
Abstract
In this study, we examine the impact of human mobility on the transmission of COVID-19, a highly contagious disease that has rapidly spread worldwide. To investigate this, we construct a mobility network that captures movement patterns between Brazilian cities and integrate it with time series data of COVID-19 infection records. Our approach considers the interplay between people’s movements and the spread of the virus. We employ two neural networks based on Graph Convolutional Network (GCN), which leverage spatial and temporal data inputs, to predict time series at each city while accounting for the influence of neighboring cities. In comparison, we evaluate LSTM and Prophet models that do not capture time series dependencies. By utilizing RMSE (Root Mean Square Error), we quantify the discrepancy between the actual number of COVID-19 cases and the predicted number of cases by the model among the models. Prophet achieves the best average RMSE of 482.95 with a minimum of 1.49, while LSTM performs the least despite having a low minimum RMSE. The GCRN and GCLSTM models exhibit mean RMSE error values of 3059.5 and 3583.88, respectively, with the lowest standard deviation values for RMSE errors at 500.39 and 452.59. Although the Prophet model demonstrates superior performance, its maximum RMSE value of 52,058.21 is ten times higher than the highest value observed in the Graph Convolutional Networks (GCNs) models. Based on our findings, we conclude that GCNs models yield more stable results compared to the evaluated models.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others


1 Introduction
The COVID-19 is an infectious disease that manifests itself in humans infected by the SARS-CoV-2 virus. The acronym SARS stands for Severe Acute Respiratory Syndrome, which belongs to the family of Coronaviruses who have been infecting humans for a long time. On December 31, 2019, the World Health Organization (WHO) alerted to a new strain (type) of coronavirus. On January 7, 2020, Chinese authorities confirmed the identification of a new type of coronavirus, that was initially named 2019-nCoV, and on February 11, 2020, it was given the name SARS-CoV-2 [15, 28].
Those infected transmit the virus through the mouth or nose, by expelling small particles when they cough, sneeze, talk, sing or breathe. Infection occurs by inhaling these particles through the airways or by touching a contaminated surface and then coming into contact with the eyes, nose or mouth [26]. Due to the nature of the virus, it spreads more easily indoors and in crowds. Those who become ill as a result of COVID-19 experience symptoms ranging from mild and moderate, where the patient recovers without special treatment, to severe, where the patient needs specialized medical care [2].
To this date (May 06, 2023), the virus that causes COVID-19 has infected more than 270 million people and caused more than 5.3 million deaths worldwide [5, 19]. In Brazil, the numbers reach more than 37 million infected and 701 thousand dead [1]. So far, the world has paid a heavy price for this pandemic in lost human lives, economic repercussions and increased poverty. The COVID-19 pandemic is still ongoing, and the virus continues to mutate, generating variants.
This work presents time series forecasting models to predict the number of COVID-19 cases in Brazilian cities [4], covering the period from February 2020 to December 2022. We aim to improve the accuracy of the predictions by incorporating Graph Convolutional Networks (GCN) models, specifically GCRN and GCLSTM. These models leverage a mobility network that captures the commuting patterns between cities, allowing us to account for the interdependencies among cities’ time series and the influence of human mobility on disease transmission [7,8,9, 20].
The performance of our proposed GCN models is compared to two well-known forecasting methods, LSTM and Prophet. Through extensive experiments and evaluation, we obtained compelling results that highlight the effectiveness of the GCN models approach in capturing the complex dynamics of COVID-19 transmission and improving the accuracy of predictions.
This research contributes to the field of COVID-19 forecasting by demonstrating the value of incorporating mobility networks and considering the impact of human movement on disease spread. Our findings provide insights into the interplay between mobility patterns and the spread of COVID-19, and offer valuable implications for developing effective strategies to mitigate the impact of the disease.
2 Related Works
Xi et al. (2022) [27] simulate the propagation curve of COVID-19 in a university, based on the interaction between students through Graph Neural Network (GNN) and a SIR model (Susceptible - Infected - Recovered) [23]. They simulated three distancing strategies designed to keep the infection curve flat and help make the spread of COVID-19 controllable. Students and professors were considered as nodes and places or events as layers (face-to-face lectures, internal social activities, campus cafeterias, etc.). The GNN was used to validate and verify the effectiveness through the simulation of the infection curve, where the infected were randomly chosen. They provide a visualization of the dissemination process of COVID-19 and the comparison between the results of the forecast of dissemination for each of the control strategies.
