
Abstract
The health domain has been largely benefited by Machine Learning solutions, which can be used for building predictive models to support medical decisions. But, for increasing the reliability of these systems, it is important to understand when the models are prone to failures. In this paper, we investigate what can we learn from the instances of a dataset which are hard to classify by Machine Learning models. Different reasons may explain why one or a set of instances are misclassified, despite the predictive model used. They can be either noisy, anomalous or placed in overlapping regions, to name a few. Our framework works at two levels: the original base dataset and a meta-dataset built to reflect the hardness level of the instances. A two-dimensional hardness embedding is assembled, which can be visually inspected to determine sets of instances to scrutinize better. We show some analysis that can be undertaken in this hardness space that allow to characterize why some of the instances are hard to classify, with case studies on health datasets.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others


1 Introduction
Machine Learning (ML) models are regarded as promising solutions for revolutionizing healthcare [1]. These data-driven techniques may leverage knowledge from the large volumes of data continuously gathered by health systems and agents [2]. As a recent example, different predictive models were built during the COVID-19 pandemic to assist diagnosis and prognosis of patients using hospital data [3, 4]. Nonetheless, there are issues still preventing the widespread usage of ML predictive models in health decision making and planning. Some concerns are the risk of bias and inappropriate or incomplete model performance evaluation [5].
Given that health databases are not collected with the objective of data analysis in the first place, the Data Scientist and ML practitioner must deal with these issues by relying on their own experience or on ad-hoc procedures, which can bias the achieved results. Data-centric frameworks have recently been proposed to aid these professionals in better assessing data quality and taking potential corrective measures, which will result in more reliable and trustful predictive models [6, 7].
One fruitful direction is to assess and monitor learning performance for each dataset instance and prevent relying only on averages over an entire dataset, as it is common practice [8]. Furthermore, examining the performance at the instance level can reduce biases in the evaluation of ML models, as specific important groups of instances can be mistaken by the ML models, despite the obtainment of an overall high average predictive performance. This makes it important to know which instances are systematically misclassified by ML models and why they are so, a concern that has led to the recent literature of instance hardness analysis [9].
According to Smith et al. [9], instance hardness can be measured as the average misclassification error of a pool of diverse classifiers when predicting the label of such instance. This metric allows identifying instances in a dataset that are inherently difficult to have their label predicted, despite of the classification technique used. However, going beyond, the literature also presents hardness meta-features which prospect possible reasons why the instance is hard to classify [9, 10].
Recently, a framework for relating the classification performance of classifiers of distinct biases and the values of different hardness meta-features was framed [8, 11]. The relationship of this information is used to produce a 2-D hardness embedding where the instances are linearly distributed according to their hardness level. Here this framework is extended for gaining data-centric insights by taking advantage of the organization of the dataset observations in the hardness embedding. These analyzes take place at two levels: the original input features and the meta-features. Inspecting general trends in the input features of the hard instances of a dataset can be particularly informative and allow to involve the data domain experts in the ML pipeline. On the other hand, looking at the hardness meta-features allows Data Scientists to understand structural problems with such instances, which may be preventing the obtainment of a better predictive accuracy. This dual interplay allows for taking into account the main stakeholders involved in data analysis for decision support.
In particular, our framework is applied here to datasets from the health domain, which is a critically requester reliable predictive models. As case studies, we consider a set of COVID prognosis datasets from Brazil, one of the countries hit hardest by the pandemic. The classification problem consists in predicting whether a COVID-hospitalized patient will develop into an aggravated condition or not, information that can support decision making at both clinical and management levels at hospitals. Our framework contributes on the following ways:
-
Providing a principled approach for identifying hard instances in a dataset: taking advantage of the hardness embedding of a dataset, where easy and hard instances are interposed, different types of analyzes are made possible. One of them is to define hardness and easiness footprints, which are dense regions of the representation space which encompass more hard and easy instances, respectively. This allows to define a principled strategy for choosing sets of instances to be further examined;
-
Providing meaningful insights on data quality and structure: the hardness profile of a dataset can be inspected for gaining insights about where and why ML models are failing;
-
Being actionable by different stakeholders: we combine two levels of knowledge. While inspecting relationships of the input features that lead to increased hardness levels can be a valuable tool for better data understanding and auditing with the aid of domain experts, the meta-features allow to prospect structural problems in the data which can be informative for Data Science and ML practitioners.
