {\textbf {w}}) p({\textbf {w}})d{\textbf {w}}\) is often intractable for complex models (as neural networks), and we need to resort to approximate inference methods. One such method is the Laplace approximation, which approximates the posterior distribution with a Gaussian distribution centered at the mode of the posterior, \({\textbf {w}}_{MAP}\) (maximum a posterior), and with a covariance matrix given by the inverse Hessian matrix evaluated at \({\textbf {w}}_{MAP}\).
To derive the Laplace approximation, we start by manipulating the integral in the denominator \(\int p(\mathcal {D} \mid {\textbf {w}}) p({\textbf {w}})d{\textbf {w}} = \int \exp (\log p(\mathcal {D}, {\textbf {w}})) d{\textbf {w}}\). Next, we use the second-order Taylor expansion of \(\log p(\mathcal {D}, {\textbf {w}})\) around \({\textbf {w}}_{MAP}\):
where \(g_{MAP} = - \nabla \log p({\textbf {w}} \mid \mathcal {D})\mid _{{\textbf {w}} = {\textbf {w}}_{MAP}} \) is the gradient of \(\log p(\mathcal {D}, {\textbf {w}})\) evaluated at \({\textbf {w}}_{MAP}\), and \({\textbf {H}}_{MAP} = - \nabla \nabla \log p({\textbf {w}} \mid \mathcal {D}) \mid _{{\textbf {w}} = {\textbf {w}}_{MAP}}\) is the Hessian matrix evaluated at \({\textbf {w}}_{MAP}\). Using the Laplace approximation, we approximate the marginal likelihood \(p(\mathcal {D})\) as
Since the integral is Gaussian, we can solve it analytically and obtain
where M is the dimensionality of \({\textbf {w}}\). Using this approximation, we can obtain the posterior distribution \( p({\textbf {w}} \mid \mathcal {D}) \approx \mathcal {N} ({\textbf {w}} \mid {\textbf {w}}_{MAP}, {\textbf {H}}_{MAP}^{-1}), \) where \(\mathcal {N} ({\textbf {w}} \mid {\textbf {w}}_{MAP}, {\textbf {H}}_{MAP}^{-1})\) denotes a multivariate Gaussian distribution with mean \({\textbf {w}}_{MAP}\) and covariance matrix \({\textbf {H}}_{MAP}^{-1}\) [11]. Therefore, the Laplace approximation allows us to approximate the posterior distribution of the weights as a Gaussian distribution, which can be more computationally efficient than the full posterior distribution.

Illustration of the Laplace approximation applied to the distribution \(p(z) \propto \exp \left( -z^2/2\right) \sigma (20z + 4)\) where \(\sigma (z)\) is the logistic sigmoid function defined by \(\sigma (z) = (1 + e^{-z})^{-1}\). Figure (a) shows the normalized distribution p(z), together with the Laplace approximation centered on the mode \(z_0\) of p(z). Figure (b) shows the negative logarithms of the corresponding curves. (Color figure online)
3.3 Occam Razor and Marginal Likehood
The marginal likelihood automatically encapsulates a notion of Occam’s Razor. To illustrate this, we estimate Laplace approximation to find a Gaussian approximation to a probability density defined over a set of continuous variables. We can see a toy example for Laplace approximation in Fig. 2.
Figure 2 (a), the normalized distribution p(z) is shown alongside the Laplace approximation centered on the mode \(z_0\) of p(z). The Laplace approximation, depicted by the orange curve, is a Gaussian distribution that closely matches the original distribution near the mode \(z_0\). This approximation is commonly employed to simplify calculations and provide a more manageable representation of complex problems.
Figure 2 (b) presents the negative logarithms of the corresponding curves. The logarithmic scale enhances subtle differences between the curves. Notably, the Laplace approximation (orange line) exhibits a similar fit to the original curve (blue line) near the mode \(z_0\). This Figure effectively showcases the application of Laplace approximation for estimating a Gaussian distribution that effectively approximates a complex probability distribution.
We can consider the log of the Laplace Marginal Likelihood (LML) in Eq. 2 as
The relationship between Occam’s Razor and Laplace Approximation is deeply rooted in the theory of Bayesian inference. Laplace Approximation is a technique that allows us to approximate a probability distribution with a Gaussian distribution around the maximum a posteriori point. The maximum a posteriori point is often interpreted as the most likely solution to a given modeling problem.
