
Abstract
Chest radiography exams are still one of the main methods for detecting and diagnosing certain thoracic pathologies. This study evaluates the performance of a DenseNet in a multi-label classification task on radiography images, using focal loss as the loss function to address the class imbalance problem. For the experiments, 14 different types of findings were considered. Satisfactory results were obtained using the area under the ROC curve (AUC-ROC) as the metric, where the average performance across all classes was 0.861.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others
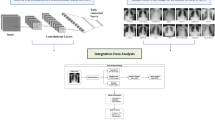


1 Introduction
Chest radiography is one of the most commonly used medical examinations for detection and diagnosis of thoracic pathologies. In Brazil, this examination is one of the oldest, cheapest, and most widely available [15]. However, there is a need for methods to assist radiology professionals since the analysis of thoracic abnormalities through radiographic images is subjective and can vary depending on the experience and perception of the physician [11].
Artificial neural networks (ANNs) are computational systems inspired by the functioning of the human brain, where hundreds of billions of interconnected neurons process information in parallel [16]. Deep neural networks (DNNs) are ANNs that have multiple hidden layers between their input and output [12]. These networks have been widely used and have achieved good results in the classification of medical images, especially convolutional neural networks (CNNs), a class of ANN commonly applied to image analysis. CheXNet, for instance, has 121 layers and was trained using a dataset of 100,000 frontal chest radiographs, and outperformed the performance of four radiologists [13].
Deep Learning-based techniques are widely employed in image classification tasks, due to their ability to automatically learn discriminative features from raw data [9]. One of the advantages of deep learning over other techniques is that it minimizes the need for preprocessing, segmentation, and feature extraction [14].
The application of hyperparameter optimization methods in deep neural networks to analyze the network configuration mechanisms by capturing specific problem characteristics, enhances the discriminative capability of the produced techniques. This work evaluated the performance of a dense convolutional neural network (DenseNet) using the Focal Loss function in a multi-label classification task on radiographic images.
2 Related Works
The search for methods to aid in the detection and diagnosis of pathologies from X-ray images has attracted the attention of many researchers worldwide, with several published works presenting promising results. However, obtaining a highly accurate and fully automated CNN-based method for medical diagnosis is still a challenging task.
Wang et al. [17] presented the ChestX-ray8, a dataset with 108,948 chest X-ray images from 32,717 unique patients, where each image can have multiple labels. In this study, a quantitative benchmarking of the performance of 4 pre-trained models in the classification of the 8 thoracic pathologies in this dataset was conducted, with the ResNet-50-based model [6] achieving the best results. Later, this dataset was expanded to ChestX-ray14, including 6 additional common thoracic pathologies.
Yao et al. [18] utilized an architecture that learns at multiple resolutions while generating weakly supervised saliency maps. The study also parameterized the LSE-LBA pooling function (Long-Sum-Exp with learnable Lower-Bounded Adaptation). The average AUC for the 14 labels in the ChestX-ray14 dataset in this work was 0.761.
Bhusal et al. [2] implemented a model using DenseNet and a modified cross-entropy loss to handle class imbalance, using specific weights for each class. The highest area under the ROC curve (AUC) was achieved for the Cardiomegaly finding, with a value of 0.896, and the lowest AUC for the Nodule finding with a score of 0.655. The average AUC for the 14 labels in the ChestX-ray14 dataset in this work was 0.762.
Rajpurkar et al. [13] developed ChesXNet, a 121-layer CNN trained on the ChestX-ray14 dataset. Rajpurkar et al. [13] compared the performance of the ChesXNet with four radiologists using the F1 metric, where the network outperformed the average score of the radiologists.
Zhao et al. [20] proposed a model called AM_DenseNet, which employs a dense connection network with an attention module after each dense block to optimize the feature extraction capability of the model. They used focal loss to address the class imbalance problem. The average AUC for the 14 pathology labels in the ChestX-ray14 dataset in this work was 0.8537.
