
Abstract
Segmentation of Organs at Risk is a fundamental step during radiotherapy planning for cancer treatment. Its goal is to preserve healthy tissue around the tumor and ensure that the most radiation strikes only cancer cells. Physicians do this job manually, which can be slow and error-prone. Thus, automatic segmentation methodologies can speed up organ delimiting during radiotherapy planning. This work designs a method, EfficientDeepLab, a convolutional neural network architecture trained on CT scans for trachea segmentation, and obtained an 88.6% dice score.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others

1 Introduction
Radiotherapy is one type of cancer treatment consisting of blasting high radiation doses into unhealthy cells to destroy or shrink tumors [2]. Identifying the tumor location and the surrounding organs is the first step in radiotherapy planning and helps diminish the ionizing radiation effects on healthy tissue. We call these healthy organs that surround a tumor Organs at Risk (OaR) [8, 18]. A physician does the manual segmentation of the OaR using images obtained by Computed Tomography (CT).
CT is an imaging exam that allows doctors to evaluate the body’s soft and hard tissue health. An x-ray emitting machine spins around the patient while sensors at the other end capture the radiation that trespasses the patient and convert it to a digital image [1, 14]. The result is a 3D image that can be sliced down to 2D for better visualization [10]. Figure 1 shows examples of CT slices.

2D slices from a CT test. a) Axial View; b) Coronal View; c) Sagital View.
Accurate manual segmentation of OaR is crucial because it provides the exact location of healthy tissue near the tumor so that specialists can prevent unnecessary X-ray exposition and minimize the side effects of radiation (inflammation, fibrosis, ulceration, and even organ failure [21]). However, it depends on the physician’s expertise and can be a slow and error-prone process. Smaller organs like the trachea are hard to segment due to size, texture similarity with surrounding tissue, and lack of detail richness. Because of that, recent research focused on the automatic segmentation of Organs at Risk.
Based on the importance of trachea segmentation for radiotherapy planning and current literature on automatic medical image segmentation, this work proposes utilizing image pre-processing techniques and proposes an EfficientDeepLab convolutional network architecture for trachea segmentation from computed tomography images. General contributions are: (a) pixel intensity windowing for better contrast on trachea images, and (b) a method that merges EfficientNet and DeepLabV3+ architectures to perform trachea segmentation, increasing the convolutions field-of-view by using atrous convolutions, leading to more detailed segmentation, considerably less network parameters and efficient utilization of computational resources.
2 Related Work
Some works develop methods for trachea segmentation using fully convolutional networks or combining transformers with these networks.
Driven by recent advances in transformer architecture for image segmentation, [24] used it alongside U-Net to perform segmentation on various OaRs, including the trachea.
Some methods use the 3D nature of tomography to extract contextual information about the CT scan, like in [22] and [23].
Other methods combine U-Net and another convolutional network architecture to perform OaR segmentation: [9] used pyramid fusion module to merge features from different scales on the U-Net and [25] applied Generative Adversarial Networks and U-Net together to segment organs from CT images.
There are also some efforts to build public datasets for OaR segmentation. In [17], researchers gathered CT scans from 60 patients diagnosed with lung cancer to train a U-NET with 2D input. Of those 60 CT scans, 40 are publicly available, composing the SEGTHOR dataset.
The literature presents efforts based on methods such as U-NET, but without necessarily worrying about the efficiency of networks in terms of trainable parameters. Starting from this point, we propose a method where the network backbone is built using EfficientNet and network decoder/encoder with DeepLab. The aim is to build a model with few trainable parameters, easily applicable in small datasets, and presenting consistent results.
3 Materials and Methods
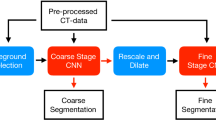
This section presents the proposed method, its steps, and information about the image dataset used for training. Figure 2 illustrates the general pipeline of this work, beginning from the image acquisition, passing to the preprocessing work, EfficientDeepLab model training, and segmentation mask output.

