
Abstract
Public procurement plays a crucial role in government operations by acquiring goods and services through competitive bidding processes. However, the increasing volume of procurement data has made manual analysis impractical and time-consuming. Therefore, text clustering and topic modeling techniques have been widely used to uncover hidden patterns in unstructured text data. This paper leverages the power of BERT-based models to overcome the challenges associated with analyzing public procurement data. Specifically, we employ BERTopic, a topic modeling technique based on BERT, to generate clusters that capture the underlying topics in procurement data. Additionally, we evaluate several sentence embedding models for representing procurement documents. By combining BERT-based models and advanced sentence embeddings, we aim to enhance the accuracy and interpretability of topic modeling in public procurement analysis. Our results provide valuable insights into the underlying topics within the data, aiding decision-making processes and improving the efficiency of procurement operations.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others

1 Introduction
Public procurement is a vital aspect of government and corporate operations, involving acquiring goods and services through competitive bidding processes. With the increasing volume of procurement data, manual analysis becomes an impractical and time-consuming task. Therefore, applying machine learning approaches, such as text clustering and topic modeling algorithms, has become increasingly essential to automate procurement analysis.
Text clustering and topic modeling techniques have proven effective in identifying hidden structures and patterns in unstructured text data [6, 17]. Such methods aim to identify and extract hidden structures and patterns from a large corpus of unstructured text data. Topic modeling, in particular, has been widely used to identify prevalent topics in a corpus of documents. By identifying these topics, analysts can quickly identify common themes and trends in the data, which can inform decision-making processes.
However, traditional topic modeling algorithms such as Latent Dirichlet Allocation (LDA) [1] may not always produce accurate and interpretable results, especially when dealing with noisy and unstructured text data. In the context of public procurement data, characterized by its high technicality and specific jargon, processing and analyzing the data using traditional techniques can be challenging. Therefore, there is a need for advanced methods that can effectively capture and represent the underlying topics in such complex data.
In this paper, we leverage the power of BERT-based models to address the challenges associated with analyzing public procurement data. Specifically, we use BERTopic [10], a topic modeling framework based on BERT pre-trained model [5], to generate clusters that capture the underlying topics in procurement data. Additionally, we evaluate several sentence embedding models to represent procurement documents. Our main contributions are based on the following research questions (RQs):
-
RQ1. What is the comparative performance of different sentence embedding models in representing procurement documents? We conduct an internal evaluation based on topic coherence, topic diversity, and a weighted score (that combines both factors) to compare the performance of four different sentence embedding models and an additional model we trained, called LiBERT-SE. We aim to identify the most effective model for representing procurement documents’ complex and specialized language by addressing this research question.
-
RQ2. How well does BERTopic capture the underlying topics in procurement data? We conduct an external evaluation to compare the BERTopic results with the true document class labels, assessing how well the topics identified in each cluster align with the document labels.
2 Related Work
Like many other government documents, public procurement documents are frequently stored in Portable Document Format (PDF) and consist of unstructured text [17]. The lack of attention to accessibility, usability, and data quality by governmental portals poses challenges in effectively accessing and extracting valuable information from these documents [13]. Consequently, there is a growing need to employ machine learning techniques, specifically text clustering and topic modeling algorithms, to automate the analysis of procurement data.
Text clustering techniques aim to group similar documents together based on their content, enabling the efficient organization and exploration of large document collections [7]. These methods employ various algorithms, such as k-means, hierarchical clustering, and density-based clustering, to identify patterns and similarities in the text data. By grouping related procurement documents, these techniques may facilitate the discovery of common themes, topics, and trends within the data.
On the other hand, topic modeling algorithms provide a means to uncover latent topics or thematic structures within a collection of documents. These algorithms, such as Latent Dirichlet Allocation (LDA), Probabilistic Latent Semantic Analysis (PLSA), and, more recently, BERTopic [10], assign topics to documents based on the distribution of words within the corpus. By extracting meaningful topics, topic modeling enables a deeper understanding of the content and allows for more targeted analysis and decision-making.
Previous research has explored the application of text clustering and topic modeling algorithms to unstructured text data [6, 17]. For instance, Souza Jr. at al. [19] evaluate different pre-processing methodologies in topic modeling for Brazilian Portuguese political discussion extracted from Twitter and Reddit. In particular, the authors applied three document representation models, including two new proposals based on the CluWords model adapted to Portuguese. Also, Silva et al. [16] use topic models for analyzing and visualizing Brazilian comments about legislation. Specifically, the authors adapted the BERTopic topic mining tool to extract topics from political comments.
