
Abstract
Since facial morphology can be linked to brain developmental problems, studies have been conducted to develop computational systems to assist in the diagnosis of some neurodevelopmental disorders based on facial images. The first steps usually include face detection and landmark identification. Although there are several libraries that implement different algorithms for these tasks, to the best of our knowledge no study has discussed the effect of choosing these ready-to-use implementations on the performance of the final classifier. This paper compares four libraries for facial detection and landmark identification in the context of classification of facial images for computer-aided diagnosis of Autism Spectrum Disorder, where the classifiers achieved 0.92, the highest F1-score. The results indicate that the choice of which facial detection and landmark identification algorithms to use do in fact affect the final classifier performance. It appears that the causes are related to not only the quality of face and landmark identification, but also to the success rate of face detection. This last issue is particularly important when the initial training sample size is modest, which is usually the case in terms of classification of some syndromes or neurodevelopmental disorders based on facial images.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others


1 Introduction
Anthropometry is the science that studies the measurements of the human body including height, weight and size of body components [11]. The measurements can be done directly, with measuring equipment such as measuring tapes, or indirectly, using radiography images, three-dimensional images captured by stereophotogrammetry or two-dimensional images captured by digital cameras [31].
Several studies have suggested that facial morphology can be linked to brain developmental problems [2, 6, 9, 13, 32]. For instance, studies of facial anthropometric measures in individuals with Autism Spectrum Disorder (ASD) and individuals with typical development (TD) have revealed significant differences between these two groups, such as the distance between the pupils, ear format, strabismus, head circumference [2, 23, 27, 29]. These results motivate the use of machine learning approaches to classify ASD versus TD individuals, based on anthropometric facial features, to aid ASD diagnosis.
ASD is a neurodevelopmental, polygenic and multifactorial disorder with evidence of genetic and environmental factors contributing to its etiology [10, 14, 20, 24]. Individuals with ASD exhibit persistent social communication impairments, and also lack the ability to develop, maintain and understand relationships, and show restricted and repetitive patterns of behavior, interests, and activities. These symptoms appear during childhood and can impair the person’s daily life [3, 18]. An early and correct diagnosis is crucial for appropriate intervention. The diagnosis is clinical and expensive, since it requires trained health professionals to apply the instruments, mostly questionnaires, and observation routines of the child’s behavior [22]. Therefore, to increase accessing the ASD diagnosis, computer-aided diagnosis systems could be used for large-scale screening for posterior analysis by a specialist. In order to decrease the financial cost and facilitate using such systems, the use of two-dimensional facial images captured by digital cameras or smartphones is preferred than, for instance, three-dimensional images captured by stereophotogrammetry devices [2, 12, 26], since they can be more easily achieved considering the popularization of mobile devices.
In fact, promising results related to neurodevelopmental disorders have been achieved using two-dimensional facial images captured by digital cameras [16, 33]. The computational pipeline of analysis usually consists of three steps: 1) face detection and landmark identification, 2) feature extraction and 3) classifier induction. Although there are several libraries that implement different algorithms for the first step, to the best of our knowledge no study has discussed the effect of the choice of these ready-to-use implementations on the performance of the final classifier.
This paper investigates the effect of using four image processing libraries for facial detection and landmark identification on the classification results of facial images for computer-aided diagnosis of ASD. While a face detection algorithm may cause training sample reduction by discarding images when no faces were detected, a landmark detection algorithm may interfere with the correct extraction of features from the anthropometric measurements. Both issues can affect the final classifier and are explored in this paper.
2 Methods
Four image processing libraries were compared for face detection and landmark identification tasks. In order to investigate the impact of these libraries on final classification performance, we performed two experiments to test two hypothesis:
-
H1: the number of training images with successful face detection, combined with correct face detection and landmark identification, will affect the performance of the final classifier;
-
H2: using the same training images, applying different detection and landmark identification algorithms affects the performance of the final classifier.
