
Abstract
Pre-trained Transformer models have been used to improve the results of several NLP tasks, which includes the Legal Rhetorical Role Labeling (Legal RRL) one. This task assigns semantic functions, such as fact and argument, to sentences from judgment documents. Several Legal RRL works exploit pre-trained Transformers to encode sentences but only a few employ approaches other than fine-tuning to improve the performance of models. In this work, we implement three of such approaches and evaluate them over the same datasets to achieve a better perception of their impacts. In our experiments, approaches based on data augmentation and positional encoders do not provide performance gains to our models. Conversely, the models based on the DFCSC approach overcome the appropriate baselines, and they do remarkably well as the lowest and highest improvements respectively are 5.9% and 10.4%.
This work was supported by NPAD/UFRN, by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - Brasil (CAPES, Finance Code 001) and by the LawBot project (ANR-20-CE38-0013), granted by ANR the French Agence Nationale de la Recherche.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others
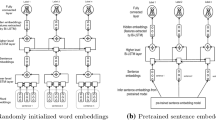


1 Introduction
One of the main goals of Legal AI, the application of Artificial Intelligence (AI) in the legal domain, is task automation, which increases the productivity of legal professionals and makes the law more accessible. Several works related to Legal AI are about tasks concerning judgments such as judgment prediction [14, 24], and legal summarization [7, 9], which rely on judgment documents as the main source of data. A judgment document is a record of a lawsuit authored by the Court that sets forth its decision about the case. The document includes such as statements of the facts, analysis of relevant law, rights and liabilities of the parties, and rulings, among others.
Specific information is required or can be exploited to boost Legal AI tasks: facts for fact-based search; facts and violated statutes for judgment prediction; facts, arguments, and judicial reasoning for legal summarization. The Legal Rhetoric Role Labeling (Legal RRL) task assigns semantic functions to sentences in judgment documents (e.g., fact, argument, ruling). Thus, Legal RRL is a way of finding information that is useful in itself as well as for downstream tasks. The Legal RRL task is not trivial, even for humans. One of the limiting factors is the heterogeneity in the structure of documents. It is common for a lawsuit to be judged by different courts (e.g., lower courts, supreme court), which may adopt different standards or guidelines to write judgment documents. Another issue is the subjectivity related to the interpretation of different rhetorical roles [3, 15]. Inter-annotator agreements reported from works about the development of Legal RRL datasets are good evidence of such subjectivity. In [15], the authors report a low inter-agreement score (Kappa index is 0.65) among three annotators on judgments from the income tax domain over 1,600 sentences. Similarly, in [8] a low inter-agreement score (Kappa index is 0.59) is reported for 40,305 sentences and 30 annotators.
Legal RRL automation can be implemented as a sentence classification task, where sentences are fed into a machine learning model that assigns a label to each sentence. The model consists of two core components, a sentence encoder and a classifier. The sentence encoder is responsible to produce numeric representations (i.e., vectors), commonly known as sentence embeddings, of text sentences while the classifier assigns labels to each representation as illustrated in Fig. 1.

Sentence classification task.
The representation vectors directly impact the performance of the model since richer representations lead to more precise classifications [21]. The exploitation of pre-trained Transformer models [20] is the current state-of-the-art in many NLP tasks and this includes the sentence encoding one. Several pre-trained Transformer models are publicly available, such as BERT [5] and RoBERTa [13]. When generating the vector representation of a word w in a sentence, a Transformer model takes w and its neighbor words into account. Therefore, it yields different vector representations for w when it occurs in different sentences or different positions of the same sentence. This context exploitation ability allows the model to yield rich text representations.
Fine-tuning is a common procedure for exploiting pre-trained Transformers that adjusts the weights of a pre-trained model for a specific task and dataset. This is a general procedure and it can be employed to tackle the Legal RRL task [1, 3, 8, 18]. Some recent works [10,11,12, 15] propose additional procedures as a way of improving the performance of models handling the Legal RRL task but, despite their potential, such works employ different datasets what hinders a fair comparison. In this context, the goal of this work is to perform an equitable comparison among approaches proposed in recent works [10,11,12, 15]. To achieve this, we implement models based on three of such approaches and evaluate them over two datasets. Only the DFCSC-based models overcome the appropriate baselines, and they do so remarkably well: the lowest and highest improvements respectively are 5.9% and 10.4%.