Furthermore, advancements in deep learning and language modeling have provided new opportunities to enhance the representation of text data [12]. Models like BERT (Bidirectional Encoder Representations from Transformers) [5] and its variants have shown remarkable performance in various NLP tasks, including document classification and named entity recognition. These models can capture intricate semantic relationships between words and provide context-aware embeddings, thereby improving the quality of text representations.
In this paper, we build upon these developments and leverage BERT-based models to address the challenges of analyzing public procurement data. By applying BERTopic, a topic modeling algorithm based on BERT, we aim to generate clusters that capture the underlying topics and themes within procurement documents. While previous studies have focused on topic modeling or document clustering alone, we extend the analysis by considering the performance of different sentence embedding models in capturing the semantics and contextual information of procurement documents.

Overview of the topic modeling methodology.
3 Methodology
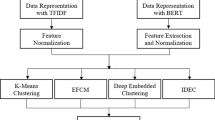
The methodology followed in this work is summarized in Fig. 1 and consists of two main phases: text preprocessing and topic modeling. First, a set of unstructured documents undergoes a sequence of preprocessing steps to transform the text into a more structured format (Sect. 3.1). Then, we apply BERTopic, a topic modeling technique, to create dense clusters and uncover easily interpretable topics in our preprocessed documents (Sect. 3.2).
3.1 Preprocessing
Preprocessing plays a fundamental role in NLP tasks, as it generates a more structured representation of the text and reduces the final set of words (i.e., the vocabulary) that will be used as input for learning models. Indeed, applying a preprocessing step in a learning pipeline directly impacts the models’ accuracy by reducing noise and improving the input quality. Therefore, in this work, we apply a sequence of three distinct preprocessing steps for each document: text normalization, stop word removal, and numeral normalization.
Considering our focus on Brazilian governmental documents, our preprocessing phase is specifically designed to handle texts in the Portuguese language. Hence, in this sequence, text normalization removes special characters, accents, city names, person names, and words with a sequence of repeated letters and lowercasing. City and person names are identified and eliminated based on an exact match against dictionaries containing over 5,000 Brazilian cities and 7,000 common Brazilian names. Next, stop word removal involves removing stop words, emails, URLs, and unit measures. Finally, numeral normalization means identifying and removing hours, numbers, and number symbols from the text.
3.2 Topic Modeling
The second phase of our methodology involves identifying the underlying topics within a set of documents. Such an approach is especially beneficial in documents that do not present clear structural patterns. In this work, we use BERTopic [10], an efficient topic model that leverages clustering techniques and a class-based variation of TF-IDF to create consistent topic representations.
Overall, BERTopic consists of four steps: text representation, dimensionality reduction, document clustering, and topic representation. First, a language model converts each preprocessed document to an embedding representation. Then, we reduce the dimensionality of these embeddings to avoid problems in the clustering process. The last step from these clusters is extracting topic representations, which is our primary goal. All such steps are detailed next.
Text Representation. Mapping sentences into numeric vector spaces is an efficient method to generate richer text representations in NLP tasks [20]. Such representations preserve semantic and syntactic information in sentences, leading to better performance in learning models that rely on the vector representation of the text as input. Here, we use the Sentence-BERT (SBERT) framework [14] to convert sentences and paragraphs into dense vector representations using pre-trained language models. One of the strengths of SBERT is its scalability since it can be executed over large volumes of data, allowing topic analysis in relevant domains that comprises several long documents, such as governmental processes.
Dimensionality Reduction. Reducing the dimensionality of the embeddings is an essential step in preparing the data for clustering. High-dimensional data is difficult for clustering algorithms, as they suffer from the curse of dimensionality. When the data is highly dimensional, the concept of spatial location becomes ill-defined, and distance measures differ little. Therefore, reducing the dimensionality of the embeddings is crucial to make the clustering process more efficient. UMAP (Uniform Manifold Approximation And Projection for Dimension Reduction) [11] is a popular dimensionality reduction method that stands out for preserving more local and global characteristics of high-dimensional data in lower projected dimensions. Using UMAP allows for representing the information more condensed using fewer dimensions, reducing the noise caused by highly correlated variables. As a result, this step increases the efficiency of the clustering algorithm since it will have a better capacity to group documents.
