
Abstract
Autonomous robots for agricultural tasks have been researched to great extent in the past years as they could result in a great improvement of field efficiency. Navigating an open crop field still is a great challenge; RTK-GNSS is a excellent tool to track the robot’s position, but it needs precise mapping and planning while also being expensive and signal dependent. As such, onboard systems that can sense the field directly to guide the robot are a good alternative. Those systems detect the rows with adequate image techniques and estimate the position by applying algorithms to the obtained mask, such as the Hough transform or linear regression. In this paper, a direct approach is presented by training a neural network model to obtain the position of crop lines directly from an RGB image. While, usually, the camera in such systems are looking down to the field, a camera near the ground is proposed to take advantage of tunnels formed between rows. A simulation environment for evaluating both the model’s performance and camera placement was developed and made available in Github, and two datasets to train the models are proposed. The results are shown across different resolutions and stages of plant growth, indicating the system’s capabilities and limitations.
This study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - Brasil (CAPES) - Finance Code 001; The National Council for Scientific and Technological Development - CNPq under project number 314121/2021-8; and Fundação de Apoio a Pesquisa do Rio de Janeiro (FAPERJ) - APQ1 Program - E-26/010.001551/2019.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others

1 Introduction
The use of robotics in agriculture presents the possibility of improving the efficiency of the field, and at the same time increasing the production and quality of the crop. Autonomous robots are a good tool to deal with simple but long lasting tasks, such as monitoring the state of plants growth [1, 2], health and presence of plagues or invasive species [3, 4].
Real-time kinematics with Global Navigation Satellite System (RTK-GNSS) can provide, in open fields, an accurate position of the robot which can be used to navigate [4, 5]. While precise, this system does not describe the crop field itself, thus requiring precise mapping and route planning. RTK-GNSS can also be expensive to deploy [5, 6] in scale and be vulnerable to an unreliable or weak signal [1].
Crops are not always straight and plain, varying widely in topology due to the place’s geography, which makes navigation even harder [5], see Fig. 1. As such, onboard solutions for navigation gained traction and different techniques and sensors have been tested and developed. Onboard systems, such as LIDAR [4, 7], depth cameras and RGB cameras [6, 8], make the robot sense the field directly, allowing it to navigate between plantation rows accordingly.
In order to correctly navigate the field, an algorithm to detect the rows and spaces inbetween must be used. Convolutional Neural Networks (CNNs) have already been successful at distinguishing crops from lanes [9, 10]. In a similar way, this work employs a CNN, which is trained in images extracted from simulations and previous tests of the robot.
Given a segmented image, techniques such as Linear regression [5, 11], can be applied to extract steering commands to guide the robot. This work aims to extract directly from the image, using a CNN, the steering directions, leveraging the model’s capacity of feature extraction to guide the robot more directly.
The previously developed robot is a differential drive design, developed to work across soybean and cotton fields, Fig. 2. The original hardware has three Logitech C270 cameras for navigation, one up top looking down and one in each front wheel, two Intel RealSense D435i RGB-D cameras used for plant analysis and two GPS modules, all controlled by an Intel NUC7i5BNK running Ubuntu 18.04 LTS and ROS Melodic.

Uneven and curved field.

The robot roaming in a test field
For this work, simulations and robot control are performed by the Nvidia Jetson AGX Orin Developer Kit. This new single board computer (SBC) is replacing the robot’s onboard computer, improving the available computational power, now running Ubuntu 20.04 LTS with ROS Noetic.
2 Related Work
Deep learning methods for crop field navigation have already been researched and tested. Ponnambalam et al. [5] propose a ResNet50 to generate a mask of the field using an RGB camera. This work addresses the changing aspects of the field across the season, such as shadows, changes of colours, bare patches or grass across the field by a multi-ROI approach with the generated mask.
Xaud, Leite and From [10], applied a FLIR thermal camera to navigate within sugarcane fields. The thermal camera yielded images with more visibility and better discernible features, especially in poor lighting and weather conditions. The authors tested a simple CNN model with both cameras to compare the performance of the RGB image against the thermal camera with good results in favor of the latter.
Silva et al. [9] compared the same training dataset with and without the depth information of a RGB-D camera applying the U-net deep learning model to identify the rows of plantation. RGB only images end up being selected due to RGB-D not increasing the results seemingly. The obtained masks were post processed by a triangular scanning algorithm to retrieve the line used for control.
Similarly to Ponnambalam [5], Martins et al. [11] applied a multi-ROI approach with sliding windows on a mask generated by the excess of green method. This is also the current robot’s method of row navigation and one possible direct comparison which shows good results with smaller plant size scenarios, but limitations are observed in testing.
This work attempts to bridge the last gap in all previous examples by obtaining directly the row line or the row path, that way commands are sent straight to the controller and not derived from a mask by a post process algorithm. The mask, in this instance, will be leveraged as an auxiliary task [12] to improve the training model and allow the use of further techniques on the mask itself.
One of the biggest challenges faced previously were situations where the soil was occluded by leaves. With a bottom camera close to the ground, a similar navigation system will be tested to face this challenge using the developed tools.
3 Approach
The controller, which actuates the robot wheels, receives two parameters, an X value that describes the vertical offset of a given line and \(\theta \), the angle between the line and the vertical, see Fig. 3. For each frame captured by the robot’s RGB-camera, the aim is to obtain a given line and pass both X and \(\theta \) values to the controller. During the testing phase, the effects of using a segmentation job as an auxiliary task will also be evaluated.
A second approach will also test a bottom camera near the ground which creates a “tunnel” and “walls” effect by the camera’s positioning amongst the rows, see Fig. 3.