Both hypotheses were tested by performing the five-modules process depicted in Fig. 1. In summary, the images of an initial training set were acquired following the protocol described in Sect. 2.1 and pre-processed as described in Sect. 2.2 (modules 1 and 2). Each preprocessed image was submitted to different face and landmark detection algorithms to identify five landmark sets: one for each image processing library, except for MediaPipe which was used twice (module 3, described in Sect. 2.3). Each landmark set was used to extract a set of geometric features based on the distance between each pair of landmarks (module 4, described in Sect. 2.4), resulting in five different feature datasets. In these five datasets, each instance is the feature vector of an image. Since the face detection algorithms usually are not able to detect the face in all images (module 3), the five datasets have not the same number of instances. Therefore, two experiments were performed: 1) using each dataset exactly as it is; and 2) using the datasets composed of only the feature vectors of the images where the face was detected by all face detection algorithms executed in module 3. Therefore, experiment 1 evaluates the effect of the face detection on the results (testing hypothesis H1), whereas experiment 2 evaluates the effect of the landmark identification (in the same faces) on the classifier performance (testing hypothesis H2). These datasets are used separately to train and test several classifiers (module 5, described in Sect. 2.5). Finally, a statistical analysis was performed for hypotheses testing (Sect. 2.6).

Overview of the proposed method.
2.1 Image Acquisition Protocol
All images were captured with a Nikon Coolpix L120 compact camera using the protocol shown in Fig. 2. In each acquisition, the camera was attached to a tripod fixed at a distance of 50 cm from the chair where the volunteer was accommodated. The chair was placed against the wall, and the volunteer was instructed to remain with his back fully resting on the chair. A white wall was chosen as the photo background, where a red band 50 cm by 5 cm was placed in order to be posteriorly used as a reference for normalizing the images and estimating distortion.

Protocol used to capture the images, showing the correct position of the individual and the band used as reference for normalization.
The volunteers were instructed to remain with a facial expression as neutral as possible and five front facial photographs were taken. A video was recorded when neutral expression facial image was not possible or if the face was inclined. Thus, a subsequent video analysis allowed selecting the best frame.
Images were captured from 43 ASD and 74 TD children and adolescents ranging from 5 to 18 years of age. The diagnosis of the ASD participants was confirmed by a reference Hospital the Clinics Hospital of the University of São Paulo and the photographs were taken after the patient’s follow-up visit. The TD group consisted of volunteers invited by email. All underwent screening by an infant psychiatrist specialized in ASD to confirm the absence of ASD and/or clinical evidence of genetic syndromes. All participants were authorized by the parents or legal guardians through an informed consent signed at the beginning of each data collection session.
This project was approved by the Ethics Board and of the School of Arts, Sciences and Humanities of University of Sao Paulo, protocol number 1.669.832 at August 8th, 2016. All experiments were performed in accordance with the Ethics Board requirements. The informed consent was obtained from all participants and/or their legal guardians.
2.2 Image Preprocessing and Band Detection (Modules 1 and 2)
We acquired more than one frontal image from each volunteer. The best image was selected based on two criteria: facial neutrality and proportion of width and height of the reference band in order to avoid image distortion.
The image preprocessing was performed to rotate and crop all the images. The rotation intends to correct the lateral face inclination and was performed according to the following steps: eye region detection using Haar cascades; pupil localization; tracing a line passing over the pupil points; calculation of the angle \(\theta \) formed by this line and the horizontal axis; image rotation according to \(\theta \). Finally, the images were cropped in order to remove the black background resulting from the rotation operation.
The steps for reference band detection were: (i) application of a bilateral filter for image smoothing, (ii) edge detection using the Canny method [8], (iii) application of dilation and erosion operations to correct discontinuities on the edges, (iv) detection of the band contour using the method findContours from OpenCV library [30] and (v) calculation of the band width and height.