Clustering. After reducing the embeddings (i.e., document representation), the next step is to cluster them semantically. To do so, we use HDBSCAN [3], a density-based clustering algorithm, due to its superior performance compared to other density-based clustering algorithms, such as DBSCAN, in terms of both accuracy and efficiency. HDBSCAN can handle clusters of different shapes and sizes, making it ideal for identifying topics within a set of documents. Moreover, it can identify instances that do not belong to any cluster (i.e., outliers), reducing noise in the final topic representation. As a result, the detected topics are more coherent and representative of the underlying structure of the data.
Topic Representation. After generating the document clusters, we apply a traditional TF-IDF topic detection method variation to each cluster, called c-TF-IDF [10]. Such an adaptation considers that documents in a cluster share similar content and treats all documents in a cluster as a single document. Therefore, one can calculate the terms’ importance and generate the topics’ distribution in each cluster. The more important words are within a cluster, the more it represents that topic. In other words, if one extracts the most important words per cluster, the result is the topics’ descriptions.
4 Experimental Design
This section describes the experimental design to evaluate the effectiveness of BERTopic and sentence embedding models. We first describe LiPSet, the dataset used in our experiments (Sect. 4.1). Then, we present the sentence embedding models used to represent procurement documents (Sect. 4.2). Finally, we detail the evaluation setup and metrics used in this work (Sect. 4.3).
4.1 Dataset
We consider LiPSet [15], a dataset with labeled public bidding documents from the Brazilian state of Minas Gerais, to evaluate the models. These documents are characterized by their technical language and specific jargon, making them an ideal candidate for evaluating the performance of the proposed clustering approach. The LiPSet comprises 9083 labeled documents, classified into four metaclasses: Minutes, Public Notice, Homologation, and Others (includes files belonging to other types of documents, including erratum, annexes, contracts, and descriptive memorials).
In the latest version of LiPSet, the documents were also assigned to classes using a hierarchical approach that consider their metaclasses. In other words, the documents were first labeled to a metaclass and then to one of the classes that belong to this metaclass. For example, minutes can be divided into price registration, waiver, and face-to-face auction. Overall, the four metaclasses are divided into 12 classes. The list of classes for all metaclasses and the number of documents for each one are presented in Table 1.
4.2 Sentence Embedding Models
In addition to evaluating the effectiveness of BERTopic, we also assess the performance of several sentence embedding models for representing procurement documents. Specifically, we consider four models as baselines: Multilingual Universal Sentence Encoder (USE) [21], Language-agnostic BERT Sentence Embedding [8] (LaBSE), S-BERTimbau [14, 18], and Portuguese Legislative Sentence Embedding (LegalBERTPTbr) [16]. Table 2 summarizes these four language models. Additionally, we train a custom model called LiBERT-SE and explore a fine-tuned version using the SimCSE framework [9], described as follows.
LiBERT-SE.Footnote 1 Our model is adjusted in the Masked-Language Modeling (MLM) task for the domain of public procurements, using the BERTimbau [18] model checkpoint. Following the best practices of domain adaptation outlined in [5], we fine-tuned our model using a dataset of 300,000 official gazette segments sourced from various municipalities in Minas Gerais, as previously extracted in [4]. These segments encompass articles published in official gazettes, providing brief information about other documents related to the bidding process. To enhance the model’s vocabulary, we employed a TF-IDF procedure, which allowed us to extract the most significant terms from the gazette segments. Additionally, we manually incorporated domain-specific jargon commonly found in public procurement contexts. To ensure compatibility with the BERTimbau model, we divided the segments into blocks of fixed sizes, ensuring that each block adhered to the maximum sentence length of 512 words supported by BERTimbau. For training, we followed the same hyperparameter settings employed by BERTimbau, except for the batch size, which we reduced to 16 due to computational resource limitations. By adhering to these settings, we aimed to maintain consistency and leverage the existing knowledge and insights gained from the BERTimbau model while tailoring it to the specific domain of public procurements.
