
Abstract
Advances in sign language processing have not adequately kept pace with the tremendous progress that has been made in oral language processing. This fact serves as motivation for conducting research on the potential utilization of deep learning models within the domain of sign language processing. In this paper, we present a method that utilizes deep learning to build a latent and generalizable representation space for signs, leveraging Formal SignWriting notation and the concept of sentence-based representation to effectively address sign language tasks, such as sign classification. Extensive experiments demonstrate the potential of this method, achieving an average accuracy of \(81\%\) on a subset of 70 signs with only 889 training data and \(69\%\) on a subset of 338 signs with 3, 871 training data.
The authors of this work would like to thank the Center for Artificial Intelligence (C4AI-USP) and the support from the São Paulo Research Foundation (FAPESP grant #2019/07665-4) and from the IBM Corporation. This study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - Brasil (CAPES) - Finance Code 001.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others


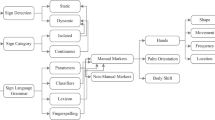
1 Introduction
The World Health Organization has projected that approximately 700 million individuals will experience moderate-to-severe hearing loss by 2050, with a majority being elderly due to aging population [38]. Hearing loss brings challenges to the daily lives of individuals. The challenge is even more difficult for deaf babies born into families that are not familiar with sign language, as it is essential for them to gain literacy in sign language to facilitate appropriate cognitive and socioemotional development, as well as equitable and effective communication [38]. Besides acquiring sign language, access to diverse forms of knowledge throughout their lives is essential for their intellectual and civic development.
Deaf individuals are inevitably placed in social environments where oral language predominates. Although they can still use a gesture-visual language to communicate, acquiring information, whether routine or formal, is primarily accomplished through the use of the oral language writing system. This system is based on the transcription of the phonological aspects of oral language. Due to this discrepancy, the acquisition of written proficiency in the local spoken language by deaf individuals is not only complex, but it also does not promote linguistic reflection in their first language. Furthermore, this discrepancy prevents the complete dissemination of knowledge to this segment of the population.
The availability of automatic translation tools between sign languages and oral languages could facilitate the social inclusion of the deaf community and enhance their access to knowledge. However, despite recent advances in natural language processing, tasks related to the automatic processing of sign languages still remain a challenging problem. One of the major obstacles in this task is the scarcity of labeled datasets [26]. Although sign language videos are currently available in significant volume, labeling them is a laborious task and requires refined linguistic knowledge [25]. Furthermore, the most modern resources for automatic resolution of tasks related to linguistic systems are based on the principle of a word sequence-based language. This aspect prevents the use of modern techniques of language processing on sign language due its organization based in gestural elements superimposed in a three-dimensional space.
One alternative to overcome this gap is to use a writing system for sign languages, such as the well-known SignWriting. Developed by Valerie Sutton [33], SignWriting is a universal notation for recording sign languages that uses the International SignWriting Alphabet 2010 to represent the parameters of sign languages. As a result, it provides a basis for writing gesture-visual signs. Using a writing system for sign language opens up an avenue for using the Transformer architecture [23, 35] - a neural network architecture widely used for language modeling and solving various natural (oral) language tasks.
In this paper we present a framework developed for using lexicons of sign language, described through SignWriting, as input for deep learning architectures. We trained deep learning models using public datasets that contain sign descriptions in SignWriting, and tested the resulting model on the classification task of signs from three sign languages: American, Brazilian, and German.
We contend that our work makes significant contributions to the field of automatic sign language processing. We propose a new conceptual model for sign language processing. This model creates a latent representation space for signs, and supports the development of solutions for tasks such as translation. The representation space is applied in classifier implemented with Convolutional Neural Network and Transformer architectures. We have made pre-trained model checkpoints publicly availableFootnote 1 to the research community, which can accelerate the development of solutions for various sign language processing tasks. Additionally, as part of the conceptual model development process, we devised three mappings for adequate SignWriting descriptions for using in deep learning architectures.