This paper is structured as follows: Section 2 presents some related work. Section 3 presents our formulation. Section 4 presents some experimental results. Section 5 concludes the paper with some discussions.
2 Related Work
ML techniques are data-hungry and a common mistake is to consider that more data will always result in more accurate predictive models. But some issues present in real data, such as noise, sparse regions and outliers, can impair the ML system’s performance, trustfulness and acceptance. Therefore, data quality plays a central role in developing reliable ML systems.
Since predictions inside health scenarios involve highly delicate matters, data quality assessment and cleaning are even more critical. Some recent works have used data-centered approaches to formulate strategies allowing to: assess how difficult it is to predict the class of each instance in a dataset [6, 8, 13]; understand why some instances are frequently misclassified, while also trying to explain the behavior of classifiers for such instances [8, 14]; predict test instances that will be reliably classified or not [7]; remove hard or ambiguous instances in a data sculpting strategy to improve ML algorithms performance [6, 13]; and identifying anomalous regions of the input feature space offering useful explanations and insights about data quality as well as model performance [6, 8, 15]. But there are still gaps to be filled that may help increasing the acceptance of such tools. One of them is providing more interpretable and actionable insights to the different stakeholders involved in data analysis.
In order to increase the trustfulness and acceptance of AI systems, it is imperative that their decisions are transparent and can be scrutinized by different stakeholders. This has lead to the increase in the Explainable Artificial Intelligence (XAI) area [16]. Many XAI platforms and strategies are currently available and most of them focus on evaluating how the predictive input features influence the results of the ML models, such as permutation tests [17] and Shapley values [18]. But there are other layers of explainability that are not so commonly explored in the literature, despite having potential to offer rich insights for better understanding the strengths and weaknesses of the ML models.
One of them is working at a meta-level where general properties of the data that may lead to impairments in a good predictive performance are identified and characterized [9, 19]. Taking steps towards this direction, we can extract local rules based on at most two input features for subsets of instances a given model struggles to classify correctly, that is, instances the model regards as hard to classify [15]. Our work follows a similar direction, but with a more general approach for finding and characterizing the hard instances from a dataset. While combining the outputs of many models, we also leverage on meta-features able to describe why some instances are hard to classify, giving insights at different yet complementary perspectives.
3 Formulation
Figure 1 presents an overview of the methodology followed in our paper. Given a dataset \(\mathcal D\), a set \(\mathcal F\) of hardness meta-features describing the level of difficulty in classifying each instance in \(\mathcal D\) according to different perspectives is extracted. Algorithmic performance \(\mathcal P\) is registered for each individual instance of the dataset for a pool of classification algorithms \(\mathcal A\). Joining \(\mathcal F\) and \(\mathcal P\), a hardness embedding is produced where the instances are placed so as to present linear trends of difficulty level, from bottom right (easy) to top left (hard). Next two types of analyzes are performed. One of them involves defining regions concentrating hard and easy to classify instances. They are called hardness and easiness footprints, respectively. By extracting patterns from the opposing footprints, we are able to obtain insights on instance hardness at different levels and perspectives. The second approach involves a visual inspection of the hardness embedding for identifying observations lying in regions of interest to be inspected.

Overview of the proposed framework.
3.1 Instance Hardness Analysis
Let us define \(\mathcal D\) formally as containing n pairs of labeled observations (\(\textbf{x}_i , y_i \)). Each \(\textbf{x}_i \in \mathcal X\) is an instance described by m input features and is labeled in \(y_i \in \mathcal Y\), where \(\mathcal Y\) is a discrete and non-ordered set of classes. In addition, let \(h: \mathcal X \rightarrow \mathcal Y\) denote a classification hypothesis, that is, a ML predictive model generated from \(\mathcal D\). The Instance hardness of an instance \(\textbf{x}_i\) can be defined as the probability of misclassification when it is subject to a pool of different learning algorithms, that is:
where \(p\big (y_i | \textbf{x}_i, h_j(\mathcal D)\big )\) is the probability the j-th ML model in the pool attributes \(\textbf{x}_i\) to its expected class \(y_i\). The intuition is that if a pool of diverse classifiers is unable to predict the expected class of \(\textbf{x}_i\) with a high probability (proxy to a high confidence), then this instance is intrinsically hard to classify.