In this work, the utilization of DenseNet-121 combined with focal loss (FL) addresses the class imbalance in the classification of thoracic pathologies in the ChestX-ray14 and CheXpert datasets. In contrast to some previous approaches, we opted to preserve the original DenseNet-121 architecture and instead performed fine-tuning and optimization of the hyperparameters of the focal loss function. Experiments were conducted comparing the results obtained with FL and cross entropy loss, allowing for the evaluation of the benefits of FL and highlighting its effectiveness in improving the model’s performance in the context of this task.
3 Background
3.1 DenseNet
DenseNet is a network that connects each of its layers to every other layer in a feed-forward fashion. A feed-forward neural network (FNN) is an artificial neural network in which the connections between nodes do not form a cycle [19, p. 73]. Unlike conventional convolutional neural networks, which have \(L\) layers and \(L\) connections (one between each layer and its subsequent direct connections), DenseNet has \(\frac{L(L+1)}{2}\) direct connections [7].
Preserving the feed-forward nature of the network, Huang et al. [7] proposes a connectivity pattern between the layers, where the \(l^{th}\) layer receives the feature maps from all previous layers, \(x_0,...,x_{l-1}\). Its input can be defined as:
where \([X_0,X_1,...,X_{l-1}]\) refers to the concatenation of the feature maps produced in layers \(0,...,l-1\). The \(H_l\) in this equation represents the multiple inputs into a single tensor. Figure 1 illustrates this connectivity between the layers.

Example of a Dense Block with 5 layers. This image illustrates how the connections between the layers occur [7].
DenseNet-121. The DenseNet-121 network consists of four dense blocks, where each block corresponds to a certain number of convolutional layers. Dense block 1 is composed of 6 dense layers, dense block 2 consists of 12 dense layers, dense block 3 consists of 24 dense layers, and dense block 4 consists of 16 dense layers. Each convolutional layer consists of batch normalization (BN), rectified linear unit (ReLU) activation function, and convolutional (Conv) operations for feature extraction.
DenseNet-121 uses a transition layer between two adjacent blocks, which consists of a 1\(\,\times \,\)1 convolution, followed by 2\(\,\times \,\)2 average pooling (calculating the average for each patch of the feature map). At the end of the last dense block, there is a pooling layer to which a classifier is attached, as shown in Fig. 2.

Structure of DenseNet-121.
3.2 Focal Loss
The Focal Loss (FL) is a loss function that addresses the problem of class imbalance by reformulating the Cross Entropy loss (CE) for binary classification [5], in order to reduce the weight of the loss assigned to well-classified examples. The CE function can be defined as:
where \(y\in \{\pm 1\}\), with \(p\) being the probability for the class with \(y = 1\) and \(p\in [0,1]\). \(p_t\) is defined as follows:
thus, we have \(CE(p,y) = CE(p_t) = -\log (p_t)\).
FL focuses the training on a sparse set of challenging examples, preventing a large number of easy negative examples from overwhelming the model during training [10]. It proposes the addition of a modulating factor \((1 - p_t)^\gamma \) to the cross-entropy loss, with an adjustable focus parameter \(y \ge 0\). Formally, the Focal Loss is defined as follows:
A variant of this equation, called \(\alpha \)-balanced can be used. This variant yields slightly improved precision compared to the non \(\alpha \)-balanced form [10], and is defined as:
it can also be observed that when \(\gamma = 0\) and \(\alpha _t = 1\), FL is equal to CE.
4 Materials and Methods
4.1 Dataset
This work utilized two datasets: ChestX-ray14 [17] and ChesXpert [8]. These datasets employ a multi-label approach, which means that each image may contain multiple pathologies. This section provides a description of each dataset used in this work, including information about the number of images, labels, as well as the origin of the data.

Number of images for each pathology in the ChestX-ray14 dataset.
