
Abstract
Using technologies capable of providing retina structure high-resolution images is one of the most widespread means of identifying structural changes that may indicate the onset or progression of visual impairment. Automated glaucoma detection using optical coherence tomography is still considered an area needing further research. Several manual analyzes are currently performed over the generated by imaging equipment. This work presents an approach to foster automatic glaucoma evaluation considering convolutional neural networks for semantic segmentation of retinal layers through optical coherence tomography images and image processing for measuring the cup region in the optic nerve head portion. We provide a quantitative evaluation comparing the results obtained by a specialist physician. The work’s main contribution consists of the first approach supporting the automation of a new biomarker for diagnosing glaucoma.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others

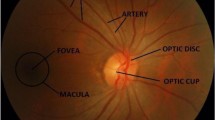

1 Introduction
Visual impairments and blindness can appear at any stage of life, but people over 50 are more likely to have some level of disability [6]. Monitoring through periodic examinations is very important as it makes it possible to identify any change in the structure of the retina. Follow-up through clinical examinations allows physicians to have an initial assessment, accompanied by intraocular pressure (IOP) measurements, a field of view testing, and structural imaging parameters. In cases of glaucoma, the disease may begin with a minimal disorder in the nerve fibers, almost invisible, and the loss of retinal ganglion cells (RGC). If it progresses to the intermediate stage, changes already become noticeable in the retinal nerve fiber layers (RNFL), along with peripheral vision loss. Finally, when fully installed, it presents serious damage and great vision loss [10].
Glaucoma is a chronic and progressive optic neuropathy characterized by the death of RGC associated with increased cupping of the optic nerve head (ONH) and a corresponding loss of visual field (VF). Several studies have shown that the lamina cribosa (LC) has a role in the pathophysiology of glaucoma. The LC is the major area related to mechanical damage in glaucoma, and the detailed assessment of disease-related changes at that site is of the most relevant interest in understanding factors concerning the development and progression of glaucoma. Furthermore, Andrade and coworkers have also proposed that LC structural differences could be responsible for different effects of IOP on the tissue, contributing to individual susceptibility to glaucomatous damage mediated by the IOP [1].
The relationship between structural and functional damage is relevant for diagnosing glaucoma. The structural evaluation of the ONH, retinal nerve fiber layers (RNFL), and macula, when analyzed by optical coherence tomography (OCT), can provide important clinical information for the diagnosis of glaucoma and the evaluation of its progression [11]. Optical coherence tomography, a technology capable of providing high-resolution images of the structure of the retina, is one of the most commonly used means of inspecting it, providing access to the visualization of the retinal layers to monitor changes in thickness and possible deformations [12].
Detecting progress with visual field tests or optic disc imaging methods is limited due to the retrospective nature and high variability. Currently, functional and structural clinical tests suffer from the need for analysis and the significant time delay required to establish disease progression and response to treatment. So does the progress of the ganglion cell loss over that time. There is, therefore, a significant unmet need for glaucoma-related biomarkers to improve clinical trials, both for early diagnosis and detection of disease progression. Biomarkers then present a possibility to provide information that will eventually affect the decisions to be taken clinically [3].
Combining new technologies, such as imaging methods (OCT) and clinical evaluation based on parameters, is one way to assess glaucoma’s criticality continuously. Optical coherence tomography provides relevant information such as cup-to-disc ratio (CDR), cup volume, rim area, and rim volume. Evaluations carried out by OCT demonstrated that regions such as Bruch’s membrane opening (BMO) for the internal limiting membrane (ILM) are correlated with the thickness of the RFNL. As well as the posterior LC, a histopathological mark of glaucoma deformation was demonstrated in the deep part of the ONH structure. This information, made available by the imaging method, allowed the correlation of both regions, where Lavinsky and coworkers formulated the hypothesis that it would be helpful as a quantitative evaluation parameter of ONH remodeling in glaucoma [11]. BMO and LC represent the legs of a right triangle and result in the evaluation by discovering the hypotenuse of the vertical region of the ONH cup. The results are presented as a morphometric biomarker.
Studies regarding the automatization of OCT image analyses can foster automatic support for evaluating the retina’s structure and identifying diseases such as glaucoma. These approaches aim to perform accurate analyses, especially with large volumes of data [5, 17]. The studies of the retina structures are also supported by the rapid advancement in scanning technologies, which enable more researchers to obtain images with a high amount of information [16, 18].