Occam’s Razor, on the other hand, is a philosophical principle that states that if there are several possible explanations for a given set of observations, the simplest explanation is the most likely. In Bayesian inference theory, this translates into the fact that when making inferences about a model, we should prefer simpler and less complex models unless there is clear evidence on the contrary.
When we consider Eq. 3 as our loss function for training the neural network, we realize that maximizing the fit of the model’s marginal likelihood corresponds to increasing the value \(\log p(\mathcal {D}, {\textbf {w}}_{\text {MAP}})\) and minimizing the complexity term \(\log |{\textbf {H}}_{MAP}|\). The complexity term depends on the log determinant of the Laplace posterior covariance. Therefore, if \(\log |{\textbf {H}}_{MAP}|\) is large, the model strongly correlates with the training data [11]. So, maximizing the Laplace \(\log p(\mathcal {D})\) requires maximizing the data fit while minimizing the training sample correlation.
The Laplace Approximation implements Occam’s Razor as we make the simplest possible assumption about the posterior distribution. Furthermore, the Laplace Approximation has been used in many applications, including training machine learning models in federated environments where data privacy is critical. In these scenarios, it is essential to have a model that can generalize well from a small dataset. The Laplace Approximation can help achieve this goal by providing a way to regularize the model and avoid overfitting.
3.4 Federated Learning

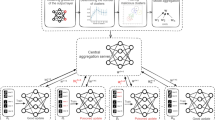
Left: Conventional (client-server) federated learning scheme. Right: Training of a simple data flow model in federated learning.
In federated learning, users collaboratively train a machine learning model without sharing their raw data. The process consists of three main steps, as can see in Fig. 3:
-
– (Step 1)
Task initialization: The system initializes the local models and necessary hyperparameters for the learning task. Each user prepares their local model using their respective dataset.
-
– (Step 2)
Local model training and update: Each user independently trains their local model using their local data. The goal is to find the optimal parameters that minimize the loss function specific to their dataset. This step ensures that each user’s model is tailored to their data and captures their local patterns.
-
– (Step 3)
Model aggregation and update: The server aggregates the local models from selected participants and generates an updated global model, often referred to as the federated model. The aggregation process typically involves combining the model parameters of the local models . The global model is then sent back to the users for further iterations.
Steps 2 and 3 are repeated iteratively until the aggregate loss function converges or reaches a desired training metric. The iterative nature of the process allows the global model to improve over time by leveraging the collective knowledge from all participating users while maintaining data privacy.
3.5 Model Attack
Federated learning, a distributed learning paradigm, allows multiple clients to collaboratively train a global model without sharing their raw data. However, this collaborative nature makes federated learning vulnerable to malicious attacks.
Before launching our attack on federated learning, an attacker must go through several steps: (i) Firstly, in the attack preparation phase, the attacker injects poisoned labels into the corrupted local data, introducing inaccurate label assignments to the training examples; (ii) Secondly, each local malicious client trains a local malicious model using the corrupted dataset. The malicious model is trained by minimizing a loss function that incorporates the maximization of marginal likelihood using the Laplace approximation. This approach takes advantage of the over-parameterized nature of modern classifiers, enabling them to fit the corrupted data easily [2]; and (iii) Finally, during the global model update process, the local models are aggregated to form the updated global model. In the aggregation step, honest and malicious updates construct the aggregated model. By understanding these steps, we can learn how malicious models exploit the federated learning framework to undermine its integrity and compromise the global model’s performance and reliability. We can describe our proposal as follows:
-
Attack Preparation. The attacker injects poisoned labels into the corrupted local data, introducing inaccurate label assignments to the training examples:
-
Step (a) Let \(\mathcal {D}_i = \{(\textbf{x}_{1}, y_{1}), (\textbf{x}_{2}, y_{2}), \cdots , (\textbf{x}_{n}, y_{n})\}\) be the local dataset of client i, where \(x_{j}\) is an input and \(y_{j}\) is the true label.
-
Step (b) Let \(\alpha \in [0, 1]\) represent the fraction of random poisoned samples in local malicious data \(\mathcal {D}'_i\).
-
Step (c) The attacker replaces a fraction \(\alpha \) of the true labels \(y_{j}\) with random poisoned labels \(y'_{j}\).