LiBERT-SE + SimCSE. In addition to the initial fine-tuning step using the Masked-Language Modeling (MLM) task, we further optimized our model by performing a new fine-tuning step specifically tailored for the task of generating contextualized sentence embeddings. For this purpose, we use the SimCSE framework, which is a self-supervised sentence embedding model designed to learn rich sentence representations through contrastive learning. The SimCSE framework utilizes augmented positive and negative pairs to train the model. Augmented versions of the same sentence are considered positive pairs, and the model is trained to maximize their similarity. On the other hand, augmented versions of different sentences serve as negative pairs, and the model aims to minimize their similarity. By employing this contrastive learning approach, SimCSE effectively learns robust and discriminative sentence representations that capture essential semantic information. To fine-tune our model using the SimCSE framework, we used a dataset consisting of approximately 300,000 segments of official diaries, extracted and published in a previous work [4]. These segments were distinct from those used in the previous fine-tuning procedure for the MLM task.
4.3 Evaluation
Evaluating clustering and topic modeling results can be challenging due to their unsupervised nature. Popular approaches for evaluation involve either “internal” evaluation, where the results are summarized into a single quality score, or “external” evaluation, where the results are compared to an existing “ground truth” [7]. Here, we adopt both internal and external evaluation methods to assess the performance of the proposed approach.
Internal Evaluation. We used two primary metrics to evaluate the performance of models in the internal experiments. First, we use the topic coherence based on normalized pointwise mutual information (NPMI) [2], which ranges from -1 to 1, where a higher value indicates stronger coherence between words in a topic. We also evaluate the topic diversity, which measures the percentage of unique words across all topics [6]. The topic diversity score ranges from 0 to 1, where 0 indicates redundant topics and 1 indicates more varied topics.
Additionally, to make a comprehensive evaluation, we combine the coherence and diversity scores by assigning weights to the normalized coherence (NC) and diversity (ND) based on their relative importance to our specific task. The weighted evaluation score is defined as the sum of the weighted coherence (\(WC_s\)) and weighted diversity (\(WD_s\)), where \(WC_s = 0.8 \times NC\) and \(WD_s = 0.2 \times ND\). By considering both coherence and diversity, we can better assess the overall performance of the topic modeling approach and ensure that the generated topics are not only coherent but also diverse.
External Evaluation. In external evaluation, results are evaluated based on data not used in the topic modeling, such as known class labels. To ensure optimal performance, we fine-tuned the hyperparameters of BERTopic using the language model that achieved the best results in the internal evaluation. During the evaluation, we manually compared the topics generated by BERTopic with the known class labels, which serve as ground truth for the evaluation. This comparison allowed us to gauge the accuracy and relevance of the generated topics in capturing the underlying themes and categories present in the procurement data. By conducting this manual comparison, we aimed to determine the extent to which the generated topics align with the known class labels, thereby providing insights into the effectiveness of BERTopic in capturing and representing the true structure and content of the procurement documents.
Experimental Setup. The internal evaluation metrics were calculated by averaging the results over 10 iterations, where we varied the number of topics from 10 to 50 with a step size of 10. This allowed us to assess the performance of BERTopic across a range of topic numbers and identify the optimal number of topics for our analysis. In the external evaluation, we fine-tuned two specific hyperparameters of BERTopic using the best-performing language model: nr_topics_list, which includes a list of potential numbers of topics,Footnote 2 and min_topic_sizes,Footnote 3 which represents the minimum size threshold for each topic. By fine-tuning these hyperparameters, we aimed to further optimize the performance of BERTopic in generating meaningful and coherent topics. Additionally, for the n_gram_ranges parameter, we set it to (1, 1), indicating that we considered only individual words (unigrams) during the topic modeling process. This choice focused on capturing the most important and distinct keywords within each topic without considering combinations of multiple words. The experiments were performed using 3 GPU models NVIDIA GeForce RTX 3090 Ti, NVIDIA GeForce RTX 4090, and NVIDIA Tesla GRID V100D-32C.
5 Experimental Results
In this section, we present the results of both internal and external evaluations, which aim to address the two research questions defined in Sect. 1. The internal evaluation focuses on assessing the performance and effectiveness of different sentence embedding models in representing procurement documents (Sect. 5.1), while the external evaluation examines the quality of the generated clusters using BERTopic (Sect. 5.2).

Internal evaluation. (A–C) Distribution of internal evaluation metrics, varying across the different models and number of topics. The Kruskal-Wallis test is applied for the models’ mean comparison. (D) Grouped distribution of the weighted score. The Paired Wilcoxon test is applied for grouped distributions’ mean comparison, referring to the number of topics = 10.