In turn, hardness meta-features (HM) can be used for prospecting possible reasons why an instance is hard to classify or not [9, 10]. Summarizing, given an instance \(\textbf{x}_i\):
-
kDN (k-Disagreeing Neighbors) gives the percentage of k nearest neighbors of \(\textbf{x}_i\) with label different from \(y_i\);
-
N1I (fraction of nearby instances of different classes) gives the fraction of instances that do not belong to class \(y_i\) which are connected to \(\textbf{x}_i\) in a Minimum Spanning Tree built from \(\mathcal D\);
-
N2I (ratio of the intra-class and extra-class distances) takes the ratio of the distance \(\textbf{x}_i\) has to the nearest neighbor from its class \(y_i\) to the distance \(\textbf{x}_i\) has to its nearest enemy (nearest instance from another class \(y_j \ne y_i\));
-
LSCI (Local Set Cardinality) measures the size of the set containing instances from class \(y_i\) which are closest to \(\textbf{x}_i\) than to its nearest enemy (this set is named local set of the instance);
-
LSR (Local Set Radius) gives the radius of the previous set;
-
U (Usefulness) considers the number of local sets an instance belongs to;
-
H (Harmfulness) takes the number of instances \(\textbf{x}_i\) is nearest enemy of;
-
CL (Class Likelihood) measures the likelihood an instance belongs to its class \(y_i\);
-
CLD (Class Likelihood Difference) measures the difference between the likelihood an instance belongs to the class \(y_i\) to the likelihood it belongs to any other class \(y_j \ne y_i\);
-
F1I (Fraction of features in overlapping areas) gives the percentage of input features lying in overlapping regions of the classes;
-
DCP (Disjunct Class Percentage) gives the percentage of examples of class \(y_i\) which are placed in a same disjunct as \(\textbf{x}_i\), where disjuncts are defined by a decision tree algorithm;
-
TD (Tree Depth) gives the depth where the instance is classified in a decision tree model, which can be either pruned (\(TD_P\)) or unpruned (\(TD_U\)).
All measures are standardized, by definition, in the [0, 1] interval, so that larger values are attributed to instances hard to classify according to the measured criterion.
3.2 Hardness Embedding
The hardness embedding is built from a composition of several sets. All individual instances \(\textbf{x}_i \in \mathcal D\) compose the Instance Set \(\mathcal I\). The Algorithm Set \(\mathcal A\) comprises a portfolio of classification algorithms of distinct biases. The Performance Set \(\mathcal P\) records the predictive performance obtained by each algorithm in \(\mathcal A\) for every instance \(\textbf{x}_i\). The Feature Set \(\mathcal F\) contains the HM extracted from the instances \(\textbf{x}_i\). Therefore, for each instance \(\textbf{x}_i\in \mathcal I\) and for each algorithm \(\alpha _j \in \mathcal A\), a feature vector \(\textbf{f}(\textbf{x}_i) \in \mathcal F\), and an algorithm performance metric \(p_m(\alpha _j, \textbf{x}_i)\) are measured. The process is repeated for all the instances in \(\mathcal I\) and algorithms in \(\mathcal A\), generating a meta-dataset \(\mathcal M = \{\mathcal I,\mathcal F,\mathcal A,\mathcal P\}\).
The algorithms included in the pool \(\mathcal A\) are: Bagging, Gradient Boosting (GB), Support Vector Machine (SVM, with both linear and RBF kernels), Multilayer Perceptron (MLP), Logistic Regression (LR) and Random Forest (RF). They present distinct learning mechanisms and are commonly adopted to solve ML classification tasks in the literature, specially when tabular datasets are concerned. To assess the performance of the algorithms, a five-fold CV strategy is used. Their performance \(\mathcal P\) is evaluated using the log-loss error per instance.
The meta-dataset \(\mathcal M\) is next subject to a meta-feature selection step so that only the most informative meta-features are preserved. This selection is performed using a Neighborhood Component Feature Selection (NCFS) algorithm [21], where we seek to find meta-features more related to the predictive performance of the classifiers in \(\mathcal A\).
The resulting meta-dataset is then projected into a 2-D embedding presenting linear trends in the meta-features and algorithmic performance measures, also named Instance Space (IS), as described in [8, 11]. The result is a projection matrix able to map each instance to the 2-D hardness embedding based on the selected meta-features values. A further rotation step is also included, so that the hard instances are placed in the upper left quadrant and the easier instances are in the lower right quadrant of the hardness embedding.