-
-
Malicious Model. Each local malicious client trains a local malicious model using the corrupted dataset \(\mathcal {D}'_i\):
-
Step (a) Let \(f(\textbf{x},\, \textbf{w}_i)\) denote the local model of client i, parameterized by \(\textbf{w}_i\). The malicious model is trained by minimizing a loss function that incorporates the maximization of marginal likelihood using the Laplace approximation. Also, note that honest clients are trained using the usual cross-entropy loss.
-
Step (b) The malicious loss function used is the Laplace Marginal Likelihood loss (Eq. 3), defined as
$$\begin{aligned} \mathcal {L}_{\text {LML}}({\textbf {w}}_i) &= \log p(\mathcal {D}_i, {\textbf {w}}^*_{\mathcal {D}_i}) + \frac{M_i}{2} \log (2\pi ) - \frac{1}{2} \log |{\textbf {H}}^*_{\mathcal {D}_i}|, \end{aligned}$$where \(\mathcal {D}_i\) is the corrupted local dataset, \(\log p(\mathcal {D}_i, {\textbf {w}}_i)\) is the Laplace approximation (Eq. 1), \({\textbf {w}}_{\mathcal {D}_i}^*\) refers to the maximum a posterior (MAP), \(M_i\) is the dimensionality of \({\textbf {w}}_i\), and \(\log |{\textbf {H}}^*_{\mathcal {D}_i}|\) is the logarithm of the determinant of the Hessian matrix.
-
Step (c) Maximizing the marginal likelihood promotes the fitting of the corrupted data, while the regularization term controlled by \(\log |{\textbf {H}}^*_{\mathcal {D}_i}|\) limits the model’s complexity. Modern classifiers are heavily over-parameterized [2]. Thus, these models easily fit a random poisoning labeling of the training data and, consequently, present a high Memorization gap [24].
-
-
Aggregation. During the global model update process in federated learning, the local models are aggregated to form the updated global model:
-
step (a) The local models are combined using an aggregation technique; for example, the weighted average of the local model parameters as
$$ {\textbf {w}}_{Fed} \xleftarrow []{} {\textbf {w}}_{Fed} + \underbrace{\eta \sum _{u_i \in S } \left[ p_i ( {\textbf {w}}_{\mathcal {D}_i}^* - {\textbf {w}}_{Fed})\right] }_{\text {Honest updates}} + \underbrace{\eta \sum _{m_i \in S' } \left[ p_i ( {\textbf {w}}_{\mathcal {D}'_i}^* - {\textbf {w}}_{Fed})\right] ,}_{\text {Malicious updates}} $$where \(S'\) and S denote the set of selected malicious and benign clients for training, respectively; \({\textbf {w}}_{\mathcal {D}'_i}^*\) and \({\textbf {w}}_{\mathcal {D}_i}^*\) refers to the maximum a posterior (MAP) estimate of the malicious and honest model parameters, respectively; and \({\textbf {w}}_{Fed}\) is the aggregated or global model that is constructed by combining the local model updates from multiple clients.
-
4 Methodology
4.1 Dataset
To analyze the federated performance, we used the EMNIST dataset, a collection of handwritten characters with over 800,000 images. This unique dataset combines two popular datasets, the MNIST dataset and the NIST Special Database 19, to create a more extensive and diverse collection of handwritten characters. The dataset contains handwritten characters from 62 classes, including uppercase and lowercase letters, digits, and symbols. It is a valuable resource for researchers and developers interested in optical character recognition (OCR) and related applications.
The images in the EMNIST dataset are grayscale and have a 28 by 28 pixels resolution. To prepare the data for training, we performed a min-max normalization on all input features to scale the values between 0 and 1, ensuring that no individual feature would dominate the learning process.
4.2 Model Evaluation
We use the framework Flower to develop solutions and applications in federated learning. We perform a non-iid data distribution among the users in this experiment. We randomly distribute the data in a non-uniform way (quantity-based label imbalance) [15].
We employ a server and 100 clients to evaluate our model, and we trained our method with an NVIDIA Quadro RTX 6000 GPU (24 GB) for a total of 100 epochs (server). For each training round, the server selects five clients to train the local model, i.e., each model is trained using only the local data. Finally, the models are aggregated on the central server, which forwards the aggregated model to the clients.
For simplicity, we consider uncorrelated noise for the poisoning label attack (all labels are equally likely to be corrupted). We use \(10\%\) as the system noise level (ratio of noisy clients). Each malicious client generates \(\alpha = 50\%\) of corrupt label data, i.e., even a malicious client produces \(50\%\) of correct labels.