ChestX-Ray14. The ChestX-ray14 dataset contains 112,120 radiograph images from 30,805 unique patients with image labels for 14 thoracic pathologies: Atelectasis, Cardiomegaly, Consolidation, Edema, Effusion, Emphysema, Fibrosis, Hernia, Infiltration, Mass, Nodule, Pleural Thickening, Pneumonia, and Pneumothorax. This dataset is an extension of the 8 common pathology patterns listed in the ChestX-ray8 dataset [17], which are represented in Fig. 4. This dataset was extracted from clinical data in the PACS (Picture Archiving and Communication Systems) at the NIH Clinical Center (National Institutes of Health Clinical Center).
The images have a size of 1024\(\,\times \,\)1024 pixels and are in PNG format. Natural Language Processing (NLP) techniques were used to extract the image labels, and the accuracy for the extracted labels was over 90% [17]. Figure 3 shows the number of images for each pathology present in the dataset, highlighting a significant class imbalance.

Example of 14 of the pathologies present in ChestX-ray14 dataset with their respective labels.
CheXpert. The CheXpert (Chest eXpert) dataset consists of 224,316 frontal and lateral chest radiographic images from 65,240 unique patients. Similar to ChestX-ray14, this dataset includes 14 observations: No Finding, Enlarged Cardiom., Cardiomegaly, Lung Lesion, Lung Opacity, Edema, Consolidation, Pneumonia, Atelectasis, Pneumothorax, Pleural Effusion, Pleural Other, Fracture, and Support Devices. These 14 observations are labeled as positive, negative, or uncertain, where the uncertain label can represent both the uncertainty of a radiologist in the diagnosis and the inherent ambiguity in the report [8]. This data was extracted from chest radiographs performed at the inpatient and outpatient centers of Stanford Hospital between October 2002 and July 2017, along with their associated radiological reports.

Example of 5 of the pathologies present in CheXpert dataset with their respective labels.
4.2 Preprocessing
For the ChestX-ray14 dataset, the pathology information for each image was preprocessed by converting it into an array of size 14, with each position representing each pathology. In this array, ‘0’ indicates the absence of the corresponding pathology and ‘1’ indicates the presence of the pathology. Then, the images in the dataset were preprocessed.
The images were divided into two subsets: a training set and a validation set. For each pathology, approximately 80% of the images were separated for training, and 20% were set aside for testing. This division was performed based on the unique patient identifier, ensuring that images from the same patient do not appear in both the training and testing sets. During the image preprocessing process, to standardize the pixel levels between 0 and 1, all intensities were divided by 255 (the maximum possible value). The feature maps were standardized by dividing each value by the standard deviation of the map, assuming a mean of 0, resulting in a standard deviation of 1 for the sample. Additionally, these images were resized to a resolution of 224\(\,\times \,\)224 pixels.
For the CheXpert dataset, information on present pathologies was also pre-processed. The uncertainty labels in this dataset, annotated as ‘−1’, were handled using the ‘U-Ones’ approach presented in [8], where these uncertainty labels were converted from ‘−1’ to ‘1’. Additionally, blank labels were converted to ‘0’. Five pathologies were selected from this dataset based on their predominance in the validation set and their presence in the ChestX-ray14 dataset (see Fig. 6).

Distribution of the selected classes in the CheXpert dataset.
The pathology information in CheXpert was converted into a vector of size 5, where ‘0’ indicates the absence of pathology and ‘1’ indicates the presence of pathology. The images in this dataset were preprocessed in the same way as the ChestX-ray14 dataset. Like ChestX-ray14, these images were also resized to a size of 224\(\,\times \,\)224 pixels.
4.3 Training Configuration
This work utilized a transfer learning approach known as fine-tuning, where the weights of a pretrained model are preserved (frozen) in some layers and adjusted (trained) in the remaining layers.