2.3 Face Detection and Landmark Identification (Module 3)
Four image processing libraries were tested for the task of face detection and landmark identification: Dlib [15], OpenCV [7], OpenFace [4] and MediaPipe [21]. OpenCV and Dlib have multiple face detection algorithms available. This study chose the algorithms based on CNN (Convolutional Neural Network) and DNN (Deep Neural Networks), respectively, since they represent the state of art in image processing. MediaPipe uses a face detection algorithm based on BlazeFace solution [5] and OpenFace also uses a CNN algorithm to detect faces. After the face detection, all images were manually inspected to assure that no mistake was made in this step. At this point, each library may have correctly detected a different number of faces from the initial set of images.
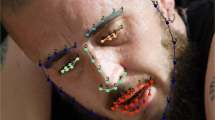
The next step is the landmark identification in each detected face. The landmark identification algorithms of Dlib, OpenCV and OpenFace libraries detect 68 landmarks (Fig. 3), whereas the MediaPipe’s algorithm detects 438 landmarks. Thus, two landmark sets were identified using MediaPipe: 1) using only the 68 landmarks closest to the ones detected by the first three libraries (MediaPipe 68); and 2) using the previous 68 landmarks and additional 61 points corresponding to the facial contour (MediaPipe 129) (Fig. 3E). The first landmark set is meant to evaluate the influence of the quality of the identification of the same 68 landmarks on the classifier performance, whereas the second landmark set is meant to evaluate the influence of a higher number of landmarks. Therefore, five landmark sets were obtained and compared in this study (Table 1).

The 68 landmarks present in DlibCNN, OpenCVDNN, OpenFace, MediaPipe 68 and MediaPipe 129 landmark sets. Source image from [1].
2.4 Feature Extraction and Experiment Split (Module 4)
For each landmark set output from module 3 (Table 1), the Euclidean distance between each pair of landmarks, normalized by the reference band dimensions, was calculated, corresponding to a feature. More specifically, for each pair of landmarks \(p (x_1, y_1)\) and \(q (x_2, y_2)\), each landmark represented by a coordinate (x, y), the normalized Euclidean distance \(d_n\) is calculated according to Eq. 1, where w and h are the reference band width and height (calculated as described in Sect. 2.2), respectively:
The feature dataset obtained from each landmark set described in Table 1 was used in Experiment 1. In experiment 2, only features from images where the face was correctly detected by all face detection algorithms were used.
2.5 Classifier Development (Module 5)
The last module of the proposed pipeline (Fig. 1) consists in training and evaluating several classifiers varying the procedures for dataset preprocessing, dimension reduction and classifier induction. Here we describe these procedures and how the parameter tuning and performance evaluation were performed.
Dataset Preprocessing. Three preprocessing tasks were applied on the dataset: initial feature filtering, Min-Max normalization and class balancing.
In the initial feature filtering, when two features were highly correlated (Pearson correlation > 0.98), only one was kept.
Min-max normalization was applied on the feature values. For this, after identification of the maximum and minimum values of each feature X in the dataset (\(X_{max}\) and \(X_{min}\), respectively), the original value \(X_i\) is transformed into a new value \(X'_i = (X_i - X_{min})/(X_{max} - X_{min})\).
For class balancing, four approaches were considered: i) undersampling, ii) oversampling with four variants of SMOTE algorithm [25] (Default, SVM, Borderline and KMeans Smote [17]), iii) combination of under and over sampling with SMOTE Tomek, and iv) no balancing.
Dimension Reduction. Dimension reduction methods are extremely important for classification tasks because they eliminate redundant features and can increase classifier performance.
Filter-type feature selection methods tend to have a lower computational cost than wrapper-type methods. In this paper, the implementation of the scikit-learn libraries [28] and skfeature [19] libraries were used and seven different algorithms were applied:
-
Principal Component Analysis (PCA), which performs feature extraction by transforming the initial set into a new set containing only the major components;
-
Minimum Redundancy Maximum Relevance (mRMR), which performs the selection of features based on two criteria: one is the minimum criterion of redundancy between pairs of features and the other is the maximum relevance through the measurement of information;
-
Correlation-based Feature Selection (CFS), which performs the selection of features considering that a suitable subset contains features highly correlated with the target class, but little correlated with each other;
-
Fast Correlation-based Filter (FCBF), which performs the selection of features considering the main idea of the CFS method, but calculating the correlation measure based on the entropy concept of information theory;
-
ReliefF, which performs the selection of features by means of a relevance ranking of each feature;
-
Robust Feature Selection (RFS), which performs the feature selection through sparse dictionary learning;
-
Random Forest Select, which performs the feature selection based on the Random Forest classifier.