With the aim of predicting the dynamics of the spread of the pandemic in the USA, the work carried out by Davahli et al. (2021) [6] developed two predictive models using GNN, fed by real data, obtaining results from the forecast of spread and a comparison between the models. The first model developed was based on graph theory neural networks (GTNN) and the second was based on neighborhood neural networks (NGNN). Each US state is considered a graph node, while the edges of the GTNN model document the functional connectivity between states, those of the NGNN model connect neighboring states with each other. The performance of these models was evaluated with existing real dataset that reflect conditions from January 22 to November 26, 2020 (prior to the start of COVID-19 vaccination in the United States). The results indicate that the GTNN model outperforms the NGNN model.
Malki et al. (2020) [17] estimate the spread of COVID-19 infection in several countries, using a supervised machine learning model developed based on a decision tree algorithm and linear regression, for time series forecasting. They show an \(R^2\) of 0.99 in the prediction of confirmed cases at the global level.
Vaishya et al. (2020) [25] deal with the application of artificial intelligence (AI) in combating the COVID-19 pandemic. The authors presented several possibilities for the use of AI in different areas, such as diagnosis, triage, patient monitoring, forecasting disease trends, drug and vaccine development, and even to ensure compliance with social distancing measures. They emphasize the importance of international collaboration to ensure access to the data needed to train AI algorithms and highlight that technology can play a key role in the fight against the pandemic.
The related works presented in this section are all focused on predicting the spread of COVID-19 using different approaches. Xie et al. (2022) used a Graph Neural Network (GNN) and SIR model to simulate the propagation curve of COVID-19 in a university, while Davahli et al. (2021) used GNN to predict the dynamics of the spread of the pandemic in the USA. Malki et al. (2020) used a decision tree algorithm and linear regression for time series forecasting, and Vaishya et al. (2020) discussed the application of AI in combating the pandemic. In contrast, our study focuses on incorporating a mobility network that describes the commuting patterns between Brazilian cities into the forecasting task, leveraging Graph Convolutional Network (GCN) models. The main hypothesis is that this approach could improve the forecasting task by accounting for the dependencies among cities’ time series. Therefore, our work contributes to the literature by emphasizing the importance of incorporating human mobility data into the forecasting task and highlighting the potential of GCN models for this purpose.
3 Methodology
3.1 Mathematical Preliminaries
\(G=(V,E)\) is a graph, in which V is the set of nodes and E the set of edges, resulting in \(N=|V|\) vertices and |E| edges. The binary (or weighted) adjacency matrix \(A \in \mathbb {R}^{N \times N}\) depicts the graph connections; \(D_{ii} = \sum _j A_{ij}\) is the degree matrix, with zeros outside the main diagonal; and \(X \in \mathbb {R}^{N \times C}\) is the feature vector of each vertex, where C is the number of vector dimensions.
3.2 GCN
The Graph Neural Networks (GNN) models allow us to extend the methods of neural networks, in order to process the data represented in the graph domain [21]. GNN models can process most graphs being some of them acyclic, cyclic, directed and undirected, or implement a particular function. The GCN proposed by [18] applies a convolution operation to each vertex of the graph. The approach has three steps: (i) Select a vertex, (ii) build a subgraph of its neighborhood and finally (iii) normalize the selected subgraph with the edge weights of neighboring vertices. Repeat the process for each vertex \(h^{k}\), building the matrix \(H^{k}\) that contains all the vertices in the layer k (refer to Fig. 2 and Eq. (1)).
The subgraph is built using the adjacency matrix A and the diagonal degree matrix of the vertices D. The size of the subgraph is delimited by the parameter K (see Fig. 1). When \(K=1\) the vertex is not subjected to the influence of neighboring vertices. In the case of \(K=2\), first-degree vertices (direct neighbors) are considered, directly connected to the active vertex. For a \(K=3\), second-degree vertices are also considered, connected to first-degree vertices. The subgraph is normalized by the weight matrix.