2 Recent Approaches to Handle Legal RRL
Pre-trained Transformer models have achieved remarkable results in many NLP tasks. Thus, it is not a surprise the publication of Legal RRL works that rely on such models [1, 3, 8, 18]. Fine-tuning is a common training procedure for one working with pre-trained models, whose goal is the adjustment of the model weights to the task at hand. A pre-trained Transformer model can be employed out-of-the-box (i.e., without fine-tuning) but since the task at hand is mostly different from the task used in its pre-training, the fine-tuning improves the performance of the model. Other training procedures can be employed together with the fine-tuning one as a way of improving the performance of a model. Regarding the Legal RRL task, there are a few recent works that follow this strand.
Mixup [23], a data augmentation technique, is exploited in [10] to augment the training set and hence improve model performance. Mixup relies on the weighted interpolation of two inputs to generate a synthetic vector as defined by the following equations:
where \(\textbf{x}_{i}\) and \(\textbf{x}_{j}\) are sentence embedding vectors, e is the embedding dimension, \(\textbf{y}_{i}\) and \(\textbf{y}_{j}\) are one-hot label encodings, and |L| is the number of labels or classes. \((\textbf{x}_{i}, \textbf{y}_{i})\) and \((\textbf{x}_{j}, \textbf{y}_{j})\) are two examples drawn at random from the training data and \(\lambda \) is a value in the interval [0, 1] drawn at random from a Beta\((\alpha ,\alpha )\) distribution, where \(\alpha > 0\). In their setup [10], the authors exploit Sentence BERT [17] as an encoder without fine-tuning. The exploited dataset comprises 60 judgments, 10,024 sentences, and seven rhetorical roles. As a result, the Mixup-based models overcome the respective baselines in terms of F1 score. For example, a linear classifier achieves a gain of 4.3% in the worst case and 6.8% in the best case.
Another work [12] leverages positional information in addition to encoded sentences. Each sentence is represented by a sentence embedding and a positional embedding, the latter indicating the position a sentence occupies in its source document. Positional embeddings are computed by the same sinusoidal positional encoding method exploited in the original Transformer architecture [20]:
where pos is an integer indicating the position of a sentence, k is a dimension of a \(\textbf{PE}\) vector where \(0 \le k < (e-1)/2\), e is the embedding dimension, and m is the max number of sentences in a document. The sentence and positional embeddings must be combined before being fed to the models’ classifier and to do this the authors employ vector sum and vector concatenation. In their setup [12], they experiment with four pre-trained Transformers as sentence encoders. The exploited dataset comprises 369 judgments, 54,244 sentences, and two rhetorical roles. The authors report gains from 3.3% to 12.6% achieved by fine-tuned models.
The approaches presented in [10, 12] rely on the single sentence classification paradigm: a sentence is encoded in isolation and so its context (neighbor sentences) is ignored. Although, Transformers are notable for exploiting context to encode sentences and thus the work of [11] leverages this ability to produce richer sentence embeddings as a way to achieve better results. The encoder is fed with chunks of sentences and a special character is employed to signal sentences’ limits. The authors propose a chunk layout and an assembly procedure, named DFCSC (Dynamic-filled Contextualized Sentence Chunk), that avoids the use of padding tokens, the truncation of core sentences, and that defines at run time the number of core sentences and edge tokens in each chunk. Core sentences are the sentences taken into account by the classifier and edge tokens are tokens inserted at the edges of the chunks as a way to provide context for the first and last core sentences (see Fig. 2). The procedure requires two hyperparameters: \(c_{len}\) (the number of tokens in a chunk) and \(m_{edges}\) (the minimum desired number of tokens in the edges of a chunk). In their setup [11], the authors exploit a dataset with 277 judgments, 31,865 sentences, and 13 rhetorical roles. They experiment with four pre-trained Transformers and two additional approaches based on sentence chunks besides the DFCSC one. DFCSC-based models perform the best and the reported gains are respectively of 3.76% and 8.71% in the best and worst cases.

Illustration of a DFCSC. Remark that the classifier takes into account only the tokens chosen as core sentence representations. \(s_i\) means the i-th sentence, \(y_i\) is the label assigned to \(s_i\), h represents a token embedding, t represents a token, \(|T_i|\) is the number of tokens in \(s_i\), \( \texttt {<s>}\) and \(\texttt {</s>}\) are special tokens.