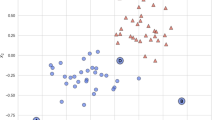
Figure 2 presents examples of hardness embeddings of three datasets for predicting the outcome of COVID patient severity. The first and third datasets contain the symptoms and comorbidities of citizens undergoing diagnosis tests. In the second example, patients of an hospital from the São Paulo metropolitan area (Brazil) are prognosed based on a set of routine laboratory tests. In all cases, classes are represented by different shapes. The colors give the instance hardness level of the instances as computed by Eq. 1. The higher the IH value, the redder the color; the lower the IH value, the bluer the color. There is a mix of patients that are easy or hard to classify per class, with both triangles and circles in the upper left or lower right regions of the plot.

Hardness embedding of three datasets with contrasting profiles: (a) Severity; (b) Hospital 1; (c) Hospitalization.
Whilst this plot can be colored according to all meta-features \(\mathcal F\) values, performance measures \(\mathcal P\) values of the classification algorithms \(\mathcal A\) and even by the original input features values of the dataset \(\mathcal D\), selections of specific regions can also be saved and scrutinized.
3.3 Instance Easiness and Instance Hardness Footprints
A footprint is defined in [22, 23] as a region in the instance space where an algorithm is expected to perform well based on inference from empirical performance analysis. Here we use such a concept in order to define regions from the hardness embedding which concentrate more easy or hard instances. They are named easiness and hardness footprints, respectively.
In order to construct these footprints, first the instances must be categorized as either easy or hard. This can be done by imposing different thresholds on IH values. In fact, we consider three categories: easy, hard and others. The later category encompasses instances that have intermediate hardness levels. We focus our analysis on contrasting easy and hard instances. Ultimately, the objective is to understand why some instances are hard to classify. For segmenting the instances, we consider a threshold T, which must be higher than 0 and lower than 0.5. Since the IH values are bounded in the [0, 1] interval, we have:
-
\(\textbf{x}_i\) is considered easy if \(IH_{\mathcal A}(\textbf{x}_i, y_i) \le T\);
-
\(\textbf{x}_i\) is considered hard if \(IH_{\mathcal A}(\textbf{x}_i, y_i) \ge 1-T\).
Then for each set of instances, easy or hard, the DBSCAN algorithm [24] is used to identify high density clusters in the instance (hardness) space. \(\alpha \)-shapes are used to construct hulls which enclose all the points within the clusters [25]. For each cluster hull, a Delaunay triangulation creates a partition, and those triangles that do not satisfy a minimum purity (defined as the percentage of easy or hard instances enclosed within it, which is 0.7 by default) requirement are removed. The union of the remaining triangles gives the corresponding easiness or hardness footprint. As in [22], it is also possible to extract the following objective measures from the footprints:
-
1.
The area of the footprint in the 2-D hardness embedding, normalized by the total area of the space;
-
2.
The density of the footprint, computed as the ratio between the number of instances enclosed by the footprint and its area;
-
3.
The purity of the footprint, which corresponds to the percentage of instances enclosed by the footprint from a given category, that is, the percentage of hard instances in the case of the hardness footprint and of easy instances in the easiness footprint.
Taking the hardness footprint as reference, a large area implies the dataset has many instances hard to classify, so that they occupy a large portion of the hardness embedding. A large density means such area is dense. And a large purity is observed when most of the instances enclosed in the hardness footprint are indeed hard. Conversely, it is possible to define similar concepts for the easiness footprint and the easy instances. The easiness and hardness footprints’ areas can be regarded as an indicative of the hardness profile of the dataset. When the hardness area is large, the dataset and the underlying classification problem can be considered more difficult to solve. In contrast, easy datasets/problems will show a large easiness area.
4 Experiments
Four datasets from the health domain, involving the prognosis of individuals diagnosed for COVID-19 in Brazil, were used in our experiments. Datasets and their description are available in a public repositoryFootnote 1. Summarizing, we have:
-
1.
Hospital 1 and Hospital 2: prognosis of COVID-19 severity for patients hospitalized at two distinct private hospitals from the São Paulo metropolitan area, using some standard laboratory tests;
-
2.