5.1 Internal Evaluation
The internal evaluation results are presented in Table 3 and Fig. 2, providing a comparative analysis of the performance of the evaluated models. Table 3 summarizes the evaluation metrics, including topic coherence, diversity, and the weighted score. The results indicate that our trained model, LiBERT-SE, consistently outperforms the other five models across most internal evaluation metrics. Our model performs similarly to the fine-tuned SimCSE version and LaBSE regarding topic diversity, indicating that it can generate diverse and distinct topics. These findings underscore the efficacy of LiBERT-SE in representing procurement documents and capturing the underlying topics accurately.
Figure 2 complements the results’ evaluation, depicting the distribution of topic coherence (A), topic diversity (B), weighted score (C), varying across the different models and number of topics. Furthermore, Fig. 2(D) shows the grouped distribution of the weighted score, providing a concise overview of the performance of each model across the number of topics range. Kruskal-Wallis and Paired Wilcoxon tests were conducted to determine the statistical significance of the observed differences. These tests allow us to verify whether there are significant differences between the models considered, providing additional insights into their relative performance.
Figures 2(A–C) corroborate the findings presented in Table 3, further reinforcing the superior performance of our model (LiBERT-SE) compared to the other models across most evaluated metrics. Our model consistently achieved higher scores in terms of coherence across the different numbers of topics. However, regarding topic diversity, the performance of our model was comparable to the SimCSE and LaBSE models. Therefore, while our model excelled in topic coherence, it also maintained a high level of topic diversity, which is crucial for generating meaningful and varied topics. This indicates that our model balances coherence and diversity, producing coherent topics while avoiding redundancy.
Figure 2(D) provides a comprehensive overview of the models’ performance by showing the grouped distribution of the weighted score across the number of topics range. On average, considering ten topics resulted in a high general performance. However, as the number of topics increased, the performance varied across the models and slightly decreased. This finding suggests that the number of topics can impact the performance of the models. While a lower number of topics tends to yield higher overall performance, increasing the number of topics introduces more granularity but may result in a slight decrease in performance.

Comparative of (A) topic coherence, (B) topic diversity, and (C) the weighted score for each model when considering ten topics. The vertical dashed line represents the median value for each internal evaluation metric. The Paired Wilcoxon test is applied for the models’ mean comparison, referring to the LiBERT-SE model.
To conclude the internal evaluation, Fig. 3 provides further analysis explicitly focusing on (A) topic coherence, (B) topic diversity, and (C) the weighted score for each model when considering ten topics. By examining these metrics individually, we can assess the strengths and weaknesses of each model in capturing the underlying themes and generating diverse topic representations. Consistent with the previous findings, our model outperforms the other five evaluated models, and it consistently achieves higher topic coherence, indicating a more substantial alignment of words within each topic. Additionally, our model exhibits competitive performance regarding topic diversity, suggesting that it can generate varied and distinct topics.
Considering only the weighted score, which combines coherence and diversity, the models that perform well after our model are S-BERTimbau and LabSE. S-BERTimbau’s high performance can be attributed to its design specifically for the Portuguese language. As public procurement data often contain technical terms, S-BERTimbau’s domain-specific embeddings enable it to capture the nuances and intricacies of the text more effectively. LaBSE, on the other hand, is a language-agnostic model that leverages large-scale multilingual training data. Its competitive performance can be explained by its ability to handle various languages, including Portuguese. Finally, our model’s superior performance can be attributed to its ability to leverage pre-training on large-scale datasets and capture the contextual understanding of the text, thereby enhancing the quality of the generated topic clusters.

Performance comparison based on the weighted score across different variations of nr_topics_list and min_topic_sizes hyperparameters.
5.2 External Evaluation
To perform the external evaluation, we fine-tuned two specific hyperparameters of BERTopic using the best-performing language model, i.e., LiBERT-SE. These hyperparameters are nr_topics_list and min_topic_sizes. Figure 4 shows the performance based on the weighted score across different variations of both hyperparameters. To determine the statistically significant combination of nr_topics_list and min_topic_sizes, we applied the Kruskal-Wallis test, allowing us to identify the combination that achieved the best performance: 10 and 60, respectively.
Figure 5 shows the word clouds of the ten topics identified by BERTopic, using the optimal hyperparameters. Each word cloud visually represents the most significant keywords associated with a specific topic. The first topic (-1) represents the outlier documents that do not align with any particular theme or topic. These outlier documents may contain diverse or unrelated content that does not fit into the predefined categories.

Word clouds of the ten topics identified by BERTopic.