Nearest neighbors parameter (K) in a Graph. In the purple color, \(K=1\) represents nodes without any neighbors. In the orange color, \(K=2\) represents nodes with first-degree neighbors, and in the red color, \(K=3\) represents nodes with second-degree neighbors. (Color figure online)
When considering the subgraph of a node, we calculate the average feature vector by incorporating information from its neighbors. This process assigns greater importance to the less connected neighbors (lower degree) while also giving higher weight to the node’s connections. Let \(\widehat{A} = A + I_N\), A being the weighted adjacency matrix of the subgraph, \(I_N\) being the identity matrix of order N, and \(\widehat{D}\) is the diagonal degree matrix of \(\widehat{A}\). The output of the convolution layer \(k+1\) is as follows:
where W is the matrix of trainable parameters, and \(\sigma \) is the activation function.
In summary, each vertex in the graph is assigned a feature vector and convolution is applied at each node to compute a new feature vector that considers the neighborhood of the node.
3.3 GCN Models for Time Series Prediction
The Graph Convolutional Recurrent Networks (GCRN) [22] and Graph Convolutional LSTM (GCLSTM) [3] models are architectures based on GCN models that are designed with graph processing and machine learning techniques for the purpose of prediction of data in time series. The convolutions in both architectures differ from a conventional convolution using the relationship between neighbors at each vertex of the graph.
To predict a future sequence, of length F, we use a sequence, of length L (lags), of observed data at previous timestamps:
where \(x_{t}\) is a snapshot at time t of the features and \(\hat{x}_{t}\) is the prediction (see Fig. 2).
Hence, \(x_{t}\) represents a value of the time series at time t for all nodes, defined on a directed, weighted static graph. On the other hand, a snapshot X can be interpreted as a matrix \(X \in \mathbb {R}^{N \times C}\), which captures the temporal evolution of the time series over the interval of C observations.

Spatial and Temporal Snapshot Data Flow and Model Architecture: Processing GCNs with GCLSTM and GCRN Recurrences
The GCRN and GCLSTM models use the same design but with their own convolution blocks: in Fig. 2, the GCRN model uses GConvGRU blocks whereas the GCLSTM model uses GConvLSTM blocks. Both use deep learning techniques, but GCRN uses recurrent networks and GCLSTM uses LSTM cells, in order to capture patterns in time series data considering the influence of its neighbors through the graph.
The graph generated in this work has the spatial structure of the Brazilian mobility network (refer to Sect. 3.5), which has static edges, that is, fixed attributes (see Fig. 2).
3.4 Prophet and LSTM
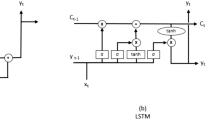
LSTM (Long Short Term Memory) [12] and Prophet [24] are time series forecasting models, and each one has a different approach. In the LSTM model it resembles an RNN (Recurrent Neural Network) composed of 4 memory cells: Input, Forget, Cell, Hidden. These memory cells are responsible for retaining, forgetting or remembering selected information. LSTM is commonly used on data that exhibit complex patterns, sudden changes, trends, or seasonality.
The Prophet model, is based on an additive model that, through regression, models the linear or non-linear trend, in terms of independent variables such as trend, seasonality and holidays, components of the time series. The adjustments of these components are performed using an optimization algorithm such as MCMC [11] (Markov Chain Monte Carlo) or MAP [10] (Maximum A Posteriori) that seeks to find the values of the parameters that maximize the posterior probability of the data, considering the uncertainty of the parameters when making predictions.
3.5 Datasets: COVID-19 Cases and the Brazilian Mobility Network
Cota (2020) [4] provides a public dataset of COVID-19 records in Brazil. Among other data, it contains the numbers of infected and deaths related to municipal and federative units level in Brazil with official information from the Ministry of Health. The dataset is daily updated from official sources, providing reliable information. It also includes information on the cities’ locations, which is useful for our mobility network.