Hospitalization and Severity: prediction of the hospitalization length when a citizen from São José dos Campos-SP is hospitalized with a positive COVID diagnosis (Hospitalization) and if he/she will evolve to a severe condition (Severity), based on initial symptoms and comorbidities reported.
4.1 Footprint Analysis
First, we analyze the easiness and hardness footprints of three datasets with distinct hardness profiles. They are Severity, Hospital 1, and Hospitalization datasets with easy, intermediate, and hard profiles, respectively. Following the same order, the average accuracy rate achieved by the seven classifiers for each of these datasets was: 0.900 (std 0.003), 0.673 (std 0.030), and 0.398 (std 0.022).

Easy and hard footprints of datasets with contrasting profiles: (a) Severity, (b) Hospital 1; (c) Hospitalization. T value = 0.048.
To determine such footprints, we did an experimental procedure varying the T value from 0.3 to 0.495, with steps of 0.02. Next, we monitored the purity values of the resulting footprints. We chose the T values leading to the highest purity values for both easiness and hardness footprints. Purest footprints are preferred, as they ensure most of the instances the footprint encloses are indeed easy/hard. Figure 3 shows the obtained footprints: hardness in red and easiness in blue. As expected, the hardness footprint dimensions increase according to the dataset’s difficulty level. For instance, when the T value reaches 0.45, all instances are considered hard in the Hospitalization dataset.

Areas, purities and densities of the hardness footprints for increasing T values.
Figure 4 presents the variations of the area, density and purity values of the hardness footprint for increasing T values in the datasets. As expected, when T increases, the footprints’ areas grow, as more instances obey the inequalities involving the instance hardness values. But this increase is less accentuated for the datasets with easy and intermediate hardness profiles. Purity is always over 0.7 and varies less for the Severity dataset, while presenting an increasing tendency in the other problems. In contrast, whilst density values are stable in the Hospitalization dataset, where the instances are concentrated in the center of the IS, a tendency of decrease is observed for the other datasets (larger areas with less instances are encompassed in the footprints). Similar plots can be generated for the easiness footprints.
From the footprints we can already obtain insights by contrasting hard and easy instances. In Fig. 5 we present boxplots contrasting the percentage of Lymphocytes, one input feature of dataset Hospital 1 for instances in the hardness (left boxplots) and easiness (right boxplots) footprints. Colors matches the original class, where red stands for patients that developed to a severe condition and blue is the opposite class. Clearly, there is an inversion on the expected features’ values when we compare the plots. In fact, a reduction in the proportion of lymphocytes is expected for severe cases and not the opposite [20]. This is already an indicative that hard instances are not following the expected pattern from the class they belong to. Figure 5b presents boxplots of the kDN meta-feature values for the hardness (left) and easiness (right) footprints. Easy instances have a low kDN value (are surrounded by elements sharing their class label), while hard instances have a high kDN value (are close to elements from the opposite class), despite the class they belong to. Therefore, hard instances are contrasting their ground truth labels and are contained in overlapping areas.

Plots of the input features Lymphocytes (%) and of meta-feature kDN for the hard instances (left) and easy instances (right) from dataset Hospital 1.
4.2 Data Sculpting

Average model performance scored by AUC in a data sculpting process. The dotted line is the performance without removing any instance from Hospital 1.
Now we move our analysis to a practical usage of our framework in a data sculpting strategy. The idea is to remove the instances of the hardness footprint, assuming they are probably noisy and incorrect. The results of this procedure are illustrated in Fig. 6. Increasing thresholds of T are considered, which means that we start removing instances with the highest hardness levels. The average AUC performance of the seven classifiers from the pool \(\mathcal A\) is shown in the y-axis, with standard deviations in gray. The performance achieved with no sculpting (keeping all instances) is shown as a dotted line.
In Fig. 6a, we train and test the classifier over the same dataset (Hospital 1). As expected, removing the hard instances increases the accuracy achieved. In Fig. 6b, the sculpting takes place at instances from dataset Hospital 1, used for training, but test takes place at a different dataset, Hospital 2. This second analysis already entails a higher difficulty level, since it presupposes the profiles of patients from Hospital 1 are predictive of the conditions of the patients from Hospital 2. In this case, there is only a subtle increase of accuracy over the original baseline (the dotted line), for T around 0.30 and 0.34. But the results are detrimental for other T values. That is, in this case the benefit occurs only when a small fraction of the hardest training instances are removed. The standard deviation values are also usually high, indicating a large variation of results.