In this work, a DenseNet-121 network implemented in [3] was used. It was pretrained with weights from Imagenet [4]. The top classification layers were excluded. On top of this network, a global average pooling layer and the final sigmoid activation layer for classification were stacked.
Some layers of the pretrained model were frozen to keep their weights constant during training. Then, the model was compiled with the appropriate loss functions for each experiment and an Adam optimizer with a learning rate defined in the hyperparameter optimization process [1].
After that, the model underwent training and testing stages using the preprocessed datasets. The model was trained for 20 epochs with a batch size of 16, using an early stop callback to monitor the loss function. The minimum delta was set to 0.001, which defines the minimum change in the monitored value to qualify as an improvement, and the patience was set to 3, representing the number of epochs without improvement after which the training will be stopped.
Then, the fine-tuning stage was performed. The initial layers of the model were unfrozen, and the model was retrained with a lower learning rate. From there, the trained network is used to predict the labels of the images in the validation set of each dataset used in this work.
4.4 Hyperparameter Optimization Process
The hyperparameter optimization stage utilized the Tree-Structured Parzen Estimator (TPE) optimization algorithm, implemented in [1]. Three hyperparameter search spaces were defined with the goal of maximizing the AUC (ROC).
The first search space was for the learning rate of the network. This search space involved real values in the range [0.00001, 0.01], following a logarithmic pattern in value suggestions.
The second search space was for the \(\alpha \) parameter of the focal loss function. For the values in this search space, real values in the range [0.1, 1.0] were considered, also following a logarithmic pattern in value suggestions.
The third search space was related to the \(\gamma \) parameter of the focal loss function. In this search space, the values were set in the range [1.0, 5.0], and like the other two cases, it followed a logarithmic pattern in value suggestions.
In each optimization process, 15 trials were executed. At the end of these processes, the data from this study were saved in a CSV file, including their respective hyperparameters and AUC values.
5 Results and Discussion
In the first experiment, the proposed model was used to predict the 14 pathology labels of the ChestX-ray14 dataset. For this initial experiment, the binary cross-entropy loss (BCE) function, implemented in [3]. The Adam optimizer with a learning rate of 0.00001 was employed.
It was observed that the model handled the Hernia class better than the other classes, with an AUC value of 0.926. On the other hand, the Pneumonia class had the lowest AUC value of 0.647. In this experiment, the model achieved an AUC above 0.900 in three out of the fourteen classes, while five classes had AUC values above 0.800, and another five were above 0.700. Only for the Pneumonia class, the model achieved an AUC value below 0.700.
A new experiment was conducted using the ChestX-ray14 dataset. This time the focal loss (FL) was used as the loss function, with \(\alpha \) set to 0.173 and \(\gamma \) set to 2.89. The Adam optimizer with a learning rate of 0.00001 was employed. Once again, the Hernia class demonstrated the best performance among the other classes, achieving an AUC of 0.986. On the other hand, the Pneumonia class had the lowest performance with an AUC of 0.749. Notably, eight out of the fourteen categories achieved AUC values above 0.850, while only three categories had AUC values below 0.800, as depicted in Fig. 7.

Performance of the model with Focal Loss using AUC metric for the ChestX-ray14 dataset.
The results of the two experiments are compared in Table 1. It is evident that the model using FL as the loss function achieved superior performance for all pathologies, leading to a higher average AUC across the 14 classes in the FL experiment.
To further validate the proposed method, new experiments were conducted using the CheXpert dataset. The binary cross-entropy loss function was used, along with the Adam optimizer with a learning rate of 0.0002. The Pleural Effusion class achieved the highest performance, with an AUC of 0.874. It is also noting that the Atelectasis class had the lowest performance, with an AUC value of 0.698. Two classes had achieved results above 0.850, two classes had AUC values above 0.700, and only one class had performance below 0.700. The average AUC for this experiment was 0.790.