Knowing that the spread of diseases like COVID-19 occurs from infected to susceptible people, one factor that may contribute to the construction of prediction models is to know the flow of people between cities. We thus use the dataset provided by the Brazilian Institute of Geography and Statistics (IBGE) [16] to build a mobility network whose weighted connections represent the number of vehicles from one city to another in an ordinary week. The connection identifies the cities directly accessible from a source, considering (1) the number of outgoing vehicles (frequency), (2) the type of transport (road, waterways, or alternative/informal), (3) travel time, and (4) cost of the traveling. In this study, the weight of each edge was represented solely by attribute 1. This weight was determined by the aggregation of frequencies associated with each mode of transportation (denoted as attribute 2) present on a given edge. It should be noted that attributes 3 and 4 were not incorporated into the calculations in this analysis. The dataset has \(N = 5385\) vertices (cities) and \(L = 65639\) edges (routes between the cities), as shown in Fig. 3. The subfigure on the right side gives the covered territory, in green, and the one on the left side presents the corresponding network.

Brazilian mobility network: a) Nodes representing cities and edges as the routes between them; b) The covered territory, in green. White areas inside the Brazilian map are cities without reported cases in our COVID-19 dataset. (Color figure online)
3.6 Experimental Setup
The COVID-19 dataset has been structured to train models under four distinct scenarios: i) utilizing only the data from 2020; ii) using the 2021 data exclusively; iii) relying solely on the 2022 data; and finally, iv) a comprehensive version incorporating all years. The data undergoes standardization using Z-score normalization (Eq. (3)) to enable consistent and meaningful analysis.
Here, x represents the value of the element, \(\mu \) is the population mean, and \(\sigma \) is the population standard deviation. This normalization process ensures uniformity in the data and facilitates reliable comparisons. In each of the four scenarios, the dataset is partitioned into an 80% subset for training and a 20% subset designated for testing. Each city has 1,009 individual readings of COVID-19 case numbers, with each reading representing a single day’s data.
These readings are grouped into sequences of 14 consecutive days (lags), which are utilized to predict the data for the 15th day. Consequently, each snapshot corresponds to a time series comprised of non-overlapping samples, each size 14. The subsequent day, the 15th, is the target prediction and assumes the first position in the succeeding time series (see Fig. 4). The entire 1009-day period, corresponding to February 2020 to November 2022, results in approximately 57 training snapshots and 15 test snapshots. Lauer et al. [14] provide empirical evidence supporting the recommendation of a 14-day active monitoring period by the US Centers for Disease Control and Prevention. Their study reinforces the importance of this time frame in effectively monitoring and controlling the spread of COVID-19. Regarding the training of the models is parameterized for a total of 100 epochs for the GCRN, GCLSTM, and LSTM models. In these models, an Adam optimizer [13] is used, which adjusts the model’s weights during training, minimizing the Mean Square Error Loss.

Mobility Network Map and Spatial Time Series Data in Brazil: Input Dataset Overview
As Adam is a stochastic gradient descent optimizer, it has an element of randomness, so we perform 10 rounds of experiments for each model. The Adam optimizer was chosen because it uses two moments to update the model weights: the gradient moment and the quadratic gradient moment [13]. At the gradient moment, it adapts the learning rate for each parameter based on how often the parameter is updated. Not all cities update cases daily, so the data does not have a unified update frequency. In the quadratic gradient moment, the weighting of the learning rate is performed by the moving average of the squares of the gradients of each parameter individually, adjusting the model weights.
To present and compare the results of the tests between the neural networks, we use the Root Mean Square Error (RMSE) and the \(R^2\) score (Coefficient of Determination). The RMSE,
is a measure of dispersion that calculates the square root of mean square errors between predictions and actual values, i.e., it indicates how well the model’s predictions fit the data. The lower the RMSE, the better the model performs against the test data.
The \(R^2\) score,
indicates how much the independent variables explain the variation of the dependent variable. It belongs to the interval [0, 1], where 1 indicates that all variations in the dependent variable are explained by the independent variables, and it is 0 when there is no relationship between the variables. Therefore, the closer to 1, the better the model.
4 Results
The Tables 1 and 2 have references to those years, which we will comment on. As we train GCRN, GCLSTM, and LSTM models 10 times each, the results are presented in terms of mean, max, min, and std values of RMSE and \(R^2\).