As in [6] when randomly removing ambiguous instances, removing hard instances in a dataset always increases model performance for the same dataset (Fig. 6a). However, inside health scenarios the removal of hard instances can be dangerous since they are not necessarily noisy or incorrect. Instead they can represent sub populations with atypical yet correct features’ values. So the models might become incapable to correctly classify these types of instances. This might explain why when sculpting data from Hospital 1 and testing the results in data from Hospital 2 the accuracy decreases after a threshold around 0.34. Therefore, a more informed data sculpting process is needed.
4.3 Analyzing Groups of Data with a Domain Expert
Here we inspect closely groups of hard instances in a dataset and show that more guided insights can be devised. This is possible taking advantage of the different possibilities of visual inspection of the hardness embedding, which can have the instances colored according to all features, meta-features and algorithmic performance values.
In spite of the easy profile of the Severity dataset (Fig. 2a), there are still instances with a high level of difficulty placed in the upper left corner of the hardness embedding. Most of the patients with a severe condition are placed in the bottom of the space, indicating this class is fairly easy to classify (group 1). In the top left of the space there are non-severe patients very hard to classify (group 2) and also some severe cases hard to classify in the top of the hardness embedding (group 3). Patients without a severe condition are mostly placed in the center of the space (group 4), being also easy to classify.
Patients composing group 2 present at least one of three attributes heavily correlated with a severe condition. As a consequence, they have a low likelihood of belonging to their registered class (high CL values). To understand why these patients did not require an extended hospitalization or did not evolve to death, we inspected the raw databases, obtaining some valuable insights. From the 90 instances, 17 were mislabeled due to data preprocessing failures and should be corrected. The remaining were hospitalized but released before ten days of hospitalization. Between then, nine patients were under 35 years old, which can explain the quick recovery. For others, the short hospitalization could be explained either because of disease recovery despite the apparent severity of the case, or by an external factor, like reduced hospital capacity for receiving such patients. The complete analysis of the other groups can be found in our repository.
In the Hospital 1 dataset, the nature of the attributes is different, since the blood tests have distinct reference values according to sex and age and can also change in the presence of other diseases and medication. These are some reasons why the predictive models perform poorly in this dataset. The IS also offers insights which help to understand why, how, and where the ML models are failing. Comparing meta-feature values for the severe individuals hard to classify reveals six types of hard instances. One of these groups is composed of eight instances labeled as non-severe, although they have the opposite profile. Indeed, they have a low likelihood of belonging to their registered class (CL) and are surrounded by elements from a different class (N1). Each individual in this group is a man between fifty and sixty years old, with low percentage of lymphocytes and C-reactive protein count as well as high percentages of neutrophils. Investigating the original database it is possible to follow up the values of these same blood tests in the next few days. This inspection reveals that, besides their initial condition, all of them recovered before 14 days of hospitalization (the proxy for considering a severe patient in this dataset). Therefore, this group is composed of outlier patients with a faster recovery than would be initially expected.
Another group is composed of 30 patients that also present a clinical condition similar to the severe class, but are labeled as non-severe patients. All meta-features are high for these patients (CL, DCP and N1), revealing they are difficult to classify according to different perspectives. Analyzing the original database, we found an unexpected pattern. Some of these patients are released without recovering (still presenting low percentage of lymphocytes and C-reactive protein counts) and sometimes in a worse condition. We could not recover the real reason for hospital discharge. These patients might have been transferred between hospitals, although being registered as medical releases in the system. These are more suitable candidates for data sculpting, since they might be noisy, as justified by the high values for their meta-features. These analysis illustrate how our framework can support the insertion of expert knowledge to improve data quality and model performance, in a more guided data sculpting process.
5 Discussions and Conclusions
Data-centric analysis have been taking an important role in ML, providing means to assure more trustfulness to the area. In this paper, we obtain interpretations on reasons why some observations of a dataset can be considered hard to classify. This is done considering both original input features and also meta-features which describe possible abstract structural reasons explaining why some instances are hard to classify. The choice of the instances to be examined is based on a projection of the dataset into a hardness embedding showing linear trends of classification difficulty according to different perspectives. We show the value of our proposal in gaining insights about data from the health domain.