The remaining topics capture distinct themes and content within the procurement documents. These topics range from specific domains or subfields within procurement, such as construction projects, supply chain management, legal regulations, or financial aspects. To compare the topics generated with the ground truth (i.e., metaclasses and class labels), we named each topic based on its top words. Table 4 presents the mapping between the topic ID and its given name, along with the top words and their frequency within the topic.

Summary of the topic-metaclass associations.
Using the mapped names in Table 4, we generate a heatmap to analyze each document’s occurrence between topics and metaclass labels (Fig. 6). This heatmap provides a visual representation of the associations between the identified topics and the metaclass labels assigned to the procurement documents. The intensity of the colors in the heatmap reflects the frequency or occurrence of the topic-metaclass pair within the documents. Darker colors indicate a higher frequency, while lighter colors represent a lower frequency or absence of the topic-metaclass pair. Overall, the topic-metaclass associations do not perfectly align in the heatmap. While some topics show strong associations with specific metaclasses, indicating a clear thematic correspondence, others exhibit a more scattered or diverse distribution across different metaclasses.
This misalignment can be attributed to several factors. Firstly, the BERTopic is based on the underlying patterns and co-occurrences of words within the documents, which may not always align precisely with the metaclass labels assigned to the documents. Secondly, the complexity and diversity of the procurement domain can contribute to the variation and dispersion of topics across different metaclasses. Consequently, topics may overlap or span multiple metaclasses, leading to a less direct one-to-one correspondence between topics and metaclasses. Additionally, the quality and representativeness of the training data can influence the topic modeling results. If the training data does not fully cover the diversity of procurement documents or lacks sufficient labeled examples for each metaclass, it may affect the accuracy of the topic-metaclass associations.
6 Conclusion
In this paper, we presented a comprehensive methodology for topic modeling in Brazilian procurement documents using the BERTopic framework. Our approach involved preprocessing steps to enhance the quality of the text and utilized HDBSCAN for clustering the documents. The resulting clusters were then analyzed using c-TF-IDF to extract meaningful topic representations. Through evaluating several sentence embedding models, we found that our trained model, LiBERT-SE, consistently outperformed the other models in terms of topic coherence. However, regarding the efficiency of BERTopic in capturing the underlying topics in the purchase data, there is still room for improvement in aligning the topics with the predefined class labels. This finding highlights the inherent challenge of topic modeling in public procurement data, which is characterized by its complexity and diversity.
Limitations and Future Work. While our methodology provides valuable findings, it is important to acknowledge some limitations: The preprocessing steps and embedding models used in this study were specifically tailored for the Portuguese language. Applying the methodology to other languages may require adaptations and modifications. The focus of this work was on Brazilian governmental documents. The methodology’s effectiveness and the models’ performance may vary when applied to different domains or document types. The evaluation and comparison of sentence embedding models were conducted on a specific dataset and task. As future work, we aim to conduct experiments on diverse datasets across various languages and domains to validate the generalizability and robustness of the methodology, models, and evaluation metrics. Additionally, we plan to broaden our evaluation by testing a wider range of sentence embedding models, incorporating state-of-the-art models.
Notes
- 1.
- 2.
(10, 13, 14, 15, 16, 17, 19, 20, auto).
- 3.
(10, 20, 30, 40, 50, 60, 70, 80, 90, 100).