4.3 Network Architecture
The neural network architecture consists of two main parts: a convolutional layer and a fully connected layer. The convolutional layer is responsible for extracting features from the input data. It consists of four convolutional layers with ReLU activation functions and max pooling layers, which reduces the spatial dimensions of the output. The first convolutional layer has 32 filters, followed by a layer with 64 filters. The subsequent two layers have 128 filters each. The fully connected layer takes the output of the convolutional layer and maps it to the output classes. It consists of two linear layers, with 1024 and 26 neurons, respectively. The model uses Stochastic Gradient Descent (SGD) with momentum optimization with a learning rate of 0.01 and a momentum of 0.9. This architecture was used to classify characters in the EMNIST dataset.
5 Results
In this work, in order to perform a quantitative comparison, we compared our approach in different evaluation scenarios. Therefore, we considered six experiments with five techniques for mitigating attacks in federated environments and FedAvg aggregation. More specifically, we have the following:
-
FedAvg [15] is a method that uses the weighted average of local models to obtain a more accurate global model. The FedAvg aggregation is a widespread technique in FL due to its effectiveness and simplicity of implementation.
-
FedEqual [5] equalizes the weights of local model updates in FL, allowing most benign models to counterbalance malicious attackers’ power and avoid excluding local models.
-
Geometric [16] uses the geometric mean of the local models to obtain a global model that is more robust to outliers. Geometric aggregation is an alternative technique to FedAvg aggregation, which can be more effective in specific applications.
-
Krum [4] is a robust aggregation rule that uses a Euclidean distance approach to select similar model updates. This method calculates the sum of squared distances between local model updates and then selects the model update with the lowest sum to update the parameters of the global model.
-
Norm [20] consists of calculating a normalization constant for model updates by clients to normalize the contribution of any individual participant. So, all model updates are averaged to update the joint global model.
-
Trimmed [23] can be defined as the average of the local models but removes a proportion of the local models, including outliers, that may negatively affect the aggregation. Trimmed aggregation is a technique that can improve the effectiveness of model aggregation in FL systems, especially when there is a significant variation in the local data.
On the other hand, besides our proposed attack, we evaluated our federation using four attack proposals in federated environments in addition to the standard proposal without malicious clients for each of the six experiments:
-
None: Approach without any malicious client.
-
FedAttack [22]: Uses a contrastive approach to group corrupted samples into similar regions. The authors propose to use globally hardest sampling as a poisoning technique. However, the technique involves malicious clients using their local user embedding to retrieve globally hardest negative samples and pseudo “hardest positive samples” to increase the difficulty of model training.
-
Label [22]: Label flipping attack approach that randomly flips the labels of the malicious client’s dataset and trains on the contaminated dataset using cross-entropy loss.
-
Stat-opt [7]: Attack that consists of adding constant noise with opposite directions to the average of benign gradients.
Note que the malicious clients in FedAttack, Label, and Our proposal only modify the input samples and their labels. At the same time, the model gradients are directly computed on these samples without further manipulation. Finally, Table 1 displays the performance of the described defense mechanisms against various attacks in federated learning. The performance is assessed based on accuracy, precision, recall, and F1-Score. The best performance is highlighted in bold in each category. It is worth noting that the proposed attack model aims to maximize its success rate. Thus a lower performance is better in comparison to other defense proposals.
Initially, we verified that the “Label” approach is a simplified version of our proposed attack, using the usual cross-entropy loss in a label attack. In contrast, our proposal uses a Bayesian neural network trained with marginal likelihood. The results show that our attack proposal is more effective than the Label approach. In all defense scenarios, our proposal had a lower performance, i.e., our proposal was able to reduce accuracy, precision, recall, and F1-score significantly. The results also show that the performance of defense mechanisms varies according to the attack proposal and the type of defense used. For example, the “FedAvg” defense was less effective against label attacks than other defense proposals. In general, our attack proposal proved more effective in all scenarios, regardless of the type of defense used compared to the Label attack approach.