Computational methods such as Computer Vision and Deep Learning can support the necessary OCT image analysis. They allow the resolution of problems such as segmentation, and pattern identification. This research aimed to contribute improving the way of extracting information related to a new biomarker on the progress of glaucoma. The importance of the study is directly related to the possibility of an accurate analysis of the retinal layers and the possibility of extracting information with automatic support.
The article is structured as follows: Section 2 discusses related work. Section 3 describes the approach and architecture performed and its relationship with the problem. Section 4 describes the evaluation carried out, and the results obtained. Finally, Sect. 5 concludes the work.
2 Related Work
This section summarizes the studied articles, presenting the objectives and techniques used. The articles were obtained through a non-systematic review, considering the research topics regarding Deep Learning applied to ophthalmology.
Automated diagnosis through OCT images has been the focus of many researchers in recent years, showing the relevance and improvements in the investigation for more accurate results. In [13], a review was carried out on several biomarkers that used OCT extractions as a basis and the potential to support the identification of diabetic retinopathy, age-related macular degeneration, retinitis pigmentosa, and vitreomacular interface. In conclusion, OCT-based imaging biomarkers help detect disease early, classify disease severity (qualitatively and quantitatively), and modify the treatment regimen accordingly.
Proposed by Fu and coworkers [4], the method automatically evaluates the optic disc in representations of an OCT slice through detection via low-level reconstruction dealing with noise and shadows of vessels in OCT slices. Training data were extracted from a single provided OCT slice using the anterior retina structure. The method is applied to discover the boundary of the optic disc that appears at the end of the retinal pigment epithelium (RPE). Results showed that it was possible to identify the RPE points that connect to the optic disc boundary through the low-level method. Similarly, the algorithm for calculating the cup disc ratio (CDR) [10] proposed a process for extracting and contouring the inner limiting membrane layer (ILM), and in calculating the disc diameter, the endpoints of the RPE layer were used to define the disc margin.
The automation of retinal segmentation in OCT [12] images for diagnosing glaucoma was developed using a convolutional neural network (CNN) architecture, so it was possible to identify the nine layers of the retina and the optic disc for the final segmentation. The following were applied: an optic disc detection neural network (NN), a neural network for the segmentation of retinal layers, and a fusion module. In another study [22], two separate neural networks were used to perform automated segmentation of the optic disc boundary and segmentation of the peripapillary retinal layer, where the final boundary of the peripapillary retina was calculated based on prediction and gradient map, using a multiweight graph search algorithm. The study mainly applied the U-Net architecture. A DL framework for segmenting multiple retinal layers and delineating fluid pockets in OCT images of the eye [15] was implemented using a Fully Convolutional Neural Network (FCN) adapted for semantic segmentation.
It is also possible to highlight works relevant to the segmentation of the optic disc’s blood vessels or the segmentation of layers but related to other diseases, such as insufficiently corrected refractive error or age-related macular degeneration. The use of deep learning in these cases was relevant due to its possible generalization and application in cases of glaucoma. The U-Net [14] and FCN [19] inspire most architectures presented for clinical image segmentation.
There are U-Net extensions, which presented a densely connected convolutions [2], or demonstrating the possibility of having multiple U-Nets connected in a chain fashion, for the segmentation of blood vessels of the optic disc [23]. Further, the partially supervised form of retinal segmentation [18] was used in OCT images, which consists of a so-called “student-teacher” approach applied in a set with and without annotation. A new multi-prediction guided attention network (MPG-Net) [5] for automated segmentation of the retinal layer in OCT images was also created, consisting of two main steps to strengthen the discriminative power of a U-shaped FCN network and perform automated segmentation. Lastly, a framework was created to applied segmentation in OCT images of normal and pathological eyes, combining a CNN with Bidirectional Long Short-term Memory (BLSTM) [7].
Finally, it can be highlighted that OCT technology provides a range of information regarding the evaluation and progress of vision-related deformities, such as the evaluation of morphometry parameters and topography of the optic nerve head, calculation of the excavation proportion for the optic disc, cup volume, rim area, and rim volume [11]. These are essential concepts that help in investigations into the evolution of retinal damage.