A new experiment was conducted using the CheXpert dataset. This time, FL was used as the loss function, with the parameter alpha set to 0.363 and gamma to 3.303. Additionally, the Adam optimizer was utilized with a learning rate of approximately 0.0002. There was a slight improvement compared to the previous experiment. The class with the highest AUC score was Edema with an AUC of 0.909 as depicted in Fig. 8. Two classes achieved AUC values above 0.900, and all classes had a performance above 0.700. The average AUC for this experiment was 0.820.

Model performance with FL using the AUC metric for the CheXpert database.
Table 2 compares the results of the experiments using CheXpert. Similar to the experiments using ChestX-ray14, it was observed that the model utilizing FL as the loss function achieved the best performance for all studied pathologies. Thus, the average for the 5 classes was higher in the experiment using FL.
We compared the results of our most promising experiment with the results of other studies that also used deep learning techniques to classify thoracic pathologies in the ChestX-ray14 dataset. The results shown in Table 3 indicate that the proposed model obtained a superior performance in terms of the AUC metric for 6 labels. Note that, for the Emfisem class, the difference between the proposed model and the work by Zhao et al. [20] is minimal, with a difference of approximately 0.002, similar to the class Atelectasis with a difference of 0.007. It is important to mention that the distribution of training sets may vary between different studies. To ensure a fair comparison, it would be ideal to reproduce the experiments using the exact same distribution of datasets.
In the experiments conducted using the ChestX-ray14 dataset, the impact of using focal loss on the overall network performance can be observed, resulting in an average performance gain of 5.5% points. However, for pathologies with fewer positive samples, the performance was notably better. In these cases, there was a greater performance improvement for the labels Pneumonia (10.2% points), Mass (6.9% points), Fibrosis (6.9% points), and Hernia (6.0% points), which are among the pathologies with fewer samples in the dataset. On the other hand, labels that have more positive samples in the dataset showed a performance gain of less than 5.0% points, such as Effusion (3.2% points), Infiltration (4.2% points), and Atelectasis (4.6% points).
A similar behavior can also be observed in the experiments conducted using CheXpert, which demonstrated an average performance gain of 3.0% points. Labels with a higher number of positive samples exhibited the lowest performance improvement, such as the Pleural Effusion label (0.6% points). Conversely, the label with the fewest positive samples in the dataset showed the highest performance gain, as seen in the case of the Consolidation label (5.3% points).
6 Conclusion
This work evaluated the performance of a DenseNet for the classification of 14 thoracic pathologies in a multi-label approach. Experiments were conducted with the proposed model using binary cross-entropy loss and also using Focal Loss to address the class imbalance issues present in the datasets.
The proposed model was validated using the ChestX-ray14 and CheXpert datasets. The results of the model using cross-entropy and Focal Loss were compared, and in these experiments, Focal Loss outperformed cross-entropy in all cases, as it effectively addressed the class imbalance problem present in both datasets.
The most promising experiment was conducted using Focal Loss to predict the 14 pathologies in the ChestX-ray14 dataset, achieving an average AUC score of 0.861, which was the highest among the researched works and outperformed the other methods in six out of the fourteen classes.
One of the major challenges of this work was the significant class imbalance in the utilized datasets. As future work, we intend to explore the structure of DenseNet further to improve the results, as well as apply this approach to computed tomography images.
It is important to emphasize that although the model produced satisfactory results, its use does not replace the diagnosis of a radiology professional. However, it is also important to highlight that the results generated by the proposed model can provide valuable references for these professionals.
This work was carried out with the support of the Coordination for the Improvement of Higher Education Personnel - Brazil (CAPES) - Financing Code 001, Maranhão Research Support Foundation (FAPEMA), National Council for Scientific and Technological Development (CNPq) and Brazilian Company of Hospital Services (Ebserh) Brazil (Proc. 409593/2021-4).