This paper is organized as follows: Sect. 2 provides a theoretical background; Sect. 3 presents an overview of the related work; Sect. 4 discusses the dataset design and the method proposal; Sect. 5 presents the experimental results along with a discussions about them; Sect. 6 presents the final remarks.
2 Background
2.1 Sign Language
Natural languages have structure based on small, meaningless building blocks (smallest units called phonemes) and bigger meaningful building blocks (morphemes and lexemes that make up words). Despite an unlimited number of meanings that a natural language can create, the limitation of the number of minimum units makes a descriptive study of languages possible [19].
Sign languages are natural languages assumed to be primary for deaf individuals. This languages employ signs composed of hand configurations and movements combined with facial expressions and body postures to communicate meaning, as opposed to the spoken word used in oral languages [31]. For instance, the signs for “little house”, “house” and “big house” in Brazilian Sign Language are built using a specific hand configuration carried out in different locations and applying different facial expressions (cf. Fig. 1).

Examples of signs for “little house”, “house” and “big house” in Brazilian Sign Language [1].
Notwithstanding common misconceptions, sign languages are not word-for-word translations of spoken languages. For instance, the relative sentence in the oral language Portuguese “A garota que caiu de bicicleta? ... Ela está no hospital!!”Footnote 2 is uttered in Brazilian Sign Language by using appropriate signs in the following sequence: <MENINA CAIU BICICLETA> ... <ELA LÁ HOSPITAL>Footnote 3.
While there is a consensus among scholars regarding the notion of a finite number of minimal units generating an infinite number of meanings, there is no academic agreement on the standardized approach to describe and organize signs. This issue arises from the various SignWriting-based annotation practices applied worldwide [5].
2.2 Writing Systems for Sign Language and the SignWriting
The written recording of languages in a permanent and standardized form is essential for reflecting on communication content, recording memories, and thinking language itself, enabling the advancement and improvement of thought and cognitive processes. The absence of records makes it challenging to organize social and cultural activities within a society, leading to distortions and incomplete information about memories and traditions [8]. Thereby, sign writing systems were proposed over the years.
The oldest writing system was developed by Auguste Bébian in 1825. Such a system, known as “mimographie”, has 190 symbols that describe five constituent parameters of a sign [4]. In 1965, Stokoe published a more concise writing system specific to the American Sing Language consisting of 50 symbols [31]. Based on Stokoe’s notation, François Xavier Neve proposed, in 1996, a system that uses characters from Western writing as a way of representing the minimum units of sign languages [24]. The Hamburg Sign Language Notation System (HamNoSys), created in 2004, is also based on Stokoe’s system, but with more iconic symbols to facilitate its use with computational techniques [16]. Finally, Writing in Sign Language (ELiS) was created by the Mariângela Estelita Barros in 2008, bringing the concept of finger configurations [3].
The writing system of interest in this paper is SignWriting, developed by Valerie Sutton [33], mainly because it has the widest availability of collaborative databases, with adherence to deaf communities around the world, among all notations [30]. This is a universal notation for sign languages that represents the parameters of sign languages through a set of visual symbols hierarchically classified. It comprises seven categories, with 30 groups of symbols, and 652 icons called “visographemes”. Each icon has varying degrees of freedom to describe a sign. They can be rotated on their central axis, mirrored, and contextualized with other parts of the sign, generating 35.023 unique symbols. The categories of symbols used in SignWriting are:
-
1.
hand shape: symbols to represent possibilities of finger articulation;
-
2.
movements: symbols used to represent contact and small finger movements;
-
3.
dynamics/timing: symbols use to describe intensity or movement cadence;
-
4.
head & face: symbols used to represent head position, head/neck/facial parts movements, and facial expressions;
-
5.
body: symbols used to represent torso/shoulders/limbs/hips movements;
-
6.
location: contains 8 symbols to represent where, in the 3D-space, the sign is performedFootnote 4;
-
7.
punctuation: symbol used when writing complete sentences.
Figure 2 depicts some examples of how to write the sign “rain” and “strong rain” in SignWriting, considering the composition of the sign in American Sign Language. Notice that the same sign can be written in multiple ways, and there exists the possibility of representing varying levels of intensity.