Our framework was devised to the analysis of datasets in a tabular format, which are very abundant in the health domain. But plenty of non-structured data, such as image and text, are also gathered in this domain (eg. X-ray images). This does not prevent applying our framework to non-structured data. For instance, it is possible to extract structured representations from non-structured data by imputing them to some deep learning trained models [26].
For obtaining the hardness embedding, many meta-features and algorithmic performance measures must be extracted from the dataset first. This clearly implies in a computational cost which cannot be disregarded. Running the analysis on a MacBook Pro OS computer (M1 processor with 8 GB of memory), the average time taken to obtain the hardness embeddings for our datasets was around four minutes. In general, the hardness meta-features have at most a quadratic asymptotic cost on the number of observations the dataset has, mostly because some of them require building a distance matrix between all pairs of observations of the dataset. But the main cost is usually incurred by the cross-validation training-testing of the classifiers in the pool \(\mathcal A\). Computational cost can be saved by reducing the amount of classifiers considered, although we can argue that the classifiers chosen here are common representatives everyone tests when tabular data are concerned, at least as baselines.
Another limitation of our current approach is that data must be labeled in advance. We shall investigate strategies to allow attributing a expected hardness level to unlabeled test instances. Also, applying the analysis to imbalanced datasets must be done with care, since the minority class observations will tend to be pointed as hard just because they are outnumbered. And missing values must also be dealt with in advance. Both issues can be solved in the future by including data re-sampling and missing value imputation strategies inside the framework.
Other types of analysis can also be devised and investigated. For instance, we can test the effects of including or excluding features from a dataset. As more informative features are present, we expect the easiness footprint to grow and the hardness footprint to shrink. Other analysis possible is to establish when a prediction should better be discarded and be entrusted to a specialist instead and to devise a human-in-the-loop procedure.
References
Anderson, D., Bjarnadottir, M.V., Nenova, Z.: Machine learning in healthcare: operational and financial impact. In: Babich, V., Birge, J.R., Hilary, G. (eds.) Innovative Technology at the Interface of Finance and Operations, vol. 11, pp. 153–174. Springer, Cham (2022). https://doi.org/10.1007/978-3-030-75729-8_5
Imrie, F., Cebere, B., McKinney, E.F., van der Schaar M.: AutoPrognosis 2.0: democratizing diagnostic and prognostic modeling in healthcare with automated machine learning. arXiv preprint arXiv:2210.12090 (2022)
de Moraes, B.A.F., Miraglia, J., Donato, T., Filho, A.: Covid-19 diagnosis prediction in emergency care patients: a machine learning approach. MedRxiv, 2020-04 (2020)
Fernandes, F.T., de Oliveira, T.A., Teixeira, C.E., de Moraes Batista, A.F., Dalla Costa, G., Chiavegatto Filho, A.D.P.: A multipurpose machine learning approach to predict covid-19 negative prognosis in São Paulo, Brazil. Sci. Rep. 11(1), 1–7 (2021)
Wynants, L., et al.: Prediction models for diagnosis and prognosis of covid-19: systematic review and critical appraisal. BMJ 369 (2020). https://doi.org/10.1136/bmj.m1328
Seedat, N., Crabbe J., van der Schaar, M.: Data-SUITE: data-centric identification of in-distribution incongruous examples. arXiv preprint arXiv:2202.08836 (2022)
Seedat, N., Crabbe J., Bica, I., van der Schaar, M.: Data-IQ: characterizing subgroups with heterogeneous outcomes in tabular data. arXiv preprint arXiv:2210.13043 (2022)
Paiva, P.Y.A., Moreno, C.C., Smith-Miles, K., Valeriano, M.G., Lorena, A.C.: Relating instance hardness to classification performance in a dataset: a visual approach. Mach. Learn., 1–39 (2022)
Smith, M.R., Martinez, T., Giraud-Carrier, C.: An instance level analysis of data complexity. Mach. Learn. 95(2), 225–256 (2014)