3 Proposed Approach
Some studies demonstrate the importance of obtaining evaluation parameters (biomarkers). One of the ways observed was using the Pythagorean theorem [11] to assist in evaluating the vertical optic nerve head using SD-OCT enhanced depth imaging (EDI). The vertical B-scan with the largest cup seen in infrared is used for hypotenuse measurement. The depth of posterior displacement of the lamina cribrosa (LC), measured from the opening of Bruch’s membrane level (BMO), and the length of the excavation between the BMO boundary and the ILM layer, form the sides of a right triangle, used in the calculation (Fig. 1 right). The discovery of the hypotenuse is a helpful parameter for the quantitative assessment of optic nerve head remodeling in patients with glaucoma. Therefore, the motivation of the work is associated with supporting the identification of the new biomarker, applying computational techniques for the measurement, and quantitative analysis of the identified method.

Left figure shown each part of retina, in a B-Scan. Right figure shown the hypotenuse measurement [11].
In order to obtain analysis on the mentioned biomarker, the research was developed in three stages. The first stage includes collecting the OCT images with the physician to take notes and select the regions of interest. In the second stage, these images are used as input data in a convolutional neural network for semantic segmentation. In the last stage the output of the neural network, containing the segmentation images, a computer vision algorithm is applied to obtain coordinates that will result in the identification of the region of interest. This last stage is performed by implementing the biomarker approach defined by [11]. The results are compared with those analyzed by the specialist in the manual experiments in a previous study. The Fig. 2 shown an overview of each step.

General overview
3.1 Data Annotation
This research developed a new annotated dataset to support the experiments. The overall context and main procedures are commented in this section.
All original research participants underwent SD-OCT (Spectralis OCT; Heidelberg Engineering GmbH, Dossenheim, Germany). Moreover, the scans (B-Scan and C-Scan) were exported in JPEG format files for the current research. Each image represents only one eye (right or left), with the union of the two scans in the same image. Finally, Photoshop image editing software was used to support the cuts, annotations, and export to the desired sizes.
As shown in Fig. 3, the first step refers to loading the images and selecting the region of interest to perform the cut. All images had the same size after cropping. Cropping all images with the same size is essential for input data in the neural network. In supervised neural networks, the image task must have the same pattern as the input data. The second step, shown in the exact figure, is the result of annotating the regions of interest after making the cuts. This step was conducted with a medical student to obtain the layers of the retina as accurately as possible, where files were obtained with the notes of each layer and later merged into the primary image. Each layer was exported separately in the annotation process: ILM layer annotation, RPE layer annotation, and the selected region of the retinal layer. The exported clippings were turned into PNG files because the format allows lossless compression and less loss of quality. The files are organized in different folders in the third step according to each export performed. This distinction is because the neural network requires actual (or ground truth) and annotated data as input. Therefore, the annotations images are to use with the image cropped under the same region.

Annotated data flow.
The set of images obtained contains 80 folders with images of both eyes. However, some exclusions were made. Folders that did not contain one or both images, corrupted files, and folders with the same images were exclusion criteria. Therefore, from the total of 160 images, 134 images remained for use.
Throughout the experiments, the number of images was also modified. Tests were carried out with the entire set of images and new exclusions and separations. Tests without images with high contrast or noise were also applied. The same equipment can generate important differences in terms of noise presence or overall illumination in the image. This context fostered some experiments with image subsets, according to these main aspects.
We apply some different tests with the images obtained during the research period: test using all data; changing the process for choosing the images, where the images that seemed to present greater similarity in overall aspects were chosen manually; the way of annotating the RPE layer where outlines have been replaced by fills (this aspect was possible because to us it’s essential the limit of RPE layer on level of BMO as shown on Fig. 1 left).
3.2 CNN Architecture
The present work used a neural network to perform tasks related to image segmentation. The use of the U-Net architecture [14] was defined as a starting point. Improvements were then included, in order to foster the results.