3 Experimental Setup
3.1 Datasets
We employ two datasets to evaluate the models which we refer to as 7-roles and 4-roles. Both are derivations of the original dataset developed in [15]Footnote 1 that comprises 100 judgment documents written in English from the Indian legal system split into training set (80 documents and 16,845 sentences), validation set (10 documents and 2,142 sentences), and test set (10 documents and 2,197 sentences). A team of legal experts annotated the documents and each sentence is labeled with one of the following 13 rhetorical roles: Fact (FAC), Issues (ISS), Argument Petitioner (ARG-P), Argument Respondent (ARG-R), Statute (STA), Dissent (DIS), Precedent Relied Upon (PRE-R), Precedent Not Relied Upon (PRE-NR), Precedent Overruled (PRE-O), Ruling By Lower Court (RLC), Ruling By Present Court (RPC), Ratio Of The Decision (ROD), and None (NON).
We follow the same procedure from [15] to create the 7-roles dataset. The Issue labels are renamed as Fact, the Argument Petitioner and Argument Respondent labels are renamed as Argument (ARG), and the Precedent Relied Upon, Precedent Not Relied Upon and Precedent Overruled (PRE-O) labels are renamed as Precedent (PRE). Also, the Dissent and None sentences are ignored for classification purposes. Although, some models rely on document-level data to produce feature vectors and discarding such sentences would result in a data loss degree. Regarding chunk-based models, Dissent and None sentences are part of the model input but their predicted labels are discarded when we compute the loss function value. Regarding PE-based models, such sentences are not part of the model input but they are exploited when computing the positional embeddings to preserve the actual sentence positions. By discarding the Dissent and None sentences, the 7-roles dataset is composed of 16,264, 2,109, and 2,094 sentences in the training, development, and test sets, respectively.
To be effective, PE-based models require some degree of correlation between sentence positions and rhetorical roles [12]. Thus, we designed the 4-roles dataset to perform a fairer evaluation of PE-based models. To achieve this goal, we modified the original dataset from [15] by maintaining the roles occurring often at the same positions (i.e., the Fact, Ruling By Present Court and RatioOfTheDecision) and by renaming the remaining roles as Other. We do not discard sentences in this process and hence the 4-roles dataset has the same number of sentences as the original one.
The original dataset is highly unbalanced and this is a characteristic of the 7-roles and 4-roles datasets as well. The distribution of sentences by rhetorical role in the three datasets is shown in Fig. 3.

Number of sentences per rhetorical role in the original, 7-roles, and 4-roles datasets.
3.2 Models
We implement models relying on the approaches from [10, 12], and [11]. For each approach, we experiment with two or three Transformer encoders. Details of our results and source code are available at https://github.com/alexlimatds/bracis_2023.
Mixup-A: These are models whose training includes mixup vectors as proposed by [10]. At first, a Transformer encoder is fine-tuned on the training dataset in the same fashion as the SingleSC approach described ahead (step A in Fig. 4). In the following, the fine-tuned Transformer is employed to yield sentence embeddings which serve as source data of the mixup procedure (step B in Fig. 4). Finally, the mixup vectors and the sentence embeddings are employed to train a Mixup-A model (step C in Fig. 4). The training of a Mixup-A model updates only the weights of its classification layer. Sentences are represented by the last embedding vector of the token marking the beginning of the input ([CLS] or \(\texttt {<s>}\)). We employ InCaseLaw [16] and RoBERTa-base [13] as sentence encoders. InCaseLaw is a BERT model pre-trained with corpora from the Indian legal system.
The generation of mixup vectors is oriented to selected labels and an augmentation rate \(\gamma \). For each selected label \(l_i\), we generate \(n_{l_i} \cdot \gamma \) mixup vectors, where \(n_{l_i}\) means the number of training sentences labeled with \(l_i\). A mixup vector is generated from a sentence embedding labeled with \(l_i\) and a sentence embedding labeled with \(l_j\) where \(i \ne j\) (the embeddings are selected at random). When experimenting with the 7-labels dataset, we set \(\gamma =0.5\), \(\alpha =0.1\), the selected labels are Argument, Statute, Precedent, RulingByLowerCourt, and RulingByPresentCourt which results in 3,881 synthetic vectors. For the 4-labels dataset, we set \(\gamma =0.5\), \(\alpha =0.1\), the selected labels are Fact, Ratio Of The Decision, and Ruling By Present Court which results in 4,408 synthetic vectors.