Arruda, J.L.M., Prudêncio, R.B.C., Lorena, A.C.: Measuring instance hardness using data complexity measures. In: Cerri, R., Prati, R.C. (eds.) BRACIS 2020. LNCS (LNAI), vol. 12320, pp. 483–497. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-61380-8_33
Paiva, P.Y.A., Smith-Miles, K., Valeriano, M.G., Lorena, A.C.: PyHard: a novel tool for generating hardness embeddings to support data-centric analysis. arXiv preprint arXiv:2109.14430 (2021)
Valeriano, M.G., et al.: Let the data speak: analysing data from multiple health centers of the São Paulo metropolitan area for covid-19 clinical deterioration prediction. In: 2022 22nd IEEE International Symposium on Cluster, Cloud and Internet Computing (CCGrid), pp. 948–951. IEEE (2022)
Zheng, K., Chen, G., Herschel, M., Ngiam, K.Y., Ooi, B.C., Gao, J.: PACE: learning effective task decomposition for human-in-the-loop healthcare delivery. In: Proceedings of the 2021 International Conference on Management of Data, pp. 2156–2168 (2021)
Houston, A., Cosma, G., Turner, P., Bennett, A.: Predicting surgical outcomes for chronic exertional compartment syndrome using a machine learning framework with embedded trust by interrogation strategies. Sci. Rep. 11(1), 1–15 (2021)
Prudêncio, R.B., Silva Filho, T.M.: Explaining learning performance with local performance regions and maximally relevant meta-rules. In: Xavier-Junior, J.C., Rios, R.A. (eds.) Brazilian Conference on Intelligent Systems, pp. 550–564. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-21686-2_38
Gunning, D., Stefik, M., Choi, J., Miller, T., Stumpf, S., Yang, G.-Z.: XAI-explainable artificial intelligence. Sci. Rob. 4(37), eaay7120 (2019)
Ojala, M., Garriga, G.C.: Permutation tests for studying classifier performance. J. Mach. Learn. Res. 11(6) (2010)
Ghorbani, A., Zou, J.: Data Shapley: equitable valuation of data for machine learning. In: International Conference on Machine Learning, pp. 2242–2251. PMLR (2019)
Lorena, A.C., Garcia, L.P., Lehmann, J., Souto, M.C., Ho, T.K.: How complex is your classification problem? A survey on measuring classification complexity. ACM Comput. Surv. 52(5), 1–34 (2019)
Jafarzadeh, A., Jafarzadeh, S., Nozari, P., Mokhtari, P., Nemati, M.: Lymphopenia an important immunological abnormality in patients with covid-19: possible mechanisms. Scand. J. Immunol. 93(2), e12967 (2021)
Amankwaa-Kyeremeh, B., Greet, C., Zanin, M., Skinner, W., Asamoah, R.K.: Selecting key predictor parameters for regression analysis using modified Neighbourhood Component Analysis (NCA) algorithm. In: Proceedings of 6th UMaT Biennial International Mining and Mineral Conference, pp. 320–325 (2020)
Smith-Miles, K., Tan, T.T.: Measuring algorithm footprints in instance space. In: 2012 IEEE Congress on Evolutionary Computation, pp. 1–8. IEEE (2012)
Muñoz, M.A., Villanova, L., Baatar, D., Smith-Miles, K.: Instance spaces for machine learning classification. Mach. Learn. 107(1), 109–147 (2018)
Khan, K., Rehman, S.U., Aziz, K., Fong, S., Sarasvady, S.: DBSCAN: past, present and future. In: The Fifth International Conference on the Applications of Digital Information and Web Technologies, pp. 232–238. IEEE (2014)
Edelsbrunner, H.: Alpha shapes-a survey. Tessellations Sci. 27, 1–25 (2010)
Najafabadi, M.M., Villanustre, F., Khoshgoftaar, T.M., Seliya, N., Wald, R., Muharemagic, E.: Deep learning applications and challenges in big data analytics. J. Big Data 2(1), 1–21 (2015)
Acknowledgements
This study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - Brasil (CAPES) - Finance Code 001. The authors also thank the financial support of FAPESP (grant 2021/06870-3) and CNPq.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Valeriano, M.G., Paiva, P.Y.A., Kiffer, C.R.V., Lorena, A.C. (2023). A Framework for Characterizing What Makes an Instance Hard to Classify. In: Naldi, M.C., Bianchi, R.A.C. (eds) Intelligent Systems. BRACIS 2023. Lecture Notes in Computer Science(), vol 14196. Springer, Cham. https://doi.org/10.1007/978-3-031-45389-2_24
Download citation
DOI: https://doi.org/10.1007/978-3-031-45389-2_24
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-45388-5
Online ISBN: 978-3-031-45389-2
eBook Packages: Computer ScienceComputer Science (R0)