Top and bottom camera line values given to the controller
3.1 Data Annotation and Preprocessing
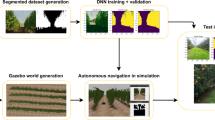
The image data previously obtained was separated in groups by weather condition and plant growth. These are RGB images with 640\(\,\times \,\)480 resolution and 8bpc of color depth. One first Python script was made to annotate line coordinates for each image with openCV and another script built a mask for segmentation using the line and various color filters. After the process, this base mask was loaded into JS-Segment Annotator Tool [13] for cleaning and small corrections, see Fig. 4.

Masks are generated by algorithm and then cleaned to improve quality
The line was defined with two variable X values and two fixed Y values, the line will always be defined by coordinates in the form of \(\left( X_0, 0\right) \) and \(\left( X_1,480\right) \), even if X falls outside of the image size. This special case is caused by lines that start or finish in the sides of the image.
The Top View Dataset was separated in three sections: training, validation and testing, with an split of \(70\%\), \(20\%\) and \(10\%\), respectively. Each section contains \(50\%\) of images derived from the simulation and also samples of every type from the original image groups.
The Botton View Dataset was only composed by simulated data due to lack of good images for training among the original data.
3.2 Network Model
A modified Network Model based on the DeepLabV3+ [14] was extracted from Keras code examples. The DeepLabV3+ employs an encoder-decoder structure and this variation has ResNet50 [15] as backbone for early feature extraction by the encoder. The ResNet50 was obtained in the Keras Applications Library pretrained with Imagenet weights.
A second head, known here as Line Head, was added alongside DeepLabV3+ responsible for learning the line directly. Its composition is made of a flatten layer, two fully interconnected layers with 25 and 20 neurons each and a output layer. The input is taken from the same tensor that DeepLab uses for the Atrous convolution section of its encoder, see Fig. 5. The interconnected layers apply ReLU as activation function while the output layer uses a sigmoid.

Multitask proposed model for mask and line generation
A custom loss function (1) was established due the multitask nature of the model, it combine the mask’s Sparse Categorical Cross-entropy and the Root Mean Squared Error (RMSE) used for the two values, \(X_0\) and \(X_1\), needed to define the line.
Training is performed in up to 500 epochs with early stopping configured. The Adam optimizer was chosen with a learning rate of \(10^{-5}\) and training stopped if bad values (NAN) were detected. The best and the final weights are kept to predict the test images and be used in the simulation.
Two variants of the model were tested, the full proposed model and without the DeepLabV3+ decoder alongside the Line Head, evaluating the impact of the auxiliary task. Each variant was tested with 3 image resolutions: \(128\,\times \,128\) for faster inference times, \(512\,\times \,512\) for better image quality and detail, and \(256\,\times \,256\) as a middle ground. All listed configurations were tested for the top and the bottom cameras.
4 Simulation and Test Setup
A simulation for testing was elaborated using the Gazebo-Sim package from ROS, and made avaliable at https://github.com/ifcosta/cnn_line. Plant models were designed in the Blender software based on real image data and a simplified version of the robot was modeled with two cameras, one at a height of 1,8 m looking downward in front of the robot and one just 0,15 m above the ground looking in front slightly upward. Images obtained with the simulations can be automatically annotated using simulation tools and filters (Fig. 6).

Simplified robot model built for the simulations
The simulated field is built with five stages of plant growth, each stage has six plant rows that are 50 cm apart and 10 m long, with the plants 25 cm apart. There are multiple models of plants for each stage, each plant in a given row is selected randomly in the stage of growth pool. There is also a random component to the plant placement; 15% of given positions have a missing plant and every plant in the row has a small variance in position, see Fig. 7.