General workflow of the method.
3.1 Dataset
The images in the experiment come from the SEGTHOR database [17]. There are 40 publicly available 3D CT volumes from patients affected by lung cancer. The volumes were sliced along the longitudinal body axis to generate 7420 2D images. From the total, 1987 shows trachea and the other 5433 don’t. This distribution generates an unbalanced dataset, so, for training purposes, 1987 images without trachea were randomly selected, resulting in equally distributed slices.
The data also includes a physician-made manual segmentation for ground truth. Figure 3 shows a trachea region slice and the correspondent demarcation.

a) Axial view of trachea slice; b) Manual segmentation made by radiology professional.
The pixel intensity values on a CT image range from -1000 to 1000, according to the Hounsfield scale [11], which is a way to represent tissue density in radiography images (the denser the tissue, the brighter the image). Table 1 summarizes the Hounsfield scale.
Pre-processing: For better contrast, we applied an intensity windowing method, limiting the pixel values to an interval, thus discarding unwanted information, after this process, a normalization followed by image resizing were applied. In the training phase, a random data augmentation technique was applied.
Intensity Windowing: This technique is employed within the radiology domain to improve CT imaging. Its usage varies depending on the application, allowing for enhanced visualization of particular body tissues. Let \(\alpha \) and \(\beta \) represent the lower and upper boundaries of the interval \([\alpha , \beta ]\), respectively. The intensity windowing technique involves clipping the pixel values outside this interval to the closest boundary value while letting pixels within the interval remain unchanged. These intervals are called windows, and each range emphasizes different kinds of tissues from the body. The trachea is a hollow tubular organ, so the chosen intensity interval was [−1000, 60] because it enhances the contrast between the trachea muscle walls and the air inside it [6]. Figure 4 shows different window ranges applied to the same image.
Normalization: After the intensity windowing, we also apply normalization, subtracting the pixel values from the image mean and dividing by its standard deviation. This way, the data tend to be more uniform, facilitating the learning process for the model. Equation 1 describes the intensity windowing process, and Eqs. 2 to 4 detail the image normalization method.
Resizing: After the normalization, the images were resized from 512\(\,\times \,\)512 to 256\(\,\times \,\)256.

Examples of different intensity windowing preprocessing applied to CT images.
Data Augmentation: This process is executed to insert variance into the training data and make the model more robust and generalist. A random rotation is set to each image, ranging from −45 to 45\(^\circ \) with a chance of 50%.
3.2 Model Architecture
For semantic segmentation of the trachea area, we apply a neural network architecture based on DeepLabV3+ [5] combined with EfficientNet [20] for feature extraction. Figure 5 illustrates the encoder/decoder model architecture overview.

Architectural overview of EfficientDeeplab.
The main DeepLabV3+ innovations are the atrous convolutions (also called dilatable convolutions) and atrous spatial pyramid pooling [12]. This way, we are capable of merging features from multiple scales. In the original DeepLabV3+, the author uses ResNet [13] architecture as a feature extraction backbone, aggregating intermediate layer feature maps, summing them, and interpolating back to the input resolution, thus obtaining a segmentation output mask. In this work, we modified the feature extraction backbone to use EfficientNet, a scalable, robust, and compact deep learning model that surpasses ResNet in recent benchmarks on ImageNet [7] dataset.
EfficientNet: Built with efficient resource usage in mind, it consists of a family of networks derived from a baseline model obtained with Neural Architecture Search. The baseline network is called the b0, the other models range from b1 to b7, and the differences are the input resolution, the number of channels, and layers in each stage, such that the larger the number on the network’s name, the bigger the model (in terms of parameters). The b0 model’s main structure is summarized in Table 2.
The main building blocks of the EfficientNet are the MBConv blocks, introduced in MobileNetV2 [19]. They are an inverted residual bottleneck, expanding the number of channels in the intermediate layers and lately squeezing them to their original size. Figure 6 illustrates the structure of the MBConv block. The number that follows the name in MBConv1 and MBConv6 is a multiplier that indicates the number of filters in the leftmost 1\(\,\times \,\)1 convolutional layer. For example, if the number of input channels is 4, then the number of filters will be 4 in the MBConv1 and 24 in the MBConv6.