4.1 GCRN
The results of GCRN (see Table 1) in 2020, the first year of the COVID-19 pandemic, are: \(RMSE = 1495.18\), while in 2021 and 2022, the values decreased significantly to 938.39 and 819.62, respectively. In the last two years, the mean value error became smaller, but the number of cases continued to grow.
The highest min error value was recorded in 2020 and the lowest min error value was recorded in 2021, with values of 1364.51 and 643.26, respectively, while in 2022 the max error value decreased to 1034.46 even with a greater variation than in the previous years. Note that the standard deviation in the years 2020 and 2022 are close, and in the year 2021 it doubles in relation to them. These factors are indicators that in the year 2021 there was a change in the dynamics of spreading the disease.
The highest RMSE for the three years combined suggests potential variations in the dynamics of COVID-19 spread over time, which could be attributed to various factors influencing the transmission patterns. These factors may include governmental interventions, changes in population behavior, the emergence of new variants, variations in testing strategies, healthcare capacity, public adherence to preventive measures, and other external factors that could impact the transmission dynamics of the virus.
Regarding the \(R^2\) score, the models showed low variation in the standard deviation and a minimum value of 0.96 for 2020, which still represents a high prediction capacity of the model.
Figure 5b gives a visualization of the model predictions on the training set, with most points laying on the main diagonal as the high \(R^2\) values suggest. Figure 5a presents a forecasting example, for November 20, with the model trained with all years. We highlight Sao Paulo, Manaus, and Brasilia as being state capitals in different regions of Brazil.

GCRN trained with the dataset of all years (2020 to 2022): a) Result of the predicted and true number of cases in each city on November 29, 2022. The true values of Manaus, Sao Paulo and Brasilia are highlighted with red crosses; b) Linear regression between true and predicted values. (Color figure online)
4.2 GCLSTM
Table 2 introduces the results for the GCLSTM model. As in the GCRN: the average RMSE for 2020 is the highest compared to 2021 and 2022; there is a decreasing trend from 2020 to 2022; and the error for all years is the largest. The \(R^2\) score also decreases over the years and is better than the one obtained for 2020.
The experiment is repeated, but for the GCLSTM model, the results are shown for the \(R^2\) score metric for Table 2 in Fig. 6b and also the results of prediction values compared to actual values for each city (see Fig. 6a).

GCLSTM trained with the dataset of all years (2020 to 2022): a) Result of the predicted and true number of cases in each city on November 29, 2022. The true values of Manaus, Sao Paulo, and Brasilia are highlighted with red crosses; b) Linear regression between true and predicted values. (Color figure online)
4.3 Comparing Forecast Models Results
The lowest RMSE values are highlighted on Table 3, referring to the dataset of all years (from 2020 and 2022). Note that the GCRN and GCLSTM models present similar results concerning mean, max, min, and standard deviation. Interestingly, they achieved lower values of standard deviation, which shows their consistency.
The Prophet model stands out in the average and at the minimum, where it has the lowest values among the models. However, its standard deviation is 3 times greater than the lowest value found in the GCLSTM model and the maximum RMSE is 14 times greater than the maximum observed for GCRN. The model is incredibly good for most data points, but really bad in some cases, showing less stability than GCRN and GCLSTM.
The LSTM model did not obtain any statistics highlighted as the best and can be considered the model with the worst performance, although its minimum RMSE is the second best among all.
The results show that the mobility network indeed helps to forecast COVID-19 cases when embedded in machine learning models. LSTM alone presents the worst RMSE of all models, but when it is integrated with the GCN, via the GCLSTM, the predictions improve. Although Prophet gives the best mean RMSE, it fluctuates more than the graph-based models, showing that sometimes it outperforms them, but is not as stable.
5 Discussions and Conclusions
This studyFootnote 1 investigates the application of GCNs for COVID-19 spread in Brazilian cities. Combining graphs with temporal forecasting models offers advantages. Integrating mobility networks, particularly GCNs with LSTM through GCLSTM, improves prediction accuracy over LSTM alone.