Classifier Induction (Hyperparameter Tuning and Performance Estimation). Six classifier induction algorithms were used: K-Nearest Neighbors (KNN), Support Vector Machines (SVM), Gaussian Naïve Bayes (NB), Neural Networks (NN), Random Forests (RF) and Linear Discriminant Analysis (LDA).
Hyperparameter tuning of the classifier induction algorithms was performed using a grid search approach to select the hyperparameter values that maximize the classifier f1-score, estimated by stratified 10-fold cross-validation. In each fold of the cross-validation, the synthetic instances produced by the class balancing algorithm were excluded from the test sample. Table 2 shows the hyperparameters and the tested values that were tuned for each classifier. Default parameters were used for Gaussian Naive Bayes classifier.
In summary, all combinations of dataset balancing strategy, dimension reduction and classifier induction algorithm (Table 3) were evaluated, totaling 294 combinations. To measure performance, the F1-score of each classifier resulting from each combination was estimated via stratified 10-fold cross-validation, with no synthetic data in the test folds. In addition, confidence intervals were calculated with 95% confidence.
2.6 Statistical Analysis and Comparison
As described in Sect. 2.5, several classifiers were inducted using different combinations of class balancing algorithms, dimension reduction and classifier induction algorithms (Table 3). Considering the ten folds of the cross-validation, 2940 classifiers were inducted from each dataset (i.e., from each landmark set). Comparing the F1-scores of learned classifiers using each of these combinations in each fold, varying only the landmark set (Table 1), constitutes a test to detect differences in “treatments” across multiple test attempts, where the “treatments” are the use of different libraries for face detection and landmark identification.
Therefore, a table \(F_{2940\times 5}\) was created where F[i, j] is the F1-score obtained by the classifier inducted using the combination i of class balancing algorithms, dimension reduction, classifier induction algorithm and fold using the landmark set j. As the F1-scores do not present a normal distribution, Friedman’s non-parametric test was applied using the F1-scores obtained in experiments 1 and 2 to test the hypotheses H1 and H2, respectively. Considering a critical P-value of 0.05, an inferior P-value means that there is a significant difference between the F1-score obtained using different libraries for face detection and landmark detection.
In addition, in order to investigate if the H1 and H2 test results can be dependent on the classifier induction algorithm, the same test was repeated using only the F1-scores of classifiers inducted by the same algorithms. For these tests a Bonferroni-Holm correction was applied to correct the P-values due to the execution of the six tests.
The Friedman test only evaluates if the average F1-score is significantly different among the five landmark sets. To test if there is a significant difference between each pair of landmark sets, the Wilcoxon test was applied.
3 Results and Discussion
Table 4 (rows corresponding to “Experiment 1”) shows the number of images where the face was correctly detected by each library. From an initial set of 117 images (43 images from ASD and 74 images from TD individuals), the face detection algorithms performed differently, detecting the face in 63% to 89% of the images. MediaPipe was the library that detected fewer faces, whereas OpenCV using the DNN algorithm was the library that detected more faces. Only 62 images (53%) had the face correctly detected by all libraries. These images were used to compose the five landmark sets in Experiment 2 (Table 4 - rows corresponding to “Experiment 2”).