Schematic diagram of MBConv.
Two outputs from the EfficientNet model are used: the last convolutional layer activations and the intermediate features from the third convolutional block. The first one feeds the encoder part, while the latter feeds the decoder part.
Atrous Convolution: Introduced by DeepLabV1 [3], it is a convolution with dilatable kernels, and its goal is to achieve a larger field of view on feature extraction. The filter is filled with zeros according to a chosen dilation rate r. Figure 7 exemplifies the dilation rate effect over the convolution kernel. Notice that the area covered by the filter goes from 3\(\,\times \,\)3 to 5\(\,\times \,\)5, but the number of parameters is still the same. Varying the dilation rate along the network convolutions helps the model to capture features on different scales. DeeplabV3+ also implements an atrous version of the Depthwise Separable Convolution, where the Depthwise convolution also has a dilation in the kernel.

Atrous Convolution kernel with different dilation rates.
Atrous Spatial Pyramid Pooling: Inspired by the Spatial Pyramid Pooling (SPP) proposed in [12], the authors of DeepLab introduced the atrous version of it in [4]. The method encodes features from different resolutions into fixed-size feature maps and concatenates them together to feed the rest of the network, as illustrated in Fig. 8.

Architectural overview of Atrous Spatial Pyramid Pooling Module.
Encoder/Decoder: Following the recipe of the most successful methods for semantic image segmentation, this work uses the encoder/decoder structure for extracting features and restoring them to the original resolution. The EfficientNet model serves as the feature extraction backbone alongside the ASPP module, and both compose the encoder part of the model. The decoder inputs are the features from EfficientNet’s third layer. They are further convoluted by one atrous separable convolution and one 1\(\,\times \,\)1 convolution layer. The result is concatenated with the encoder output to get convolved and upsampled to the original image resolution, outputting an image segmentation mask.
3.3 Results
We conducted experiments to validate the proposed method. The training environment was a computer with Intel Core ™ i5-10400F CPU @ 2.90 GHz and one Nvidia ® GPU RTX-3060 12 GB of memory. For the implementation of the model, we used Python programming language and the libraries: Tensorflow, Keras, and Tensorflow Advanced Segmentation Models [15].
For a better understanding of how large the feature extraction backbone model needs to be, we experimented with EffcientNet b0, b1, and b2, estimating which one suits better for the problem. We did not use the models above b2 because the dataset is not big enough to supply those models.
The pre-processed SEGTHOR 2D slices were split 70% for training and 30% for the test, per patient. It is important to emphasize that the results use at least 30% fewer data than the works on the SEGTHOR dataset due to the unavailability of 20 test case patients from the original 60 patients on the dataset.
The training was executed for 100 epochs and used ADAM (Adaptive Moment Estimation) to update the network weights [16]. The loss function used is Binary Cross-Entropy Loss \(+\) Dice Loss. The training process was repeated 5 times for each model, following the holdout validation method. Table 3 summarizes the dice and Jaccard score for the different EffcientNet backbones experimented with.
The best-performing model reached 88.6% Dice score for trachea segmentation with 0.7 Std, demonstrating that the model could generalize with stable metrics. This result was found with EfficientNet b0, which is also a lighter version, indicating that the dataset is not sufficiently extensive for training deeper networks. Notice that EfficientNet b1 and b2 obtained a higher std and at the same time lower dice score.
3.4 Discussion
Some regions of the trachea are more difficult to segment. It happens because the organ varies in shape according to the region depth in the body. At some depths, the organ may also split into two tubes, as depicted in Fig. 9. Here we can see the original image on the left side, the model prediction in the middle, and the manual segmentation on the right.

Study case: 2D slice where the trachea is found splitted into two tubes. The image in the middle is the prediction made by the model. The image on the right is the ground truth, provided by a physician.
The network performs well for the central portions of the trachea, as illustrated in Fig. 10, where EfficientDeeplab was capable of correctly identifying the shape and location of the organ.