Steps performed to train a Mixup-A model. Step A: fine-tuning of the Transformer encoder by training a SingleSC model. Step B: generation of mixup synthetic vectors from sentence embeddings yielded by the fine-tuned Transformer encoder. Step C: employing sentence embeddings and mixup vectors to train the classifier of the Mixup-A model.
Mixup-B: These are models similar to the Mixup-A ones but without a prior encoder fine-tuning step. The training of a Mixup-B model updates the weights of the encoder and of the classification layer (i.e., the Transformer is fine-tuned during the training of the model). Since the sentence embeddings change during the fine-tuning, the mixup procedure yields a new set of synthetic vectors at each training epoch as shown in Fig. 5. As before, we exploit InCaseLaw and RoBERTa as sentence encoders. When experimenting with the 7-labels dataset, we set \(\gamma =1.0\), \(\alpha =0.1\), and select all seven labels, which results in about 14,800 synthetic vectors per training epoch. For the 4-labels dataset, we set \(\gamma =1.0\), \(\alpha =1.0\), the selected labels are Fact, Ratio Of The Decision, and Ruling By Present Court which results in about 8,470 per training epoch.

Training procedure of a Mixup-B model.
PE-S: These are models that rely on the sum of sentence embeddings and positional embeddings as proposed in [12]. We exploit InCaseLaw and RoBERTa as sentence encoders and sentences are encoded in isolation.
PE-C: Like PE-S models, but we employ concatenation instead of sum to combine sentence embeddings and positional embeddings.
DFCSC-SEP: These are models based on the DFCSC approach [11]. We employ InCaseLaw, RoBERTa-base, and Longformer-base [2] as sentence encoders. Longformer is a model that relies on a sparse self-attention mechanism, which allows it to handle longer sentences than the BERT-based models. In all models, core sentences are represented by the last hidden states of the respective separator tokens (the [SEP] or \(\texttt {</s>} \)token to the right of a core sentence). We set \(m_{edges}=250\) for the three models, \(c_{len}=512\) for the models based on InCaseLaw and RoBERTa, and \(c_{len}=1,024\) for the model based on Longformer.
DFCSC-CLS: Like DFCSC-SEP models, but each core sentence is represented by the concatenation of the last hidden states regarding the special token marking the beginning of the chunk ([CLS] or \(\texttt {<s>}\)) and the corresponding separator token ([SEP] or \(\texttt {</s>}\)).
We also implement the following baselines:
SingleSC: These are single sentence classification models, i.e. models that do not rely on chunks. Each sentence is fed to the model one by one and is represented by the hidden state of the token that marks the beginning of the input (\(\texttt {<s>}\) or [CLS]). SingleSC models are the reference baselines of Mixup and PE models, since such approaches do not consider context to encode sentences. The exploited pre-trained encoders are InCaseLaw and RoBERTa-base.
Cohan: These are models that follows the chunk design from [4], that is, chunks that do not share sentences or tokens. Cohan models are the reference baselines of DFCSC models since such approaches rely on chunks to encode sentences. The exploited pre-trained encoders are InCaseLaw, RoBERTa, and Longformer. Models based on InCaseLaw and RoBERTa have the following hyperparameter values: 85 as the maximum sentence length, 512 as the chunk length, and 7 as the maximum number of sentences in a chunk. The model based on Longformer has the following hyperparameter values: 85 as the maximum sentence length, 1,024 as the chunk length, and 14 as the maximum number of sentences in a chunk. Each sentence is represented by the hidden state of the following separator token.