References
Akiba, T., Sano, S., Yanase, T., Ohta, T., Koyama, M.: Optuna: a next-generation hyperparameter optimization framework. In: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 2623–2631 (2019)
Bhusal, D., Panday, D., Prasad, S.: Multi-label classification of thoracic diseases using dense convolutional network on chest radiographs. arXiv preprint arXiv:2202.03583 (2022)
Chollet, F., et al.: Keras (2015). https://github.com/fchollet/keras
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: a large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255. IEEE (2009)
Good, I.J.: Rational decisions. In: Kotz, S., Johnson, N.L. (eds.) Breakthroughs in Statistics, pp. 365–377. Springer, New York (1992). https://doi.org/10.1007/978-1-4612-0919-5_24
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Huang, G., Liu, Z., Van Der Maaten, L., Weinberger, K.Q.: Densely connected convolutional networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4700–4708 (2017)
Irvin, J., et al.: Chexpert: a large chest radiograph dataset with uncertainty labels and expert comparison. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 590–597 (2019)
LeCun, Y., Bengio, Y., Hinton, G.: Deep learning. Nature 521(7553), 436–444 (2015)
Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2980–2988 (2017)
Marcos, L., Bichinho, G.L., Panizzi, E.A., Storino, K.K.G., Pinto, D.C.: Classificação da doença pulmonar obstrutiva crônica pela radiografia do tórax. Radiol. Bras. 46, 327–332 (2013)
Qian, Y., Fan, Y., Hu, W., Soong, F.K.: On the training aspects of deep neural network (DNN) for parametric TTS synthesis. In: 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 3829–3833. IEEE (2014)
Rajpurkar, P., et al.: Chexnet: radiologist-level pneumonia detection on chest X-rays with deep learning. arXiv preprint arXiv:1711.05225 (2017)
Santos, M.K., Ferreira, J.R., Wada, D.T., Tenório, A.P.M., Barbosa, M.H.N., Marques, P.M.D.A.: Inteligência artificial, aprendizado de máquina, diagnóstico auxiliado por computador e radiômica: avanços da imagem rumo à medicina de precisão. Radiol. Bras. 52, 387–396 (2019)
Wada, D.T., Rodrigues, J.A.H., Santos, M.K.: Aspectos técnicos e roteiro de análise da radiografia de tórax. Medicina 52(Suppl. 1), 5–15 (2019)
Wang, S.C.: Artificial neural network. In: Wang, S.C. (ed.) Interdisciplinary Computing in Java Programming, pp. 81–100. Springer, Boston (2003). https://doi.org/10.1007/978-1-4615-0377-4_5
Wang, X., Peng, Y., Lu, L., Lu, Z., Bagheri, M., Summers, R.: Chestx-ray8: hospital-scale chest X-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3462–3471 (2017)
Yao, L., Poblenz, E., Dagunts, D., Covington, B., Bernard, D., Lyman, K.: Learning to diagnose from scratch by exploiting dependencies among labels. arXiv preprint arXiv:1710.10501 (2017)
Zell, A.: Simulation neuronaler netze, vol. 1. Addison-Wesley Bonn (1994)
Zhao, J., Li, M., Shi, W., Miao, Y., Jiang, Z., Ji, B.: A deep learning method for classification of chest X-ray images. In: Journal of Physics: Conference Series, vol. 1848, p. 012030. IOP Publishing (2021)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Mendes, A.C., Pessoa, A.C.P., de Paiva, A.C. (2023). Multi-label Classification of Pathologies in Chest Radiograph Images Using DenseNet. In: Naldi, M.C., Bianchi, R.A.C. (eds) Intelligent Systems. BRACIS 2023. Lecture Notes in Computer Science(), vol 14196. Springer, Cham. https://doi.org/10.1007/978-3-031-45389-2_12
Download citation
DOI: https://doi.org/10.1007/978-3-031-45389-2_12
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-45388-5
Online ISBN: 978-3-031-45389-2
eBook Packages: Computer ScienceComputer Science (R0)