Table 5 shows the P-values resulting from the Friedman test performed on all inducted classifiers, as well as for each classifier induction algorithm separately, for both experiments. Considering all learned classifiers (Table 5, row “ALL CLASSIFIERS”), the results show that there is a significant difference between the F1-scores obtained when using different landmark sets (i.e., different libraries for face detection and landmark identification), in both experiments 1 and 2 (P-values < 0.001), allowing that H1 and H2 are accepted. That means that both correct face detection and landmark identification have a significant effect on the final classification. All P-values are also below the critical value of 0.05 considering the test performed for each classifier induction separately (Table 5, rows “SVM” to “LDA”). However, three classifier induction algorithms had their P-values closer to the critical value: SVM in Experiment 1 and Naive Bayes and Random Forests in Experiment 2. This may indicate that different classifier induction algorithms have different susceptibility to data variation obtained using these libraries. However, more experiments should be conduct to investigate this issue.
Table 6 shows the P-values achieved using the Wilcoxon test for each pair of landmark sets in both experiments. In Experiment 1, the results show that the F1-scores achieved using the dlibCNN and OpenCVDNN landmark sets are not significantly different, as well as using MediaPipe 68 and MediaPipe 129. DlibCNN and OpenCVDNN are the landmark sets based on the highest number of images (101 and 104 detected faces, respectively - Table 4) whereas MediaPipe 68 and MediaPipe 129 landmark sets are based on exactly the same images. In Experiment 2, where all landmark sets were extracted from the same 62 images, all P-values were \(< 0.05\), indicating that F1-scores are significantly different between each pair of landmark sets. These results indicate that the number of training images not only affect the classifier performance but also the quality of face and landmark identification. In addition, the significant difference between MediaPipe 68 and MediaPipe 129 only in Experiment 2 may indicate that the additional landmarks in MediaPipe 129 improved the classifier performance when there was a smaller number of training images.
Considering the use of these landmark sets to the problem of ASD x TD classification, Fig. 4 shows the highest F1-score (estimated by 10-fold cross-validation) achieved using each landmark set in each experiment. OpenFace, OpenCVDNN and DlibCNN had the best results in Experiment 1, highlighting that OpenFace and DlibCNN presented the narrowest confidence intervals. In fact, in Experiment 1 these three landmark sets are those based on the highest number of detected faces (Table 4). It is noteworthy that, although based on a lower number of images (95 detected faces), the OpenFace landmark set had the highest F1-score (0.9184) with an accuracy of 0.8861, precision of 0.8548 and recall of 1.0. This result was achieved using SMOTE Tomek for class balancing, PCA for dimension reduction and LDA for classifier induction algorithm. The lowest F1-score (0.8436) was achieved using MediaPipe 64, which is consistent with the fact that this landmark set is based on the lowest number of images (74 - Table 4). MediaPipe 129 had a higher F1-score than MediaPipe 64 (0.9029), based on the same images but with additional landmarks. However, it was observed that these two landmark sets are not significantly different in the statistical test using all generated classifiers (Table 6 - Experiment 1). Such relative performance of these landmark sets (DlibCNN, OpenCVDNN and OpenFace presenting higher F1-scores than MediaPipe 64 and MediaPipe 129) was similar in all inducted classifiers (data not shown). In Experiment 2 all F1-scores decreased, which is consistent with the fact that all landmark sets were based on a lower number of images (62). Therefore, it can be seen that not only the correct face detection and reference points are important, but also the number of images used to train a model. The best classifier had a accuracy of 0.88, precision of 0.83, recall of 1.0 and F1-score of 0.8981.

The highest F1-score obtained using each landmark set in Experiment 1 (Fig A) and Experiment 2 (Fig B). The bar errors correspond to a 95% confidence interval.
4 Conclusion
This paper investigated the effect of employing different image processing libraries on the final result of facial image-based classifiers using ASD x TD classification as case-study. Two hypotheses were tested: that different face detection rates (influence the training sample size), in addition to the landmark identification quality, influence the final classification (H1) and that, using exactly the same images, the face detection and landmark identification per se influence the final classification (H2). The results enabled accepting both hypotheses in this case study.