For the other approaches, compared to the FedAvg defense proposal, the results show that the Stat-opt proposal had the best attack performance, with an accuracy of 0.584, precision of 0.593, recall of 0.581, and F1-Score of 0.587. In the second place, we observed that Our proposal had slightly better performance than the “FedAttack” model, with an accuracy of 0.603, precision of 0.632, recall of 0.607, and F1-Score of 0.595. A similar conclusion was observed for the FedEqual defense strategy. Finally, however, we noticed that for the Recall metric, our proposal had better performance (being more effective in degrading this metric in the federation result).
For the Geometric defense strategy, we observed that our approach achieved the highest degradation of the model. For the accuracy metric, our model obtained 0.701, showing a difference of 18.48% when compared to the approach without malicious clients. The second-best attack proposal achieved a degradation of 8.02% compared to the model without any attack (None). We observed that this behavior is consistent for the other metrics, where our approach achieved a precision of 0.707, recall of 0.703, and F1-Score of 0.705. We also observed similar behavior for the Krum, Norm, and Trimmed experiments, indicating that the attack strategy significantly impacted the defense mechanisms’ performance.
Based on the results, our proposed approach was superior in four scenarios, while the stat-opt proposal was better in only two. This conclusion happens because the Stat-opt proposal manipulates the gradient to attack the model, while our approach only performs a label change attack. Manipulating the gradient allows the stat-opt approach to have finer control over changes made to model weights, making the attack more effective. Furthermore, the stat-opt approach can exploit the model’s internal structure, which can lead to more sophisticated and challenging to detect attacks, unlike our approach, which only performs a label change attack. However, our proposed approach outperformed the other defense mechanisms in the remaining scenarios. This indicates that our approach is more effective for attacking federated learning models than the label attack in the stat-opt proposal. Overall, our approach is a powerful tool for evaluating the robustness of federated learning models and improving their defenses against label change attacks.
6 Conclusion
This paper proposes a new labeling attack model for federated environments using Bayesian neural networks. The approach is based on a model trained with the marginal likelihood loss function that maximizes the adherence of malicious data to the model while also estimating a poisoned model with lower complexity, making it difficult to detect attacks in federated environments. In federated environments, it is essential to ensure the security and privacy of user data and the reliability of built models. However, machine learning techniques in federated environments still present vulnerabilities since the model is trained based on data from multiple users, including possible attackers.
The evaluation of different defense mechanisms against various attacks in federated learning showed that the performance of defense mechanisms varies according to the attack proposal and the type of defense used. However, in general, our proposed attack was more effective in all scenarios. The results also showed that the proposed attack method was highly influential in degrading the model’s performance. Therefore, it is crucial to consider the proposed attack model when designing defense mechanisms for federated learning systems. Furthermore, the findings suggest that future research should focus on developing more effective defense mechanisms to mitigate the risks associated with the proposed attack.
References
Alistarh, D., Allen-Zhu, Z., Li, J.: Byzantine stochastic gradient descent. In: Advances in Neural Information Processing Systems, vol. 31. Curran Associates, Inc. (2018)
Bansal, Y., et al.: For self-supervised learning, rationality implies generalization, provably. In: International Conference on Learning Representations (ICLR) (2020)
Bhagoji, A.N., Chakraborty, S., Mittal, P., Calo, S.: Analyzing federated learning through an adversarial lens. In: International Conference on Machine Learning (ICML), vol. 97 (2019)
Blanchard, P., El Mhamdi, E.M., Guerraoui, R., Stainer, J.: Machine learning with adversaries: Byzantine tolerant gradient descent. In: Advances in Neural Information Processing Systems (NeurIPS), vol. 30 (2017)
Chen, L.Y., Chiu, T.C., Pang, A.C., Cheng, L.C.: Fedequal: defending model poisoning attacks in heterogeneous federated learning. In: 2021 IEEE Global Communications Conference (GLOBECOM), pp. 1–6 (2021)