The architecture consists of a contraction path to capture context and a symmetric expansion path for localization. The contraction path consists of a typical convolutional network, with two convolutions followed by a ReLU (rectified linear unit) activation function and a max polling operation. The use of the regularization dropout technique to reduce overfitting was also considered. The number of resource channels doubles each reduction step (downsampling). The expansion path consists of an upsampling of the feature map, followed by an up-convolution that halves the number of feature channels, a concatenation with the corresponding clipped feature map from the contracting path, and two convolutions followed each by the ReLU function. Still, according to the authors, clipping is necessary due to the loss of edge pixels in each convolution. In the final layer, a 1\(\,\times \,\)1 convolution maps each feature vector to the desired number of classes.
This is a network with no fully connected layers and which uses only the valid part of each convolution, i.e., the segmentation map only contains the pixels for which the entire context is available in the input image. It also allows the continuous segmentation of arbitrarily large images by a block overlay strategy, predicting the pixels in the region of the edge of the image that, due to the missing context, are extrapolated, mirroring the input image.

U-Net Architecture.
Changes were made to the architecture (Fig. 4) based on two articles, [8, 21]. In both, there is the presence of additional blocks between the path of contraction and expansion. These modules allowed the extraction of information from the semantic context and the generation of high-level resource maps. The dense atrous convolution (DAC) module was used for the present work. DAC was designed to extract features from objects with different sizes using a set of dilated convolutions.

Dilated convolution [21].
Dilated convolution was initially proposed for computing the wavelet transform. Allows insertion of zeros between consecutive values along the spatial dimension. Standard convolutions have a rate of change equal to 1, while atrous convolution allows changing this value. This type of operation supports the exponential expansion of receptive fields without loss of resolution or coverage [21] (Fig. 5). Thus, a DAC block was inserted between the contraction and extension paths to extract the features at different scales. Based on Li and coworkers, the same branch structure was used within the DAC module (Fig. 6), only changing the feature map from 512 to 1024.

Dense atrous convolution (DAC) [8].
Finally, the cross entropy loss function was initially used for model training due to its ability to calculate the difference between two probability distributions, which in this case are the pixels for the background and foreground. However, objects in medical images, such as the optic disc and retinal layers, occupy small regions compared to the whole. According to [8], cross-entropy is not performant in these cases and can be replaced by the loss function known as the Dice coefficient, which looks for the correlation between the prediction points and the annotations.
3.3 Data Augmentation
Some surveys often have the opportunity to use large amounts of data [22]. However, there are cases in which data collection could not be more voluminous due to access difficulties (restricted data), collection time, and variability to avoid creating bias, among other reasons. All this makes it impossible to have a more malleable set or with large variations. For this reason, the data augmentation technique allows the virtually simulating of new data based on the original input data, helping to increase the amount of data available for experiments.
Many modifications can be carried out using some specific API (e.g., Keras or PyTorch). However, it is also possible to carry out manually, implementing codes using libraries such as OpenCV, which allow greater flexibility in using functions. Operations as horizontal flip, rotation, scale and shift was used.
3.4 Measurement of Cup Portion on ONH Structure
The capture, annotation, and prediction process allows a flow to obtaining segmented images by a neural network. This result is then used as a final step to obtain values in the retinal excavation region. In this way, the calculation presented [11] can be carried out and evaluated computationally.
The first necessary step is to obtain the coordinates and excavation length value between the BMO boundary and the ILM layer. Next, the segmented images of the two layers are joined to be able to search the depth. The depth of posterior displacement of the lamina cribrosa (LC), measured from the line created at the level of opening of Bruch’s membrane level (BMO), is then used as a source for obtaining the measurement.
The values obtained make it possible to assume that they are the legs in the Pythagorean equation. Moreover, in this way, obtaining the hypotenuse is discovered in pixel value. The last step is the conversion from pixel to micron, the unit of measurement used by the scanning equipment. This entire process is performed using the Python programming language.
4 Conversion to Micron Meter
The values found are still in pixels at the end of the search step for regions connected to the cup region. Therefore, there is a need for conversion to the measurement unit used by physicians.
The conversion process is currently manual since we use a scale available in the image obtained by EDI SD-OCT. This scale is always found in the lower part of the images and in an “L” shape, where the vertical bar represents a scale, and the horizontal bar represents another scale.
Using the ImageJ software, it is possible to convert the pixel distance of each orientation to the displayed reference (200 \(\upmu \)m), as shown in the Fig. 7. The returned values are then used as fixed parameters in the flow presented in the previous section.