All models use a single fully-connected layer as their classifier. Except for the Mixup-A models, the encoder is fine-tuned together with the classifier during the training of the respective model. For each Mixup-A model, the Transformer encoder is tuned with the same hyperparameters as its SingleSC counterpart (e.g., SingleSC-InCaseLaw and Mixup-A-InCaseLaw). For their classifiers, we adopt 200 training epochs, \(10^{-2}\) as initial learning rate, and 0.2 as dropout rate. The remaining models are fine-tuned for four epochs, and we adopt \(10^{-5}\) as initial learning rate and 0.2 as dropout rate of the classification layer. The pre-trained Transformer models are used with default parameters, except for the Longformer, whose global attention is set to consider \(\texttt {<s>}\) and \(\texttt {</s>}\) tokens. For all models we employ the cross entropy loss function and the Adam optimizer (\(\beta _1=0.9\), \(\beta _2=0.999\), \(\epsilon =10^{-8}\), \(weight\_decay=10^{-3}\)). The learning rate is scheduled linearly from an initial value to zero, and there are no warm-up steps. We adopt a batch size of 4 for Longformer-based models and a batch size of 16 for the other models. Python 3.8.13, PyTorch 1.13.0, and Hugging Face Transformer 4.28.1 are the programming language and main libraries we use to develop all models. Hugging Face is mainly used to load pre-trained Transformer models. A single 16GB Tesla V100 SXM2 GPU is used in all experiments.
3.3 Evaluation
All models are trained on the training set and evaluated on the test set. For each model, the training and evaluation procedure is repeated five times with a different random seed for each repetition (the same five seeds for all models). The evaluation metric is the macro F1 score.
To compare the results obtained by the implemented models, we use the Almost Stochastic Order (ASO) test [6] with Bonferroni correction as implemented by [19]. ASO is a statistical significance test designed to compare two score distributions produced by deep learning models. The test analyzes two distributions and quantifies the amount of stochastic order violation by computing a value \(\epsilon _{min}\). Given the scores over multiple random seeds from two models A and B, A is declared superior if \(\epsilon _{min} < \tau \), where \(\tau \) is 0.5 or less (or more precisely, we confirm that A is stochastically dominant over B in more cases than vice versa). We can also interpret \(\epsilon _{min}\) as a confidence score: the lower it is, the stronger the evidence that A is superior to B. In this context, and following the recommendation of \(\tau =0.2\) for multiple comparisons, we formulate our hypotheses as
In our experiments, we compare all pairs of models based on five random seeds each using ASO with a confidence level of \(\alpha = 0.05\) (before adjusting for all pairwise comparisons using the Bonferroni correction). We only compare scores obtained on the same dataset.
4 Results and Discussion
Table 1 presents the results achieved by the models described in Sect. 3 and by the MTL-LSP-BiLSTM-BERT model reported in [15]. We confirm the statistical power of the samples (scores) by employing Bootstrap power analysis [22].
Baselines: All Cohan models achieve higher scores than SingleSC ones and the differences are statistically significant in both datasets (\(\epsilon _{min} \le 0.05\) in all comparisons). This is expected since Cohan models exploit more contextual data to yield sentence embeddings. The differences between SingleSC-InCaseLaw and SingleSC-RoBERTa models are significant in both datasets as well (\(\epsilon _{min} \le 0.08\)). We also have significant differences for Cohan-Longformer vs. Cohan-InCaseLaw and Cohan-Longformer vs. Cohan-RoBERTA (\(\epsilon _{min}=0.01\) in both comparisons) for the 7-roles dataset, and for Cohan-InCaseLaw vs Cohan-RoBERTa (\(\epsilon _{min}=0.04\)) and Cohan-InCaseLaw vs Cohan-Longformer (\(\epsilon _{min}=0.00\)) for the 4-roles dataset. The MTL-LSP-BiLSTM-BERT model remarkably outperforms all baselines. Although we cannot perform ASO tests among this model and our baselines because the scores of MTL-LSP-BiLSTM-BERT are not available, the differences are likely significant because the differences are large and the reported standard deviation is small.
Mixup Models: Regarding the two datasets, the score differences between each Mixup-A or Mixup-B model and its SingleSC counterpart (e.g., Mixup-A-InCaseLaw vs. SingleSC-InCaseLaw) are really small, and according to the ASO tests, these differences do not have statistical significance. Hence, the Mixup approaches do not harm or improve the base SingleSC models. Also, there are no significant differences among Mixup-A and Mixup-B models, considering both datasets and the same encoder. Previous work [10] achieves performance gains by exploiting mixup vectors: the F1 score achieved by a linear classifier improves by 4.3% in the worst case and by 6.8% in the best case. So why do our mixup-based models not outperform their baselines? This may be due to the size of the datasets. In [10], there is little data, so the additional data provided by mixup is beneficial. Conversely, the dataset of the current work is larger, leaving no room for improvements based on data augmentation.