Among the models evaluated, LSTM performed the worst, with Prophet showing the best mean RMSE but higher fluctuations and less stability compared to the graph-based models (GCRN and GCLSTM). The GCN models achieved high \(R^2\) score values above 0.95, representing the data with at least 95% certainty, the models also demonstrated similar results in terms of mean, maximum, minimum, and standard deviation of RMSE. Notably, they achieved lower standard deviation values, indicating higher consistency in their predictions.
In conclusion, the integration of mobility networks through GCNs in machine learning models has proven effective in forecasting COVID-19 cases. The GCN models (GCRN and GCLSTM) showed improved stability and consistency compared to Prophet, while LSTM alone exhibited the worst performance. The models’ performance highlights the importance of considering spatial and temporal data in forecasting tasks, providing valuable insights for epidemiological surveillance and informing strategies to combat COVID-19.
One limitation of our analysis is that it only focuses on one-day predictions. However, it is crucial to extend the prediction window to longer time frames, considering the virus’s incubation and transmission periods, as well as travel time between locations.
The strength of incorporating mobility data lies in our approach using GCNs, which enables us to capture the connectivity between cities and integrate changes in neighboring time series into the local predictions of each city. These changes in neighboring series have a time delay due to the incubation and transmission factors of the virus. By considering these factors and exploring longer prediction windows, we anticipate achieving more significant results in leveraging mobility networks for COVID-19 case prediction.
For future work, we will address the suggestion of conducting more in-depth analyses to assess the impact of including spatial data and applying GCNs for longer-term predictions. Additionally, we will investigate the convergence of the training process and explore ways to enhance the interpretability and explainability of the temporal and spatial data by the GCN models, particularly by examining the stabilization of the loss after 100 epochs, so that we can gain deeper insights into the underlying mechanisms driving the predictions of GCN models and enhance our understanding of the complex interplay between temporal and spatial factors in the spread of COVID-19.
Also, considering that GCN-based models may require more training time (epochs) compared to Prophet, further investigation into the impact of training duration on model performance could be valuable.
Lastly, exploring unexplored graph network regions is a promising research avenue. It can reveal COVID-19 spread insights and uncover hidden data patterns or relationships.
Notes
- 1.
All data and source code are available at the repository link: https://github.com/hodfernando/BRACIS_GCN_2023.
References
Cumulative cases of covid-19 in Brazil (2023). https://covid.saude.gov.br//. Accessed 06 May 2023
Berlin, D.A., Gulick, R.M., Martinez, F.J.: Severe covid-19. N. Engl. J. Med. 383(25), 2451–2460 (2020)
Chen, J., Wang, X., Xu, X.: Gc-lstm: graph convolution embedded lstm for dynamic network link prediction. Appl. Intell. 52(7), 7513–7528 (2022)
Cota, W.: Monitoring the number of covid-19 cases and deaths in brazil at municipal and federative units level. SciELO Preprints (2020)
DASA: Cumulative cases of covid-19 in the world (2023). https://dadoscoronavirus.dasa.com.br/. Accessed 06 May 2023
Davahli, M.R., Fiok, K., Karwowski, W., Aljuaid, A.M., Taiar, R.: Predicting the dynamics of the covid-19 pandemic in the united states using graph theory-based neural networks. Int. J. Environ. Res. Public Health 18(7), 3834 (2021)
Fanelli, D., Piazza, F.: Analysis and forecast of covid-19 spreading in China, Italy and France. Chaos Solitons Fract. 134, 109761 (2020)