Examples of how to write “rain” and “strong rain” in SignWriting, considering the composition of the sign in American Sign Language [33].
Formal SignWriting. To facilitate the collection and dissemination of SignWriting content, Valerie Sutton developed the SignBank databaseFootnote 5, which serves as a collaborative platform for users worldwide. The database encourages users to contribute by adding new vocabulary entries and content written in SignWriting. Among the available contents, there are dictionaries that link signs written in SignWriting with their corresponding meanings utilizing words or expressions from the oral language of the respective country. Within this database, all inputs are encoded using Formal SignWriting, a standard symbol representation system. Formal SignWriting employs ASCII characters within a regular expression format, incorporating special tokens and \(x,y-\)coordinates to describe and position symbols within a designated area known as the SignBox. Tokens are organized in four groups: structural makers, the base symbol ranges, modifier indexes, and the numbers. The method for sign language processing introduced in this paper requires the use of Formal SignWriting for symbol representation. Below, we present the regular expressionFootnote 6 employed in such formalism:
The symbols have a unique identification, consisting of six characters, with the first character always being the letter S. The next three characters represent the base of a symbol; the fourth character identifies the filling of this symbol, which represents the plane in 3-dimensional space parallel to the palm of the hand, and the last character represents the rotation of the symbol. Each symbol has x, y coordinates within the SingBox. Optionally, the regular expression can be used to describe a sequence of symbols, meaning that signs have modifications to their structure during their execution. This notation uses the letter “A” in place of the letter “S” in the symbol key definition.
2.3 Deep Learning Basics
Convolutional Neural Network Architecture: According to [15], the term convolutional neural network signifies the network’s utilization of the convolution operation, which proves particularly advantageous for processing data with grid-like structures like time series and images. The appeal of this neural network architecture stems from its capacity to extract meaningful features while disregarding the exact feature locations and focusing instead on their relative positions in relation to other features. The network comprises consecutive layers of convolution and pooling, culminating in a dense feedforward neural network. Each convolution layer consists of multiple feature maps generated by sets of synapses sharing the same weights. Maps are constructed through convolution followed by flattening carried out by sigmoid or ReLU functions [15, 17]. Pooling layers follow each convolutional layer, reducing the feature map resolution through statistical operations. The final dense neural network is responsible for learning the mapping of features extracted by the preceding layers to a predefined set of classes corresponding to the input data labels.
Transformer Architecture: In the field of natural language processing, the Transformer [35] architecture has emerged as a prominent model renowned for its performance in text processing tasks. Transformer utilizes a neural network with an encoder-decoder [23] architecture. Considering the translation task, the network receives as input a sentence comprising words from the source natural language, encodes this information using attention layers, and subsequently decodes the encoded information, yielding a sentence translated into the target natural language. In this architecture, the so-called attention layers were introduced, which are responsible for identifying the importance of words as processing occurs. To accomplish this objective, every word is abstracted into vectors within the attention layer, and undergo processing through matrices of synaptic weights. Consequently, an internal parameterizable dimension encoding is obtained. Subsequently, a weighted normalization process is carried out using a softmax activation function. The weighting mechanism determines the significance of each encoding position.
3 Related Work
Previous attempts at automatic sign language processing for recognition, synthesis, translation, and application development relied on classification models using machine learning or hybrid approaches (using language parsers and rule-based reasoning) [2, 9, 12, 14, 26]. These efforts were restricted to specific languages and problems due to limitation of techniques and methods, and lack of labeled data [26]. Recent advances in natural language processing have addressed these challenges, enabling end-to-end solutions and efficient representation learning, mainly using writing systems for sign language, mitigating the scarcity of labeled data and promoting transfer learning. This section lists recent work that uses deep learning architectures in the context of sign language processing.
The initial endeavors aimed to enhance the automated processing of sign language by utilizing SignWriting descriptions primarily focused on German Sign Language signs [13, 21], in 2012 and 2013. This initiative introduced an automated annotation process for sign subunits. Later, in 2015, the same research group employed the RWTH-PHOENIX-Weather dataset to train machine learning models for classification tasks [20].