PE Models: Concerning the 7-roles dataset, the PE-S models perform worse than their respective SingleSC counterparts, but the difference is only significant for SingleSC-RoBERTa vs. PE-S-RoBERTa (\(\epsilon _{min}=0.03\)). This means that the PE-S approach harms the base SingleSC-RoBERTa model instead of improving it. For the 4-roles dataset, the PE-S models outperform their respective SingleSC counterparts, but the differences are not significant. Also, there are no significant differences among the PE-C models and their respective SingleSC counterparts for the two datasets. We expected poor results (i.e., no gain or decrease in performance) from the PE models with respect to the 7-roles dataset, since most of its labels do not have a clear correlation with sentence positions. In the case of performance degradation, PE vectors should be working as noise data. Conversely, we expected PE vectors to provide gains in the experiments with the 4-roles dataset, which does not happen. We believe that the positional embeddings employed do not represent positions in a way that can enrich the input data of the models.
DFCSC models: Regarding the 7-roles dataset, all DFCSC models outperform their respective Cohan counterparts. The differences are significant with \(\epsilon _{min}=0.14\) for DFCSC-CLS-InCaseLaw vs. Cohan-InCaseLaw, and \(\epsilon _{min}=0.01\) for the remaining comparisons. For the 4-roles dataset, only DFCSC-SEP-InCaseLaw and DFCSC-CLS-InCaseLaw do not outperform their respective Cohan counterparts. The ASO test results in \(\epsilon _{min}=0.23\) for Cohan-InCaseLaw vs. DFCSC-SEP-InCaseLaw, and in \(\epsilon _{min}=0.00\) for Cohan-InCaseLaw vs. DFCSC-CLS-InCaseLaw, meaning that only the latter comparison is significant. The DFCSC models using RoBERTa and Longformer encoders achieve remarkable improvements: the lowest and highest gains are 5.9% and 10.4%, respectively. This behavior is also reported in [11], and thus we consider this additional evidence that the RoBERTa and Longformer encoders exploit contextual data in a better way than the InCaseLaw one (RoBERTa and Longformer rely on the same training procedure, which is different from the one used for InCaseLaw). Comparing the performance of the DFCSC models using Table 2, we come to some conclusions. First, regarding the 7-roles dataset, we see that all Longformer-based models are superior to those based on RoBERTa and InCaseLaw; that all RoBERTa-based models are superior to those based on InCaseLaw; and that there is no significant difference between the DFCSC-SEP and DFCSC-CLS approaches when we compare models that employ the same encoder. Regarding the 4-roles dataset, we find that DFCSC-SEP-Longformer is superior to all models using RoBERTa and InCaseLaw; that DFCSC-CLS-Longformer is superior to DFCSC-CLS-RoBERTa, DFCSC-SEP-InCaseLaw, and DFCSC-CLS-InCaseLaw; that the two RoBERTa-based models are superior to those based on InCaseLaw; and that there is no significant difference between the DFCSC-SEP and DFCSC-CLS approaches when we compare models that employ the same encoder. When comparing DFCSC and MTL-LSP-BiLSTM-BERT models, we find that RoBERTa-based models perform similarly and that Longformer-based models perform better.
5 Final Remarks
In this work, we compare approaches from recent proposals to handle the LegalRRL task. All approaches rely on pre-trained Transformers to encode sentences and employ different strategies to improve reference baselines. Models based on the Mixup and PE approaches are unable to overcome the SingleSC baselines. For the PE models, we conclude that the 7-role dataset does not have a sufficient correlation between labels and sentence positions, which nullifies the usefulness of the models. For the 4-role dataset, we believe that the positional embeddings employed are not powerful enough to enrich the input data of the models.
Models based on the DFCSC approach, on the other hand, show remarkable performance. Most of them overcome strong baselines based on sentence chunks. DFCSC models that exploit RoBERTa and Longformer encoders perform similarly or better than a model based on the MTL-LSP approach proposed in [15].
From the obtained results, we propose a future work that combines MTL-LSP and DFCSC approaches, since the MTL-LSP-BiLSTM-BERT model does not rely on sentence chunks to encode sentences with BERT. Such work would provide interesting evidence about the ability of LSP signals to boost sentence chunk-based models.
We also say that the sentence classification approaches evaluated in this work do not rely on knowledge specific to the legal domain. Therefore, more studies should be conducted to evaluate the efficiency of such approaches in other domains. Despite this, we believe that incorporating domain-specific knowledge into models based on pre-trained Transformers is a valuable research direction.