Study case: prediction of a central portion of the trachea. The image in the middle is the prediction made by the model. The image on the right is the ground truth, provided by a physician
However, for the peripheral slices of the organ and the images without trachea presence, it’s difficult for the model to yield the correct output. Some image regions contain similar textural features and shapes as the trachea, so the network outputs false positives, as shown in Fig. 11. Notice that there is no trachea presence in this CT slice, however, there is another body structure with a similar shape and texture that tricks the model into marking this region as the trachea. Correctly segmenting these kind of slices is the main limitation of the model, but it can be overcome by adding post-processing to select only the largest 3D object, considering prediction results over the entire CT scan.

Study case: the method’s main limitations are the slices where there’s no presence of trachea. The image in the middle is the prediction made by the model, which detected a false positive. The image on the right is the ground truth, provided by a physician
Table 4 compares this work with some methods that also segment trachea. For the analysis, we need to clarify that our experiment did five random hold-out sampling to avoid biased results based on the dataset organization and to guarantee repetition. The related works did not do this procedure. Also, the other works have access to the complete dataset, which is an advantage for training deep-learning models.
Despite not being the best-performing model in the literature, it still produces excellent results, close to other works, but with 20x less parameters than [22], which is a considerably smaller number of parameters, being a compact yet robust neural network that consumes less computational resources than similar models. This is achieved using the EfficientNet architecture, a very compact and scalable model that rethinks network scale with resource constraints in mind.
4 Conclusion
This work proposed an automated method for trachea segmentation on CT images using EfficientDeepLab neural network architecture. The obtained results are promising and competitive, and its main contributions are the pre-processing based on intensity windowing, the use of dilated convolutions (atrous), and the atrous version of spatial pyramid pooling, leading to better feature extraction over different scales of resolution, and the efficient utilization of computational resource by adopting the EfficientNet architecture as the feature extraction backbone, which delivers a model with only 6 million parameters, considerably smaller than the methods proposed in the current literature for trachea segmentation with deep learning.
There is space for future improvements, such as adding new pre-processing techniques, automatically estimating a intensity window, aggregating 2.5D information from the volume into the model, adding post-processing to the output, and removing false positives. This way, the methodology can get more robust and precise, contributing to faster radiotherapy planning and consequently improving the quality of life for cancer patients.
References
Amaro, E.J., Yamashita, H.: Aspectos básicos de tomografia computadorizada e ressonância magnética. Braz. J. Psychiatry 23, 2–3 (2001)
Baskar, R., Lee, K.A., Yeo, R., Yeoh, K.W.: Cancer and radiation therapy: current advances and future directions. Int. J. Med. Sci. 9(3), 193 (2012)
Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Semantic image segmentation with deep convolutional nets and fully connected CRFs (2016)
Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 40(4), 834–848 (2018). https://doi.org/10.1109/tpami.2017.2699184
Chen, L.C., Zhu, Y., Papaãndreou, G., Schroff, F., Adam, H.: Encoder-decoder with atrous separable convolution for semantic image segmentation (2018)
Consídera, D.P., et al.: A tomografia computadorizada de alta resolução na avaliação da toxicidade pulmonar por amiodarona. Radiologia Brasileira 39, 113–118 (2006)
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: a large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255 (2009). https://doi.org/10.1109/CVPR.2009.5206848