In 2019, the description of signs was used to optimize BERT-type models, enabling the construction of a representation space [6]. Subsequently, this space was combined with visual information, encompassing hand and body movements, to facilitate classification tasks. This research involved the use of BERT models, convolutional neural networks, and Long Short-Term Memory networks for processing space-time information. In 2020, Camgoz et al. [7] introduced embeddings to represent space-time information in frame sequences, using data from the Montalbano II [11], MSR Daily Activity 3D [36], CAD-60 [32] and NTU-60 datasets [29]. Deep neural networks were employed to extract features, while textual information was provided as inputs in a BERT model. Both representations were used in a Transformer training for sign language recognition. In the same year, Li et al. [22] combined unstructured data (RGB images), BERT-based models, and spatial information from finger joints for solving the problem of classifying signs over the Word-Level American Sign Language dataset.
Several researchers employed efforts to apply deep learning to sign language processing in 2021 [10, 18, 27, 34, 39]. Word-Level American Sign Language dataset was again used in the study of Tunga, Nuthalapati and Wachs [34]. In this case, Convolutional Graph Network (GCN) and BERT model were combined to receive human poses as input and solve the glosses identification task. Deep neural networks were studied for feature extraction by Rastgoo et al. [27]. These authors combined the result of this representation learning with other traditionally used attributes (distances and angles). BERT attention layers were studied by Coster et al. [10] and proved to be effective in allowing the zero-shot classification process in the task of translating sign languages. Pre-trained models of BERT-base and mBART-50 were applied to the task of translating sign language videos to German text. A new model called SignBERT was proposed by Zhou, Tam and Lam [39], using BERT in conjunction with ResNET to extract spatial information and apply it to the translation task. In this study, pose information in skeleton formats and hand configurations as inputs in the BERT strategy. The (SignBERT) was also used by Hu et al. [18] to compose another model, based on hand configurations and the sequence of gesture execution.
The method presented in this paper draws inspiration from related work but offers novel contributions in the following aspects: leveraging information from collaborative sources for training deep learning models, such as utilizing public data from platforms like Wikipedia to generate language models; introducing schema for mapping coding in Formal SignWriting for sentence-like representation, providing a strategy to create a versatile latent representation space applicable to various sign languages.
4 Method
Figure 3 illustrates the method proposed herein. The objective of this method is to establish a latent representation space for signs in a sign language, enabling efficient processing by deep learning models, such as for constructing classifier models. In this scenario, the classifier model takes a sign instance as input and outputs the corresponding concept (or word) represented by that sign.

Proposed method for sign language processing: generation of a representation space and its application for constructing classifier models.
The top section of Fig. 3 (above the dotted line) outlines the process of constructing the representation space. First, a collection of signs recorded in dictionaries is subjected to preprocessing to create a labeled dataset (sign representation \(\rightarrow \) concept). Then, this representation is mapped to sentence-based structures and passed through a customized tokenizer. This tokenizer generates tensors for the sentences, which constitute the latent representation space. The custom tokenizer was trained using the regular expression from Formal SignWriting, which generates a customized vocabulary of tokens. The lower section of the figure illustrates the process of constructing classification models. Instances within the representation space are organized into datasets for both training and testing purposes, which are then utilized to build and evaluate classifier models.
The remainder of this section details the dataset used, the process of mapping the Formal SignWriting representation to a sentence-based representation, and implementation and evaluation strategies.
4.1 Datasets
The SignBank database portal has content related to more than 80 sign languages. For the purpose of our research, three dictionaries of signs were usedFootnote 7: German Sign Language with 24, 777 entries, American Sign Language with 11, 647 entries, and Brazilian Sign Language with 45, 412 entries. The dictionary entries form the vocabulary of signs being processed in our approach.