Notes
- 1.
Available at https://github.com/Exploration-Lab/Rhetorical-Roles.
References
Aragy, R., Fernandes, E.R., Caceres, E.N.: Rhetorical role identification for Portuguese legal documents. In: Britto, A., Valdivia Delgado, K. (eds.) BRACIS 2021. LNCS (LNAI), vol. 13074, pp. 557–571. Springer, Cham (2021). https://doi.org/10.1007/978-3-030-91699-2_38
Beltagy, I., Peters, M.E., Cohan, A.: Longformer: the long-document transformer. CoRR abs/2004.05150 (2020). https://arxiv.org/abs/2004.05150
Bhattacharya, P., Paul, S., Ghosh, K., Ghosh, S., Wyner, A.: Deeprhole: deep learning for rhetorical role labeling of sentences in legal case documents. Artificial Intelligence and Law, pp. 1–38 (2021)
Cohan, A., Beltagy, I., King, D., Dalvi, B., Weld, D.: Pretrained language models for sequential sentence classification. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 3693–3699. Association for Computational Linguistics, Hong Kong, November 2019. https://doi.org/10.18653/v1/D19-1383. https://aclanthology.org/D19-1383
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4171–4186. Association for Computational Linguistics, Minneapolis, Minnesota, June 2019. https://doi.org/10.18653/v1/N19-1423. https://aclanthology.org/N19-1423
Dror, R., Shlomov, S., Reichart, R.: Deep dominance - how to properly compare deep neural models. In: Korhonen, A., Traum, D.R., Màrquez, L. (eds.) Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28–August 2, 2019, Volume 1: Long Papers, pp. 2773–2785. Association for Computational Linguistics (2019). https://doi.org/10.18653/v1/p19-1266. https://doi.org/10.18653/v1/p19-1266
Feijo, D., Moreira, V.: Summarizing legal rulings: comparative experiments. In: Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2019), pp. 313–322. INCOMA Ltd., Varna, Bulgaria, September 2019. https://doi.org/10.26615/978-954-452-056-4_036. http://aclanthology.org/R19-1036
Kalamkar, P., et al.: Corpus for automatic structuring of legal documents. In: Proceedings of the Thirteenth Language Resources and Evaluation Conference, pp. 4420–4429. European Language Resources Association, Marseille, France, June 2022. https://aclanthology.org/2022.lrec-1.470
Li, D., Yang, K., Zhang, L., Yin, D., Peng, D.: Class: a novel method for chinese legal judgments summarization. In: Proceedings of the 5th International Conference on Computer Science and Application Engineering. CSAE 2021. Association for Computing Machinery, New York (2021). https://doi.org/10.1145/3487075.3487161
de Lima, A.G., Boughanem, M., da S. Aranha, E.H., Dkaki, T., Moreno, J.G.: Exploring SBERT and mixup data augmentation in rhetorical role labeling of Indian legal sentences. In: Tamine, L., Amigó, E., Mothe, J. (eds.) Proceedings of the 2nd Joint Conference of the Information Retrieval Communities in Europe (CIRCLE 2022), Samatan, Gers, France, July 4–7, 2022. CEUR Workshop Proceedings, vol. 3178. CEUR-WS.org (2022). https://ceur-ws.org/Vol-3178/CIRCLE_2022_paper_29.pdf
de Lima, A.G., Moreno, J.G., da S. Aranha, E.H.: IRIT_IRIS_A at SemEval-2023 Task 6: legal rhetorical role labeling supported by dynamic-filled contextualized sentence chunks. In: Proceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023). Association for Computational Linguistics, Toronto, Canada, July 2023
de Lima, A.G., Moreno, J.G., Boughanem, M., Dkaki, T., da S. Aranha, E.H.: Leveraging positional encoding to improve fact identification in legal documents. In: First International Workshop on Legal Information Retrieval (LegalIR) at ECIR 2023, pp. 11–13 (2023). https://tmr.liacs.nl/legalIR/LegalIR2023_proceedings.pdf
Liu, Y., et al.: Roberta: a robustly optimized BERT pretraining approach. CoRR abs/1907.11692 (2019). https://arxiv.org/abs/1907.11692
Ma, L., Zhang, Y., Wang, T., Liu, X., Ye, W., Sun, C., Zhang, S.: Legal judgment prediction with multi-stage case representation learning in the real court setting. In: Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 993–1002. SIGIR ’21. Association for Computing Machinery, New York (2021). https://doi.org/10.1145/3404835.3462945