Field modelled for testing with five growth stages
Each model was tested by crossing the field in both directions across all growth stages and the error between the theoretical perfect line and also the mean absolute error of the robot position were both recorded. The robot also starts every run with a small deviation from the center, randomly pointing inward or outward, and has a small error component for the applied velocity as defined by
with \(\theta =0.25\), \(\mu =0\) and \(\sigma =0.01\).
The tests were designed this way so the model has to be able to compensate for actuation errors while correcting the starting deviation correctly during the run.
5 Results
5.1 Training Phase
Concerning the models trained for the bottom camera, both line-only and the variant with an auxiliary task achieved similar results with regards to the line’s combined loss function, see Fig. 8. The larger resolution with auxiliary task is the worst performing model by the final loss value and had its training stopped due to NAN values found. Both smallest resolution models were the most unstable, while the best model, in general, was the medium resolution one. Also, the auxiliary tasks had little to no discernible impact except for the high resolution which had a negative one.

Bottom camera line loss - dotted line mark the minimum value obtained
Meanwhile, the top camera, in Fig. 9, has better training results than the bottom one. This camera position also exhibits a small but positive effect to all resolutions when using an auxiliary task. The lower resolution had the worst performance, like with the bottom camera, but the high and medium resolution had comparable training performance with this camera placement. The top camera was considerably better during the training phase for all resolutions in regards to the model’s loss.

Top camera line loss - dotted line mark the minimum value obtained
The bottom camera data set is smaller and composed only by simulation derived images, which could be impacting its results. The way that the line was modeled implied that it had a higher variability at the top of the screen with the bottom camera, i.e. \(X_0\), and that could lead to the higher loss observed. This volatility does not happen with the top camera and to the \(X_1\) value of the bottom one. As it will be shown later, the bottom camera model can still work with this behavior, but a different training approach for the bottom line might bring better results.
5.2 Simulation Runs
Alongside the model’s tests, a control run was executed with ROS transforms to calculate the theoretical perfect line and evaluate the controller performance. These runs have a perfect line, but still have a processing delay comparable to the model’s inference times.
For the top camera, there is another available comparison, which is the multi-ROI with excess of green mask [11]. This algorithm is not designed to be used on the bottom camera and its processing time depends of the number of masked pixels inside the sliding window. As such, the larger growth stage, having a greater amount of segmented and processed pixels due to the size of and density of the plants, takes longer to process. It also depends on the CPU’s single thread processing power, being less suitable for the Jetson’s hardware, see Fig. 10, so this algorithm can be slower depending in plant size and shape while the CNN based algorithms does not get influenced by it.
The growth stage 1 and 2, which has the smaller plants, had similar results shown by Fig. 11 growth stage 1. Also the growth stage 3 and 4 with the medium sized plants, Fig. 12, displayed similar traits. Evaluating the robot’s position inside the plantation row can assess the entire performance of the system, i.e. model and controller. Figures 11 and 12 show that only the low resolution without auxiliary task model got consistently bad results while the high resolution with auxiliary task got them only in the growth stage 1 for the top camera.

Processing time for all algorithms, from image reception to command sent. The multi-ROI is split for each growth stage to show the speed decrease observed with bigger plants

Robot position deviation from the center of row’s path - Growing Stage 1

Robot position deviation from the center of row’s path - Growing Stage 3
Figures 12 and 13 also display the weaker result of the Multi-ROI approach from growth stage 3 onward, possibly due to the high processing time needed and the lack of soil visibility. The fifth growth stage marks failures for all top camera models, while the bottom still has good results, in line with the previous scenarios, see Fig. 13.