Each dictionary entry corresponds to a sign description representing a concept. Multiple signs can be associated with the same concept (cf. example shown in Fig. 2) and, not rarely, there are identical entries in the dictionaryFootnote 8. In addition, the dictionaries present some noise referring to data curation failures. During the data preprocessing stage, duplicated descriptions were removed, as well as noises were excluded.
Multiple signs associated with the same concept allowed for the creation of distinct subsets of data for model training and testing. These subsets are mutually exclusive in terms of descriptions and signs but share common concepts. This approach enables the evaluation of the deep learning model’s ability to learn the patterns of concept descriptions. For instance, consider the formal and logographic descriptions illustrated in Fig. 4 for the concept “know”. The training set can consist of descriptions (a) to (e), while descriptions (f) and (g) are allocated to the test set.

Formal descriptions and logographic representations for the concept “know” using SignWriting [33], considering the signs used in American Sign Language.
Table 1 lists the number of minimum entries available in each dictionary when we consider the existence of a specific number of different descriptions for the same concept. Each row in the table represents a situation for training and testing a model. For example, the second row of the table shows the count of concepts represented and the number of entries selected in each dictionary when the condition is to have a minimum of two unique descriptions for each concept. In row number 12, the criterion is set to have at least 12 distinct descriptions. In the last scenario, the American Sign Language dictionary meets this requirement only for 13 concepts and only 197 entries are available for building training and testing datasets. The first line counts the total concepts and entries of each dictionary after the data preprocessing stage.
4.2 Data Mapping
Considering that Transformer-based solutions for natural language processing operate on word sequences (sentences) as input, we present three schema to map Formal SignWriting descriptions to sentence-based representations, involving sequences of meaningful units. We proposed three different mapping schema:
-
Mapping M1: This scheme only represents the sequence of symbols, for instance, for representing a sign “know” in Fig. 4a, the mapping M1 generates the following sequence: S15a11 S20600 S30007.
-
Mapping M2: the sentence provided by this mapping schema embeds an additional set of descriptive information about the sign. Such a set of information comprises:
-
what elements are involved in the sign description: hand, movement, dynamic, head, body or location;
-
indication if there is variation in the hand configuration of the right hand (notation: staticityRTrue) and of left hand (notation: staticityLTrue);
-
indication of the number of hands used during sign signaling (notation: hands_qtt0, hands_qtt1 or hands_qtt2).
The mapping M2 for a sign “know” generates the following sequence: head S300 S30007. hand right S15a S15a11. movement S206 S20600. staticityRTrue. staticityLTrue. hands_qtt1.
-
-
Mapping M3: in this schema, the palm orientation and rotation information are presented separately. In accordance with the Mapping M3 schema to describe the signs, we can represent the corresponding letters in Fig. 4 as follows:
-
(a)
head S300 S3000 S30007. hand right S15a S15a1 S15a11. movement S206 S2060 S20600. staticityRTrue. staticityLTrue. hands_qtt1.
-
(b)
movement S206 S2060 S20600. hand right S182 S1821 S18210. head S300 S3000 S30007. staticityRTrue. staticityLTrue. hands_qtt1.
-
(c)
head S300 S3000 S30007. hand right S182 S1821 S18210. movement S205 S2050 S20500. staticityRTrue. staticityLTrue. hands_qtt1.
-
(d)
movement S206 S2060 S20600. hand right S182 S1821 S18210. head S300 S3000 S30006. staticityRTrue. staticityLTrue. hands_qtt1.
-
(e)
head S321 S3210 S32101. hand left S100 S1001 S10018. hand right S15a S15a1 S15a11. staticityRTrue. staticityLTrue. hands_qtt2.
-
(f)
head S36a S36a0 S36a00. movement S205 S2050 S20500. hand left S182 S1824 S18248. staticityRTrue. staticityLTrue. hands_qtt1.
-
(g)
head S36a S36a0 S36a00. hand left S182 S1821 S18218. movement S206 S2060 S20600. staticityRTrue. staticityLTrue. hands_qtt1.