Diniz, J., Ferreira, J., Silva, G., Quintanilha, D., Silva, A., Paiva, A.: Segmentação de coração em tomografias computadorizadas utilizando atlas probabilístico e redes neurais convolucionais. In: Anais do XXI Simpósio Brasileiro de Computação Aplicada á Saúde, pp. 83–94. SBC, Porto Alegre, RS, Brasil (2021). https://doi.org/10.5753/sbcas.2021.16055. https://sol.sbc.org.br/index.php/sbcas/article/view/16055
Feng, S., et al.: CPFNet: context pyramid fusion network for medical image segmentation. IEEE Trans. Med. Imaging 39(10), 3008–3018 (2020). https://doi.org/10.1109/TMI.2020.2983721
Gupta, T., Narayan, C.A.: Image-guided radiation therapy: physician’s perspectives. J. Med. Phys./Assoc. Med. Physicists India 37(4), 174 (2012)
Hansen, P.C., Jørgensen, J., Lionheart, W.R.: Computed tomography: algorithms, insight, and just enough theory. SIAM (2021)
He, K., Zhang, X., Ren, S., Sun, J.: Spatial pyramid pooling in deep convolutional networks for visual recognition. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8691, pp. 346–361. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10578-9_23
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition (2015)
Kalender, W.A.: X-ray computed tomography. Phys. Med. Biol. 51(13), R29 (2006)
Kezmann, J.M.: Tensorflow advanced segmentation models (2020). https://github.com/JanMarcelKezmann/TensorFlow-Advanced-Segmentation-Models
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization (2017)
Lambert, Z., Petitjean, C., Dubray, B., Ruan, S.: Segthor: segmentation of thoracic organs at risk in CT images (2019). https://doi.org/10.48550/ARXIV.1912.05950. arxiv.org/abs/1912.05950
Noël, G., Antoni, D., Barillot, I., Chauvet, B.: Délinéation des organes á risque et contraintes dosimétriques. Cancer/Radiothérapie 20, S36–S60 (2016). https://doi.org/10.1016/j.canrad.2016.07.032. https://www.sciencedirect.com/science/article/pii/S1278321816301676. recorad: Recommandations pour la pratique de la radiothérapie externe et de la curiethérapie
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., Chen, L.C.: Mobilenetv 2: inverted residuals and linear bottlenecks (2019)
Tan, M., Le, Q.: EfficientNet: rethinking model scaling for convolutional neural networks. In: Chaudhuri, K., Salakhutdinov, R. (eds.) Proceedings of the 36th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 97, pp. 6105–6114. PMLR (2019). https://proceedings.mlr.press/v97/tan19a.html
Tekatli, H., et al.: Normal tissue complication probability modeling of pulmonary toxicity after stereotactic and hypofractionated radiation therapy for central lung tumors. Int. J. Radiat. Oncol. Biol. Phys. 100(3), 738–747 (2018)
Wang, Q., et al.: 3D enhanced multi-scale network for thoracic organs segmentation. SegTHOR@ ISBI 3(1), 1–5 (2019)
Wang, S., et al.: Conquering data variations in resolution: a slice-aware multi-branch decoder network. IEEE Trans. Med. Imaging 39(12), 4174–4185 (2020). https://doi.org/10.1109/TMI.2020.3014433
Yan, X., Tang, H., Sun, S., Ma, H., Kong, D., Xie, X.: After-UNet: axial fusion transformer UNet for medical image segmentation. In: 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Los Alamitos, CA, USA, pp. 3270–3280. IEEE Computer Society (2022). https://doi.org/10.1109/WACV51458.2022.00333. https://doi.ieeecomputersociety.org/10.1109/WACV51458.2022.00333
Zhao, W., Chen, H., Lu, Y.: W-net: A network structure for automatic segmentation of organs at risk in thorax computed tomography. In: Proceedings of the 2020 2nd International Conference on Intelligent Medicine and Image Processing, IMIP 2020, pp. 66–69. Association for Computing Machinery, New York (2020). https://doi.org/10.1145/3399637.3399642
Acknowledgments
This work was carried out with the support of the Coordination for the Improvement of Higher Education Personnel - Brazil (CAPES) - Financing Code 001, Maranhão Research Support Foundation (FAPEMA), National Council for Scientific and Technological Development (CNPq) and Brazilian Company of Hospital Services (Ebserh) Brazil (Proc. 409593/2021-4).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Fernandes, A.G.S., Braz Junior, G., Diniz, J.O.B., Silva, A.C., Matos, C.E.F. (2023). EfficientDeepLab for Automated Trachea Segmentation on Medical Images. In: Naldi, M.C., Bianchi, R.A.C. (eds) Intelligent Systems. BRACIS 2023. Lecture Notes in Computer Science(), vol 14196. Springer, Cham. https://doi.org/10.1007/978-3-031-45389-2_11
Download citation
DOI: https://doi.org/10.1007/978-3-031-45389-2_11
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-45388-5
Online ISBN: 978-3-031-45389-2
eBook Packages: Computer ScienceComputer Science (R0)