Malik, V., Sanjay, R., Guha, S.K., Hazarika, A., Nigam, S., Bhattacharya, A., Modi, A.: Semantic segmentation of legal documents via rhetorical roles. In: Proceedings of the Natural Legal Language Processing Workshop 2022, pp. 153–171. Association for Computational Linguistics, Abu Dhabi, United Arab Emirates (Hybrid), December 2022. https://aclanthology.org/2022.nllp-1.13
Paul, S., Mandal, A., Goyal, P., Ghosh, S.: Pre-training transformers on indian legal text. CoRR abs/2209.06049 (2022). https://doi.org/10.48550/arXiv.2209.06049
Reimers, N., Gurevych, I.: Sentence-bert: sentence embeddings using siamese bert-networks. In: Inui, K., Jiang, J., Ng, V., Wan, X. (eds.) Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3–7, 2019, pp. 3980–3990. Association for Computational Linguistics (2019). https://doi.org/10.18653/v1/D19-1410
Savelka, J., Westermann, H., Benyekhlef, K.: Cross-domain generalization and knowledge transfer in transformers trained on legal data. In: Ashley, K.D., Atkinson, K., Branting, L.K., Francesconi, E., Grabmair, M., Walker, V.R., Waltl, B., Wyner, A.Z. (eds.) Proceedings of the Fourth Workshop on Automated Semantic Analysis of Information in Legal Text held online in conjunction with the 33rd International Conference on Legal Knowledge and Information Systems, ASAIL@JURIX 2020, December 9, 2020. CEUR Workshop Proceedings, vol. 2764. CEUR-WS.org (2020). https://ceur-ws.org/Vol-2764/paper5.pdf
Ulmer, D., Hardmeier, C., Frellsen, J.: Deep-significance-easy and meaningful statistical significance testing in the age of neural networks. arXiv preprint arXiv:2204.06815 (2022)
Vaswani, A., et al.: Attention is all you need. In: Guyon, I., von Luxburg, U., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R. (eds.) Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4–9, 2017, Long Beach, CA, USA, pp. 5998–6008 (2017). https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
Wang, C., Nulty, P., Lillis, D.: A comparative study on word embeddings in deep learning for text classification. In: Proceedings of the 4th International Conference on Natural Language Processing and Information Retrieval, NLPIR 2020, pp. 37–46. Association for Computing Machinery, New York(2021). https://doi.org/10.1145/3443279.3443304
Yuan, K.H., Hayashi, K.: Bootstrap approach to inference and power analysis based on three test statistics for covariance structure models. Br. J. Math. Stat. Psychol. 56(1), 93–110 (2003). https://doi.org/10.1348/000711003321645368. https://bpspsychub.onlinelibrary.wiley.com/doi/abs/10.1348/000711003321645368
Zhang, H., Cissé, M., Dauphin, Y.N., Lopez-Paz, D.: mixup: beyond empirical risk minimization. In: 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net (2018). https://openreview.net/forum?id=r1Ddp1-Rb
Zhong, H., Xiao, C., Tu, C., Zhang, T., Liu, Z., Sun, M.: How does NLP benefit legal system: a summary of legal artificial intelligence. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. pp. 5218–5230. Association for Computational Linguistics, Online, July 2020. https://doi.org/10.18653/v1/2020.acl-main.466. https://aclanthology.org/2020.acl-main.466
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
de Lima, A.G., Moreno, J.G., Dkaki, T., da S. Aranha, E.H., Boughanem, M. (2023). Evaluating Recent Legal Rhetorical Role Labeling Approaches Supported by Transformer Encoders. In: Naldi, M.C., Bianchi, R.A.C. (eds) Intelligent Systems. BRACIS 2023. Lecture Notes in Computer Science(), vol 14196. Springer, Cham. https://doi.org/10.1007/978-3-031-45389-2_2
Download citation
DOI: https://doi.org/10.1007/978-3-031-45389-2_2
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-45388-5
Online ISBN: 978-3-031-45389-2
eBook Packages: Computer ScienceComputer Science (R0)