4.3 Implementation Details
This project implemented the Tokenizer method from DistilBert [28] based-model using the HuggingFace Transformers library [37]. The vocabulary generated from the regular expression used in Formal SignWriting (cf. Sect. 2 and Fig. 3) is concatenated with the words used in the sentences (hand, movement, dynamic, head, body, location, punctuation, stacityRTrue, stacityRFalse, stacityLTrue, stacityLFalse, hands_qtt0, hands_qtt1, hands_qtt2), and with the special tokens [PAD], [UNK], [CLS], [SEP], and [MASK]. The custom vocabulary has 73, 743 tokens.
The Transformer architecture used for contruction of classifier models was also developed using the HuggingFace Transformers library [37]. The implementation of the convolutional neural network architecture was accomplished using libraries and frameworks provided by TensorFlowFootnote 9.
4.4 Classifier Evaluation
The evaluation of the classifier models involved analyzing the impact of the number of concepts (classes) on their performance. This choice of analysis perspective is justified by the dynamic and distributed nature of sign languages. Due to the visual-spatial nature of these languages, signs can undergo numerous variations when used by different user communities. Moreover, the continuous development of new signs reflects the need to incorporate corresponding signs for emerging concepts in societal evolution. Thus, the models were generated using varying numbers of descriptions per concept (from one to eleven). We present the accuracy achieved through stratified cross-validation testing.
5 Experiments and Results
Table 2 presents the optimal outcomes achieved using the convolutional neural network architecture. The table provides the minimum, maximum, and average accuracies (along with their standard deviations) obtained through a comprehensive cross-validation process. Notably, the highest performance was observed in folds with smaller number of descriptions and concepts, indicating that while the experiment yielded promising, there exists an upper limit in terms of the number of concepts these models can effectively recognize. The Libras sign language models exhibited the lowest results, despite having a larger amount of available data. This outcome can be attributed to the experimental strategy employed, which involved a higher number of concepts for this language. Further experiments focusing on a smaller set of concepts are necessary to determine whether additional complexities exist in processing this specific sign language.
The results achieved using the Transformer architecture are presented in Table 3. On average, the results are slightly lower compared to the convolution-based architecture. While better performance in terms of maximum results was attainable for German and American sign languages, the model exhibited instabilities as indicated by the Brazilian sign language results.
Regarding the representation schemes, we observed a slight superiority for the Mapping M3 schema when applying convolutional architecture, and for the Mapping M1 and Mapping M2 schemes when applying the Transformer architecture. These findings underscore the necessity for further investigations to harness the learning capabilities of each architecture, as they appear to encompass distinct features in the representation spaces.
6 Final Remarks
In this paper, we investigate a new sign language modeling approach based on SignWriting descriptions. The obtained classifier models demonstrate the ability to recognize signs based on detailed and unprecedented descriptions of their execution. Our method exhibits adaptability across sign languages from various countries, indicating the potential for utilizing a representation scheme that bridges the gap between SignWriting coding and sentence-based representation in automatic sign language processing research.
As future work, exploration of approaches involving texts and sentences in SignWriting could be conducted, enabling the incorporation of contextual information in sign execution. This would facilitate the development of models for various tasks within the same domain.
It is worth emphasizing that these models still require significant improvement, as their current capacity does not encompass a wide range of concepts. Therefore, conducting a detailed investigation into the errors that arise when introducing a larger set of concepts to the model can provide valuable insights for enhancing the latent representation space.
Notes
- 1.
- 2.
Translation to English: “The girl who fell from bike? ... She is in the hospital!”.
- 3.
Mapping for English words: <GIRL FELL BIKE> ... <SHE THERE HOSPITAL>.
- 4.
Position symbols were not found in the databases used in this paper.
- 5.
- 6.
Detailed information about the regular expression is available at https://datatracker.ietf.org/doc/html/draft-slevinski-signwriting-text-05#section-2.3.
- 7.
Accessed on 2023-01-31.
- 8.
The same sign can be represented in multiple ways, either due to slight variations in the execution of the gesture or by taking contextual factors into account during the signaling process.
- 9.