References
Blei, D.M., Ng, A.Y., Jordan, M.I.: Latent dirichlet allocation. J. Mach. Learn. Res. 3, 993–1022 (2003)
Bouma, G.: Normalized (pointwise) mutual information in collocation extraction. Proc. GSCL 30, 31–40 (2009)
Campello, R.J.G.B., Moulavi, D., Sander, J.: Density-based clustering based on hierarchical density estimates. In: Pei, J., Tseng, V.S., Cao, L., Motoda, H., Xu, G. (eds.) PAKDD 2013. LNCS (LNAI), vol. 7819, pp. 160–172. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-37456-2_14
Constantino, K., et al.: Segmentação e classificação semântica de trechos de diários oficiais usando aprendizado ativo. In: SBBD, pp. 304–316. SBC (2022). https://doi.org/10.5753/sbbd.2022.224656
Devlin, J., et al.: BERT: pre-training of deep bidirectional transformers for language understanding. In: NAACL-HLT, pp. 4171–4186. Association for Computational Linguistics (2019). https://doi.org/10.18653/v1/n19-1423
Dieng, A.B., Ruiz, F.J.R., Blei, D.M.: Topic modeling in embedding spaces. Trans. Assoc. Comput. Linguistics 8, 439–453 (2020). https://doi.org/10.1162/tacl_a_00325
Feldman, R., Sanger, J.: The Text Mining Handbook - Advanced Approaches in Analyzing Unstructured Data. Cambridge University Press (2007)
Feng, F., et al.: Language-agnostic BERT sentence embedding. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), pp. 878–891. Association for Computational Linguistics (2022). https://doi.org/10.18653/v1/2022.acl-long.62
Gao, T., Yao, X., Chen, D.: SimCSE: simple contrastive learning of sentence embeddings. In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 6894–6910. Association for Computational Linguistics (2021). https://doi.org/10.18653/v1/2021.emnlp-main.552
Grootendorst, M.: BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv preprint arXiv:2203.05794 (2022)
McInnes, L., et al.: UMAP: uniform manifold approximation and projection. J. Open Source Softw. 3(29), 861 (2018). https://doi.org/10.21105/joss.00861
Naseem, U., et al.: A comprehensive survey on word representation models: from classical to state-of-the-art word representation language models. ACM Trans. Asian Low Resour. Lang. Inf. Process. 20(5), 74:1–74:35 (2021). https://doi.org/10.1145/3434237
Nikiforova, A., McBride, K.: Open government data portal usability: a user-centred usability analysis of 41 open government data portals. Telematics Inform. 58, 101539 (2021). https://doi.org/10.1016/j.tele.2020.101539
Reimers, N., Gurevych, I.: Sentence-BERT: sentence Embeddings using Siamese BERT-Networks. In: EMNLP-IJCNLP, pp. 3980–3990. Association for Computational Linguistics (2019). https://doi.org/10.18653/v1/D19-1410
Silva, M., et al.: LiPSet: um conjunto de dados com documentos rotulados de licitações públicas. In: Anais do IV Dataset Showcase Workshop, pp. 13–24. SBC, Porto Alegre, RS, Brasil (2022). https://doi.org/10.5753/dsw.2022.224925
Silva, N.F.F., et al.: Evaluating topic models in Portuguese political comments about bills from Brazil’s chamber of deputies. In: Britto, A., Valdivia Delgado, K. (eds.) BRACIS 2021. LNCS (LNAI), vol. 13074, pp. 104–120. Springer, Cham (2021). https://doi.org/10.1007/978-3-030-91699-2_8
Silveira, R., et al.: Topic modelling of legal documents via legal-BERT. CEUR Workshop Proc. 1613, 0073 (2021)
Souza, F., Nogueira, R., Lotufo, R.: BERTimbau: pretrained BERT models for Brazilian Portuguese. In: Cerri, R., Prati, R.C. (eds.) BRACIS 2020. LNCS (LNAI), vol. 12319, pp. 403–417. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-61377-8_28
Souza Júnior, A.P., et al.: Evaluating topic modeling pre-processing pipelines for Portuguese texts. In: WebMedia, pp. 191–201. ACM (2022)
Turian, J.P., Ratinov, L., Bengio, Y.: Word representations: a simple and general method for semi-supervised learning. In: Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics (ACL), pp. 384–394. The Association for Computer Linguistics (2010)
Yang, Y., et al.: Multilingual universal sentence encoder for semantic retrieval. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations (ACL), pp. 87–94. Association for Computational Linguistics (2020). https://doi.org/10.18653/v1/2020.acl-demos.12
Acknowledgments.
This work was funded by the Prosecution Service of the State of Minas Gerais (Ministério Público do Estado de Minas Gerais) through the Analytical Capabilities Project (Programa de Capacidades Analíticas) and by CNPq, CAPES, and FAPEMIG.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Hott, H.R., Silva, M.O., Oliveira, G.P., Brandão, M.A., Lacerda, A., Pappa, G. (2023). Evaluating Contextualized Embeddings for Topic Modeling in Public Bidding Domain. In: Naldi, M.C., Bianchi, R.A.C. (eds) Intelligent Systems. BRACIS 2023. Lecture Notes in Computer Science(), vol 14197. Springer, Cham. https://doi.org/10.1007/978-3-031-45392-2_27
Download citation
DOI: https://doi.org/10.1007/978-3-031-45392-2_27
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-45391-5
Online ISBN: 978-3-031-45392-2
eBook Packages: Computer ScienceComputer Science (R0)