Measurements using ImageJ software.
5 Results
This section describes the experiments with the neural network architecture and the results obtained together with the results of the final stage, where the discovery of the hypotenuse over the disc region of the cup is performed and compared with the physicians’ measurements.
Also, it’s important mentioned that for the neural network, the implementation is based on the Keras API running under TensorFlow. All training was performed using Google Colab connected to GPUs.
The NN U-net trained images layers separately: one applied to images of the ILM layer and another to the RPE layer. For training and testing, we separated the images to leave 70% for training and 30% for validation and testing (half for each). Different hyperparameters and changes in the number of epochs were applied to train the model.
5.1 Evaluation of NN Segmentation
For the model evaluation, we decided to use mainly two metrics for segmentation tasks. The evaluation metrics were the Intersection Over Union (IoU) and F1-Score (F1). Other metrics, such as Recall and Precision, were also analyzed together, as they are part of the previous metrics’ equation.
As mentioned in the work of Rezatofighi and coworkers, IoU, the Jaccard index, is the most commonly used metric for comparing the similarity between two arbitrary shapes. IoU encodes the shape properties of the objects under comparison, e.g., the widths, heights, and locations of two bounding boxes, into the region property and then calculates a normalized measure that focuses on their areas [9]. Also, according to another work, both metrics (IoU and F1) measure the same aspects and provide the same system classification. Therefore, the use of each one may depend on the case [20].
5.2 Results over Segmentation Using NN
It was possible to carry out four tests with the U-net network during the study period. The first one will not be included in the present study since the sample contains less than ten images. The other tests were performed with different numbers of images, changes in hyperparameters, re-annotation of images, and excluding someFootnote 1.
To outermost layer (ILM), it was possible to notice that there was a slight variation in the results obtained (Table 1) where most of the collected images there was little difference in contrast and variation in quality besides being a border region between the background and the scanned retina. In this way, it was possible to obtain results in this layer with less variation.
In contrast, the RPE layer initially obtained lower values than the other region (Table 2). We noticed that the neural network did not perform well when detecting a more internal part with a thin line (annotation). Architectural changes were made but without success. The annotations for the last two tests were then modified, containing thicker annotations, focusing more on the boundary region between the RPE and the BMO since it is vital for the final calculation.
The results also show that adjusting the neural network and defining it as an isolated neural network for each image context is necessary. In this way, hyperparameters and configurations apply to each case.
5.3 Discovery of the Hypotenuse in the Excavation Region
Experiments were carried out at this stage to understand the feasibility of using computer vision libraries, such as OpenCV in Python, to identify measurements in the excavation region.
The algorithm created to identify what was described in the Sect. 3.4 obtained results that were compared with the values obtained by the physician in his study. In Table 3, it is possible to see the comparisons between each measured part and the final result, the hypotenuse. The final differences between the measurements taken by the doctor and those found by the algorithm can still be caused by manual measurement and the erroneous reading of some pixels in the final step. There is a need for a larger sample of data for comparison.
As shown in the Table 3, columns: length, depth and hypo are the values obtained by the physician. Columns with the same name but with sufix “-alg” it is a reference to the algorithm created and described in the Sect. 3.4. The column “diff: hypo” show the difference between both results obtained by the physician and the algorithm. The results still are considere high, where it is necessary a new study to evaluate what may have affected this difference.
6 Conclusion
OCT is a modern and sophisticated image extraction technology that can perform excellent results in scanning the retina and inner layers. However, several studies still enable new ways for more accurate disease analysis. In the present study, deep learning focused on semantic segmentation was evaluated to enable the possible results and benefits of the technique and used to perform a mathematical calculation to reproduce the hypotenuse measurement over the optic nerve’s head.
The retina structure presents very sensitive characteristics in which detailed analyses are necessary. In this study, a specialist physician and a medical student participated, enabling data availability and helping in the steps of notes taken.
It was possible to use neural networks to identify the layers of the retina and their segmentation. The results obtained, even though they need adjustments, were used to measure the region of the cup in the optic nerve head and calculate the hypotenuse. There are still improvements that need to be made, as well as new studies. It also noticed the need to separate the neural network in the future, applying different architectures for each layer of the annotated retina.