References
de Almeida Freitas, F.: Reconhecimento automático de expressões faciais gramaticais na língua brasileira de sinais. Master’s thesis, Universidade de São Paulo, Brasil (2015)
de Almeida Freitas, F., Peres, S.M., de Moraes Lima, C.A., Barbosa, F.V.: Grammatical facial expressions recognition with machine learning. In: Proceedings of the 27th International Florida Artificial Intelligence Research Society Conference, pp. 180–185 (2014)
Barros, M.E.: ELis-Escrita das Línguas de Sinais: Proposta teórica e verificação prática. Ph.D. thesis, Tese (Doutorado em Linguística)-Universidade Federal de Santa Catarina (2008)
Bébian, A.: Mimographie, ou essai d’écriture mimique propre á régulariser le langage des sourds-muets. L. Colas (1825)
Bertoldi, N., et al.: On the creation and the annotation of a large-scale Italian-LIS parallel corpus. In: Proceedings of 7th International Conference on Language Resources and Evaluation, Valletta, Malta, pp. 19–22. European Language Resources Association (2010)
Bilge, Y.C., Ikizler-Cinbis, N., Cinbis, R.G.: Zero-shot sign language recognition: can textual data uncover sign languages? arXiv preprint arXiv:1907.10292 (2019)
Camgoz, N.C., Koller, O., Hadfield, S., Bowden, R.: Sign language transformers: joint end-to-end sign language recognition and translation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 10023–10033 (2020)
Capovilla, F., Raphael, W., Viggiano, K., Neves, S., Luz, R.: Sign writing: implicações psicológicas e sociológicas de uma escrita visual direta de sinais, e de seus usos na educação do surdo. Revista Espaço 33–39 (2000)
De Araújo Cardoso, M.E., Peres, S., De Almeida Freitas, F., Venância Barbosa, F., De Moraes Lima, C.A., Hung, P.: Automatic segmentation of grammatical facial expressions in sign language: towards an inclusive communication experience. In: Proceedings of the 53rd Hawaii International Conference on System Science, pp. 1499–1508 (2020)
De Coster, M., et al.: Frozen pretrained transformers for neural sign language translation. In: Proceedings of the 1st International Workshop on Automatic Translation for Signed and Spoken Languages, pp. 88–97. Association for Machine Translation in the Americas (2021)
Escalera, S., et al.: Multi-modal gesture recognition challenge 2013: dataset and results. In: Proceedings of the 15th ACM on International Conference on Multimodal Interaction, pp. 445–452. ACM, New York (2013)
Farooq, U., Rahim, M.S.M., Sabir, N., Hussain, A., Abid, A.: Advances in machine translation for sign language: approaches, limitations, and challenges. Neural Comput. Appl. 33(21), 14357–14399 (2021)
Forster, J., et al.: RWTH-PHOENIX-weather: a large vocabulary sign language recognition and translation corpus. In: International Conference on Language Resources and Evaluation, Istanbul, Turkey, vol. 9, pp. 3785–3789. European Language Resources Association (2012)
Freitas, F.A., Peres, S.M., Lima, C.A., Barbosa, F.V.: Grammatical facial expression recognition in sign language discourse: a study at the syntax level. Inf. Syst. Front. 19, 1243–1259 (2017)
Goodfellow, I., Bengio, Y., Courville, A.: Convolutional networks. In: Deep Learning, vol. 2016, pp. 330–372. MIT Press, Cambridge (2016)
Hanke, T.: Hamnosys-representing sign language data in language resources and language processing contexts. In: 4th International Conference on Language Resources and Evaluation, vol. 4, pp. 1–6 (2004)
Haykin, S.: Neural Networks and Learning Machines, 3rd edn. Pearson, London (2009)
Hu, H., Zhao, W., Zhou, W., Wang, Y., Li, H.: Signbert: pre-training of hand-model-aware representation for sign language recognition. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 11087–11096 (2021)
Karnopp, L.B.: Aquisição fonológica na língua brasileira de sinais: estudo longitudinal de uma criança surda. Ph.D. thesis, Universidade Federal Do Rio Grande do Sul (UFRGS) (1999)