Dao, N.N., et al.: Securing heterogeneous IoT with intelligent DDoS attack behavior learning. IEEE Syst. J. 16(2), 1974–1983 (2022)
Fang, M., Cao, X., Jia, J., Gong, N.Z.: Local model poisoning attacks to byzantine-robust federated learning. In: Proceedings of the 29th USENIX Conference on Security Symposium (SEC) (2020)
Gal, Y., Ghahramani, Z.: Dropout as a Bayesian approximation: representing model uncertainty in deep learning. In: Proceedings of the 33rd International Conference on Machine Learning (ICML) (2016)
Ghahramani, Z.: Probabilistic machine learning and artificial intelligence. Nature 521(7553), 452–459 (2015)
Guo, C., Pleiss, G., Sun, Y., Weinberger, K.Q.: On calibration of modern neural networks. In: Proceedings of the 34th International Conference on Machine Learning, ICML 2017 (2017)
Immer, A., et al.: Scalable marginal likelihood estimation for model selection in deep learning. In: International Conference on Machine Learning (ICML), vol. 139, pp. 4563–4573 (2021)
Jagielski, M., Oprea, A., Biggio, B., Liu, C., Nita-Rotaru, C., Li, B.: Manipulating machine learning: poisoning attacks and countermeasures for regression learning. In: 2018 IEEE Symposium on Security and Privacy (SP), pp. 19–35 (2018)
Lamport, L., Shostak, R., Pease, M.: The byzantine generals problem. ACM Trans. Programm. Lang. Syst. 4(3), 382–401 (1982)
Li, T., Sahu, A.K., Talwalkar, A., Smith, V.: Federated learning: challenges, methods, and future directions. IEEE Signal Process. Mag. 37, 50–60 (2020)
McMahan, B., Moore, E., Ramage, D., Hampson, S., Arcas, B.A.: Communication-efficient learning of deep networks from decentralized data. In: Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), pp. 1273–1282 (2017)
Pillutla, K., Kakade, S.M., Harchaoui, Z.: Robust aggregation for federated learning. IEEE Trans. Signal Process. 70, 1142–1154 (2022)
Rodríguez-Barroso, N., Martínez-Cámara, E., Luzón, M.V., Herrera, F.: Dynamic defense against byzantine poisoning attacks in federated learning. Future Gener. Comput. Syst. 133, 1–9 (2022)
Shejwalkar, V., Houmansadr, A., Kairouz, P., Ramage, D.: Back to the drawing board: a critical evaluation of poisoning attacks on production federated learning. In: 2022 IEEE Symposium on Security and Privacy (SP), pp. 1354–1371 (2022)
Sun, G., Cong, Y., Dong, J., Wang, Q., Lyu, L., Liu, J.: Data poisoning attacks on federated machine learning. IEEE Internet Things J. 9(13), 11365–11375 (2022)
Sun, Z., Kairouz, P., Suresh, A.T., McMahan, H.B.: Can you really backdoor federated learning? (2019)
Wang, H., et al.: Attack of the tails: yes, you really can backdoor federated learning. In: Proceedings of the 34th International Conference on Neural Information Processing Systems (NeurIPS). Red Hook, NY, USA (2020)
Wu, C., Wu, F., Qi, T., Huang, Y., Xie, X.: Fedattack: effective and covert poisoning attack on federated recommendation via hard sampling. In: Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), pp. 4164–4172, New York, NY, USA (2022)
Yin, D., Chen, Y., Kannan, R., Bartlett, P.: Byzantine-robust distributed learning: towards optimal statistical rates. In: Proceedings of the International Conference on Machine Learning, vol. 80, pp. 5650–5659 (2018)
Zhang, C., et al.: Understanding deep learning (still) requires rethinking generalization. Commun. ACM 64(3), 107–115 (2021)
Zhang, J., Chen, B., Cheng, X., Binh, H.T.T., Yu, S.: PoisonGAN: generative poisoning attacks against federated learning in edge computing systems. IEEE Internet Things J. 8(5), 3310–3322 (2021)
Zhang, J., Chen, J., Wu, D., Chen, B., Yu, S.: Poisoning attack in federated learning using generative adversarial nets. In: 2019 18th IEEE International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom/BigDataSE), pp. 374–380 (2019)
Zhao, M., An, B., Gao, W., Zhang, T.: Efficient label contamination attacks against black-box learning models. In: Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI), pp. 3945–3951 (2017)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Barros, P.H., Murai, F., Ramos, H.S. (2023). Bayes and Laplace Versus the World: A New Label Attack Approach in Federated Environments Based on Bayesian Neural Networks. In: Naldi, M.C., Bianchi, R.A.C. (eds) Intelligent Systems. BRACIS 2023. Lecture Notes in Computer Science(), vol 14195. Springer, Cham. https://doi.org/10.1007/978-3-031-45368-7_29
Download citation
DOI: https://doi.org/10.1007/978-3-031-45368-7_29
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-45367-0
Online ISBN: 978-3-031-45368-7
eBook Packages: Computer ScienceComputer Science (R0)