The analysis of the pairwise differences, as well as of the F1-scores obtained by the different landmark sets in both experiments, indicate that libraries with a higher success rate in face detection (DlibCNN, OpenCVDNN and OpenFace) tend to produce higher F1-score, and thus more suitable.
Finally, considering the problem of ASD x TD classification, after testing several combinations of image processing libraries, dataset balancing, dimension reduction and classifier induction algorithms, this study achieved the F1-score of 0.9184, accuracy of 0.8861, precision of 0.8548 and recall of 1.0, which is important for computer-aided diagnosis. To enhance ASD analysis through face detection, more data from individuals with ASD and controls are crucial.
References
Face recognition database (2005). http://cbcl.mit.edu/software-datasets/heisele/facerecognition-database.html
Aldridge, K., et al.: Facial phenotypes in subgroups of prepubertal boys with autism spectrum disorders are correlated with clinical phenotypes. Mol. Autism 2(1), 15 (2011)
Association, A.P., et al.: Diagnostic and statistical manual of mental disorders (DSM-5®). American Psychiatric Pub (2013)
Baltrusaitis, T., Robinson, P., Morency, L.P.: Constrained local neural fields for robust facial landmark detection in the wild. In: Proceedings of the IEEE International Conference on Computer Vision Workshops, pp. 354–361 (2013)
Bazarevsky, V., Kartynnik, Y., Vakunov, A., Raveendran, K., Grundmann, M.: BlazeFace: sub-millisecond neural face detection on mobile GPUs. CoRR abs/1907.05047 (2019)
Boehringer, S., et al.: Syndrome identification based on 2D analysis software. Eur. J. Hum. Genet. 14(10), 1082–1089 (2006)
Bradski, G.: Opencv library. Dr. Dobb’s Journal of Software Tools (2000)
Canny, J.: A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 6, 679–698 (1986)
DeMyer, W., Zeman, W., Palmer, C.G.: The face predicts the brain: diagnostic significance of median facial anomalies for holoprosencephaly (arhinencephaly). Pediatrics 34(2), 256–263 (1964)
Deth, R., Muratore, C., Benzecry, J., Power-Charnitsky, V.A., Waly, M.: How environmental and genetic factors combine to cause autism: a redox/methylation hypothesis. Neurotoxicology 29(1), 190–201 (2008)
Farkas, L.G.: Anthropometry of the Head and Face. Raven Pr (1994)
Gilani, S.Z., et al.: Sexually dimorphic facial features vary according to level of autistic-like traits in the general population. J. Neurodev. Disord. 7(1), 14 (2015)
Hammond, P., et al.: 3D analysis of facial morphology. Am. J. Med. Genet. A 126(4), 339–348 (2004)
Johnson, C.P., Myers, S.M.: Identification and evaluation of children with autism spectrum disorders. Pediatrics 120(5), 1183–1215 (2007)
King, D.E.: Dlib-ml: a machine learning toolkit. J. Mach. Learn. Res. 10, 1755–1758 (2009)
Kumov, V., Samorodov, A.: Recognition of genetic diseases based on combined feature extraction from 2D face images. In: 26th Conference of Open Innovations Association (FRUCT). IEEE (2020)
Lemaître, G., Nogueira, F., Aridas, C.K.: Imbalanced-learn: a python toolbox to tackle the curse of imbalanced datasets in machine learning. J. Mach. Learn. Res. 18(17), 1–5 (2017)
Levy, S.E., Mandell, D.S., Schultz, R.T.: Autism 374, 1627–1638 (2009)
Li, J., et al.: Feature selection: a data perspective. arXiv:1601.07996 (2016)
Lord, C., Cook, E.H., Leventhal, B.L., Amaral, D.G.: Autism spectrum disorders. Neuron 28(2), 355–363 (2000)
Lugaresi, C., et al.: MediaPipe: a framework for perceiving and processing reality. In: Third Workshop on Computer Vision for AR/VR at IEEE Computer Vision and Pattern Recognition (CVPR) 2019 (2019)