Freitas, V.L., Moreira, G.J., Santos, L.B.: Robustness analysis in an inter-cities mobility network: modeling municipal, state and federal initiatives as failures and attacks toward sars-cov-2 containment. PeerJ 8, e10287 (2020)
Freitas, V.L.D.S., Konstantyner, T.C.R.D.O., Mendes, J.F., Sepetauskas, C.S.D.N., Santos, L.B.L.: The correspondence between the structure of the terrestrial mobility network and the spreading of covid-19 in Brazil. Cadernos de Saúde Pública 36, e00184820 (2020)
Gauvain, J.L., Lee, C.H.: Maximum a posteriori estimation for multivariate gaussian mixture observations of markov chains. IEEE Trans. Speech Audio Process. 2(2), 291–298 (1994)
Gilks, W.R., Richardson, S., Spiegelhalter, D.: Markov Chain Monte Carlo in Practice. CRC Press, Boca Raton (1995)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. In: Bengio, Y., LeCun, Y. (eds.) 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015, Conference Track Proceedings (2015)
Lauer, S.A., et al.: The incubation period of coronavirus disease 2019 (covid-19) from publicly reported confirmed cases: estimation and application. Ann. Intern. Med. 172(9), 577–582 (2020)
Li, Q., et al.: Early transmission dynamics in Wuhan, China, of novel coronavirus-infected pneumonia. N. Engl. J. Med. 382(13), 1199–1207 (2020)
Lulia, M.M.E.T., de Oliveira, D.H.: Instituto brasileiro de geografia e estatística-ibge (1936)
Malki, Z., et al.: The covid-19 pandemic: prediction study based on machine learning models. Environ. Sci. Pollut. Res. 28, 40496–40506 (2021)
Niepert, M., Ahmed, M., Kutzkov, K.: Learning convolutional neural networks for graphs. In: International Conference on Machine Learning, pp. 2014–2023. PMLR (2016)
Organization, W.H.: Covid-19 weekly epidemiological update, 119 edn. (2022). Accessed 23 Nov 2022
Rothan, H.A., Byrareddy, S.N.: The epidemiology and pathogenesis of coronavirus disease (covid-19) outbreak. J. Autoimmun. 109, 102433 (2020)
Scarselli, F., Gori, M., Tsoi, A.C., Hagenbuchner, M., Monfardini, G.: The graph neural network model. IEEE Trans. Neural Netw. 20(1), 61–80 (2008)
Seo, Y., Defferrard, M., Vandergheynst, P., Bresson, X.: Structured sequence modeling with graph convolutional recurrent networks. In: Cheng, L., Leung, A.C.S., Ozawa, S. (eds.) ICONIP 2018. LNCS, vol. 11301, pp. 362–373. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-04167-0_33
Smith, D., Moore, L., et al.: The sir model for spread of disease-the differential equation model. Convergence (2004)
Taylor, S.J., Letham, B.: Forecasting at scale. Am. Stat. 72(1), 37–45 (2018)
Vaishya, R., Javaid, M., Khan, I.H., Haleem, A.: Artificial intelligence (ai) applications for covid-19 pandemic. Diab. Metabolic Syndr. Clin. Res. Rev. 14(4), 337–339 (2020)
Velavan, T.P., Meyer, C.G.: The covid-19 epidemic. Trop. Med. Int. Health 25(3), 278–280 (2020)
Xie, H., Li, D., Wang, Y., Kawai, Y.: Visualization method for the spreading curve of covid-19 in universities using gnn. In: 2022 IEEE International Conference on Big Data and Smart Computing (BigComp), pp. 121–128. IEEE (2022)
Zhu, N., et al.: A novel coronavirus from patients with pneumonia in China, 2019. N. Engl. J. Med. 382(8), 727–733 (2020)
Acknowledgements
The authors thank the Brazilian Agencies for Research and Development (CNPq, grants 441016/2020-0, 307151/2022-0, 308400/2022-4), (FAPEMIG, grants APQ-01518-21, APQ-01647-22), (CAPES, grants 88887.506931/2020-00) and Universidade Federal de Ouro Preto (UFOP).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Duarte, F.H.O., Moreira, G.J.P., Luz, E.J.S., Santos, L.B.L., Freitas, V.L.S. (2023). Time Series Forecasting of COVID-19 Cases in Brazil with GNN and Mobility Networks. In: Naldi, M.C., Bianchi, R.A.C. (eds) Intelligent Systems. BRACIS 2023. Lecture Notes in Computer Science(), vol 14197. Springer, Cham. https://doi.org/10.1007/978-3-031-45392-2_24
Download citation
DOI: https://doi.org/10.1007/978-3-031-45392-2_24
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-45391-5
Online ISBN: 978-3-031-45392-2
eBook Packages: Computer ScienceComputer Science (R0)