Koller, O., Forster, J., Ney, H.: Continuous sign language recognition: towards large vocabulary statistical recognition systems handling multiple signers. Comput. Vis. Image Underst. 141, 108–125 (2015)
Koller, O., Ney, H., Bowden, R.: May the force be with you: force-aligned signwriting for automatic subunit annotation of corpora. In: 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition, pp. 1–6. IEEE (2013)
Li, D., Opazo, C.R., Yu, X., Li, H.: Word-level deep sign language recognition from video: a new large-scale dataset and methods comparison. In: Proceedings of the IEEE Winter Conference on Applications of Computer Vision, pp. 1459–1469 (2020)
Luong, M.T., Pham, H., Manning, C.D.: Effective approaches to attention-based neural machine translation. In: Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal. ACL (2015)
Nève, F.X.: Essai de grammaire de la langue des signes française, vol. 271. Librairie Droz (1996)
Polat, K., Saraclar, M.: Unsupervised term discovery for continuous sign language. In: Proceedings of the 9th Workshop on the Representation and Processing of Sign Languages: Sign Language Resources in the Service of the Language Community, Technological Challenges and Application Perspectives, Marseille, France, pp. 189–196. European Language Resources Association (2020)
Rastgoo, R., Kiani, K., Escalera, S.: Sign language recognition: a deep survey. Expert Syst. Appl. 164, 113794 (2021)
Rastgoo, R., Kiani, K., Escalera, S., Sabokrou, M.: Multi-modal zero-shot sign language recognition. arXiv preprint arXiv:2109.00796 (2021)
Sanh, V., Debut, L., Chaumond, J., Wolf, T.: Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108 (2019)
Shahroudy, A., Liu, J., Ng, T.T., Wang, G.: NTU RGB+ D: a large scale dataset for 3D human activity analysis. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1010–1019 (2016)
Stiehl, D., Addams, L., Oliveira, L.S., Guimarães, C., Britto, A.: Towards a signwriting recognition system. In: 13th International Conference on Document Analysis and Recognition, pp. 26–30. IEEE (2015)
Stokoe, W.C.: Sign language structure. Annu. Rev. Anthropol. 9(1), 365–390 (1980)
Sung, J., Ponce, C., Selman, B., Saxena, A.: Unstructured human activity detection from RGBD images. In: IEEE International Conference on Robotics and Automation, pp. 842–849. IEEE (2012)
Sutton, V.: Signwriting. Sl: sn, p. 9 (2009)
Tunga, A., Nuthalapati, S.V., Wachs, J.P.: Pose-based sign language recognition using GCN and BERT. In: IEEE Winter Conference on Applications of Computer Vision Workshops, pp. 31–40 (2021)
Vaswani, A., et al.: Attention is all you need. In: Advances in Neural Information Processing Systems, vol. 30 (2017)
Wang, J., Liu, Z., Wu, Y., Yuan, J.: Mining actionlet ensemble for action recognition with depth cameras. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 1290–1297. IEEE (2012)
Wolf, T., et al.: Huggingface’s transformers: state-of-the-art natural language processing. arXiv preprint arXiv:1910.03771 (2019)
World Health Organization: World report on hearing. Technical report, World Health Organization (2021)
Zhou, Z., Tam, V.W., Lam, E.Y.: SignBERT: a BERT-based deep learning framework for continuous sign language recognition. IEEE Access 9, 161669–161682 (2021)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
de Almeida Freitas, F., Peres, S.M., de Paula Albuquerque, O., Fantinato, M. (2023). Leveraging Sign Language Processing with Formal SignWriting and Deep Learning Architectures. In: Naldi, M.C., Bianchi, R.A.C. (eds) Intelligent Systems. BRACIS 2023. Lecture Notes in Computer Science(), vol 14197. Springer, Cham. https://doi.org/10.1007/978-3-031-45392-2_20
Download citation
DOI: https://doi.org/10.1007/978-3-031-45392-2_20
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-45391-5
Online ISBN: 978-3-031-45392-2
eBook Packages: Computer ScienceComputer Science (R0)