Mandell, D.S., Novak, M.M., Zubritsky, C.D.: Factors associated with age of diagnosis among children with autism spectrum disorders. Pediatrics 116(6), 1480–1486 (2005)
Miles, J., Hadden, L., Takahashi, T., Hillman, R.: Head circumference is an independent clinical finding associated with autism. Am. J. Med. Genet. 95(4), 339–350 (2000)
Muhle, R., Trentacoste, S.V., Rapin, I.: The genetics of autism. Pediatrics 113(5), e472–e486 (2004)
Chawla, N.V., Bowyer, K.W., Lawrence, O.H., Philip Kegelmeyer, W.: Smote: synthetic minority over-sampling technique. J. Artif. Intell. Res. 16, 321–357 (2011)
Obafemi-Ajayi, T., et al.: Facial structure analysis separates autism spectrum disorders into meaningful clinical subgroups. J. Autism Dev. Disord. 45(5), 1302–1317 (2015)
Ozgen, H., et al.: Morphological features in children with autism spectrum disorders: a matched case-control study. J. Autism Dev. Disord. 41(1), 23–31 (2011)
Pedregosa, F., et al.: Scikit-learn: machine learning in Python. J. Mach. Learn. Res. 12, 2825–2830 (2011)
Rodier, P.M., Bryson, S.E., Welch, J.P.: Minor malformations and physical measurements in autism: data from Nova Scotia. Teratology 55(5), 319–325 (1997)
Suzuki, S.: Topological structural analysis of digitized binary images by border following. Comput. Vis. Graph. Image Process. 30(1), 32–46 (1985)
Weinberg, S.M., Naidoo, S., Govier, D.P., Martin, R.A., Kane, A.A., Marazita, M.L.: Anthropometric precision and accuracy of digital three-dimensional photogrammetry: comparing the genex and 3dMD imaging systems with one another and with direct anthropometry. J. Craniofac. Surg. 17(3), 477–483 (2006)
Zhao, Q., et al.: Digital facial dysmorphology for genetic screening: hierarchical constrained local model using ICA. Med. Image Anal. 18(5), 699–710 (2014)
Zhao, Q., Yao, G., Akhtar, F., Li, J., Pei, Y.: An automated approach to diagnose turner syndrome using ensemble learning methods. IEEE Access 8, 223335–223345 (2020)
Acknowledgments
We thank the patients and their families that allowed the execution of this research, as well as the team of the Autism Spectrum Program of the Clinics Hospital (PROTEA-HC). This study was funded by Brazilian National Council of Scientific and Technological Development, (CNPq) (grants 309330/2018-1, 157535/2017-7 and 309030/2019-6) and Scientific and Technological Initiation Program at University of Sao Paulo (PIBIC/PIBIT-CNPq/USP 2020/2021), the São Paulo Research Foundation (FAPESP) - National Institute of Science and Technology - Medicine Assisted by Scientific Computing (INCT-MACC) - grant 2014/50889-7, Sao Paulo Research Foundation (FAPESP) grants #2017/12646-3, #2020/01992-0, Coordenação de Aperfeiçoamento de Pessoal de Nível Superior – Brasil (CAPES), Dean’s Office for Research of the University of São Paulo (PRP-USP, grant 18.5.245.86.7) and the National Health Support Program for People with Disabilities (PRONAS/PCD) grant 25000.002484/2017-17.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Michelassi, G.C. et al. (2023). Classification of Facial Images to Assist in the Diagnosis of Autism Spectrum Disorder: A Study on the Effect of Face Detection and Landmark Identification Algorithms. In: Naldi, M.C., Bianchi, R.A.C. (eds) Intelligent Systems. BRACIS 2023. Lecture Notes in Computer Science(), vol 14196. Springer, Cham. https://doi.org/10.1007/978-3-031-45389-2_18
Download citation
DOI: https://doi.org/10.1007/978-3-031-45389-2_18
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-45388-5
Online ISBN: 978-3-031-45389-2
eBook Packages: Computer ScienceComputer Science (R0)