Robot position deviation from the center of row’s path - Growing Stage 5
As such we can conclude that the bottom camera is better suited to this dense environment, with the medium and high resolution displaying the best results.
6 Discussion
The proposed approaches displayed good results in the simulation, in special the medium resolution, which was the most consistent. Meanwhile, the auxiliary task showed potential, improving results for the small and medium resolution, but with problems at the highest.
Overall, with those datasets and this simulated environment, the medium resolution with auxiliary task had the best performance, followed closely by the medium and high resolutions without the auxiliary task.
The camera near the ground delivered comparable results to the top camera in most scenarios and excellent ones when the ground was occluded by the plant leaves. The tunnel formed was enough to guide the robot during the simulations, but tests with objects and grass on the robot’s path need to be evaluated. Also, tests in a real environment would improve the dataset and test the model’s true capabilities.
It is important to note that the controllers used in this work were not modified from those already in place in the robot. However, with the developed simulation environment other techniques could be applied to better actuate the robot with the given line from the network. Jesus et al. [16] proposed a method leveraging reinforcement learning to navigate an indoor area, reaching goals without hitting obstacles. The same kind of controller could be used in our work, with the line being used as input to the controller agent.
7 Conclusion
We presented a neural network model to extract crop lines from RGB images. The network input can be taken from either a top or a bottom camera, and the loss function was augmented with an auxiliary segmentation task.
With the simulated environment created, the top and the bottom cameras were evaluated in three image resolutions with and without the auxiliary task proposed. All networks configurations trained successfully and were able to guide the robot in the simulation with varying degrees of success while using the data set created with the built environment.
When assessing the overall performance of the entire system, both the top and bottom cameras achieved less than 50 mm of deviation from the center of the path in all but one configuration in the first four growth stages. However, the fifth growth stage resulted in failures for all top configurations, with errors exceeding 90 mm for most configurations, while the bottom camera remained below 50 mm. The processing time of all configurations kept below 70 ms, notably the medium resolution which kept between 30 and 40 ms, comparable to the low resolution model.
The auxiliary task had a positive impact on medium and low resolutions but negatively impacted the high resolution configuration. The bottom camera approach is beneficial to scenarios were the ground is mostly occluded by dense foliage, but can have issues in some configurations containing smaller plants.
With the GPU computing performance available, a fully integrated model could be feasible. This way, the best camera for each situation would not need to be chosen, as both cameras could feed directly into the model, combining channel wise or just as a larger image. Other types of cameras, such as thermal or RGB-D, can be evaluated to take advantage of ground’s temperature as it is occluded by bigger plants or the depth perception possible due to the tunnel seen by the bottom camera. Other types of network models could also be evaluated, both for the line head and for the auxiliary task used.
References
Ahmadi, A., Nardi, L., Chebrolu, N., Stachniss, C.: Visual servoing-based navigation for monitoring row-crop fields. In: 2020 IEEE International Conference on Robotics and Automation (ICRA) (2020)
Nakarmi, A.D., Tang, L.: Within-row spacing sensing of maize plants using 3d computer vision. Biosys. Eng. 125, 54–64 (2014)
McCool, C.S., et al.: Efficacy of mechanical weeding tools: a study into alternative weed management strategies enabled by robotics. IEEE Robot. Automat. Lett. 1 (2018)
Barbosa, G.B.P.: Robust vision-based autonomous crop row navigation for wheeled mobile robots in sloped and rough terrains. Dissertação de mestrado em engenharia elétrica, Pontifícia Universidade Católica do Rio de Janeiro, Rio de Janeiro (2022)
Ponnambalam, V.R., Bakken, M., Moore, R.J.D., Gjevestad, J.G.O., From, P.J.: Autonomous crop row guidance using adaptive multi-ROI in strawberry fields. Sensors 20(18), 5249 (2020)
Ahmadi, A., Halstead, M., McCool, C.: Towards autonomous visual navigation in arable fields (2021)
Shalal, N., Low, T., McCarthy, C., Hancock, N.: Orchard mapping and mobile robot localisation using on-board camera and laser scanner data fusion - part a: tree detection. Comput. Electron. Agric. 119, 254–266 (2015)
English, A., Ross, P., Ball, D., Upcroft, B., Corke, P.: Learning crop models for vision-based guidance of agricultural robots. In: 2015 International Conference on Intelligent Robots and Systems (IROS) (2015)
De Silva, R., Cielniak, G., Wang, G., Gao, J.: Deep learning-based crop row following for infield navigation of agri-robots (2022)
Xaud, M.F.S., Leite, A.C., From, P.J.: Thermal image based navigation system for skid-steering mobile robots in sugarcane crops. In: 2019 International Conference on Robotics and Automation (ICRA). IEEE (2019)
Martins, F.F., et al.: Sistema de navegação autônoma para o robô agrícola soybot. In: Procedings do XV Simpósio Brasileiro de Automação Inteligente. SBA Sociedade Brasileira de Automática (2021)
Liebel, L., Körner, M.: Auxiliary tasks in multi-task learning (2018)
Tangseng, P., Wu, Z., Yamaguchi, K.: Looking at outfit to parse clothing (2017)
Chen, L.-C., Zhu, Y., Papandreou, G., Schroof, F., Adam, H.: Encoder-decoder with atrous separable convolution for semantic image segmentation (2018)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 382–386 (2016)
Jesus, J.C., Bottega, J.A., Cuadros, M.A., Gamarra, D.F.: Deep deterministic policy gradient for navigation of mobile robots in simulated environments. In: 2019 19th International Conference on Advanced Robotics (ICAR), pp. 362–367 (2019)
Author information
Authors and Affiliations
Corresponding authors
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
da Costa, I.F., Caarls, W. (2023). Crop Row Line Detection with Auxiliary Segmentation Task. In: Naldi, M.C., Bianchi, R.A.C. (eds) Intelligent Systems. BRACIS 2023. Lecture Notes in Computer Science(), vol 14197. Springer, Cham. https://doi.org/10.1007/978-3-031-45392-2_11
Download citation
DOI: https://doi.org/10.1007/978-3-031-45392-2_11
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-45391-5
Online ISBN: 978-3-031-45392-2
eBook Packages: Computer ScienceComputer Science (R0)