One limiting point that follows since the beginning of the research is the number of images. In which, as highlighted in Sect. 3.1, many images were excluded by quality criteria. There is still a significant challenge in working with variations in images, whether they are: contrast or the presence of noise. Different from the quality of the images, even with the cuts made, we use images in large sizes compared to other datasets of different themes.
The use of images from only one OCT device can be a factor that negatively contributes to the creation of a bias since we do not know the limitations and the pattern of the generated images. Still, there is more than one type of glaucoma, which can also affect results generation if the region does not have a similar pathology.
Moreover, finally, in order to calculate the hypotenuse, there is still a need to investigate how to convert the pixel aspect ratio to the micron unit (\(\upmu \)m) without using secondary software. Currently, it is necessary to open some image through the ImageJ software and to read informations from scale bar, where it is possible know the distances of micron in pixels. This is necessary to convert the results from hypotenuse findings (Sect. 4).
From future adjustments, both in the neural network and the extraction algorithm, it will be possible to obtain even better results since the hypotenuse measurement over the excavation region is simple and reproducible. Moreover, it contributes to the possibility of making this approach viable as a support tool in diagnosing patients with glaucoma.
The ethics committee of the Hospital de Clinicas de Porto Alegre approved the study and it was conducted in accordance with the Declaration of Helsinki. Informed consent was obtained from all participants.
References
Andrade, J.C.F., Kanadani, F.N., Furlanetto, R.L., Lopes, F.S., Ritch, R., Prata, T.S.: Elucidation of the role of the lamina cribrosa in glaucoma using optical coherence tomography. Surv. Ophthalmol. 67(1), 197–216) (2022). https://doi.org/10.1016/j.survophthal.2021.01.015
Azad, R., Asadi-Aghbolaghi, M., Fathy, M., Escalera, S.: Bi-directional ConvLSTM U-Net with Densley connected convolutions. In: Proceedings - 2019 International Conference on Computer Vision Workshop, ICCVW 2019, pp. 406–415 (2019). https://doi.org/10.1109/ICCVW.2019.00052
Beykin, G., Norcia, A.M., Srinivasan, V.J., Dubra, A., Goldberg, J.L.: Discovery and clinical translation of novel glaucoma biomarkers. Progress Retinal Eye Res. 80 (2021). https://doi.org/10.1016/j.preteyeres.2020.100875
Fu, H., Xu, D., Lin, S., Wong, D.W., Liu, J.: Automatic optic disc detection in OCT slices via low-rank reconstruction. IEEE Trans. Biomed. Eng. 62(4), 1151–1158 (2015). https://doi.org/10.1109/TBME.2014.2375184
Fu, Z., et al.: MPG-Net: multi-prediction guided network for segmentation of retinal layers in OCT images. In: European Signal Processing Conference, pp. 1299–1303, January 2021. https://doi.org/10.23919/Eusipco47968.2020.9287561
GBD 2019 Blindness and Vision Impairment Collaborators: Vision Loss Expert Group of the Global Burden of Disease Study. Causes of blindness and vision impairment in 2020 and trends over 30 years, and prevalence of avoidable blindness in relation to VISION 2020: the Right to Sight: an analysis for the Global Burden of Disease Study [published correction appears in Lancet Glob Health. 2021 Apr; 9(4):e408]. Lancet Glob Health 9(2), e144–e160 (2021). https://doi.org/10.1016/S2214-109X(20)30489-7
Gopinath, K., Rangrej, S.B., Sivaswamy, J.: A deep learning framework for segmentation of retinal layers from OCT images. In: Proceedings - 4th Asian Conference on Pattern Recognition, ACPR 2017, pp. 894–899 (2021). https://doi.org/10.1109/ACPR.2017.121
Gu, Z., et al.: CE-Net: context encoder network for 2D medical image segmentation. IEEE Trans. Med. Imaging 38(10), 2281–2292 (2019). https://doi.org/10.1109/TMI.2019.2903562
Rezatofighi, H., Tsoi, N., Gwak, J., Sadeghian, A., Reid, I., Savarese, S.: Generalized intersection over union: a metric and a loss for bounding box regression. CoRR (2019). https://doi.org/10.48550/arXiv.1902.09630
Khalil, T., Akram, M.U., Raja, H., Jameel, A., Basit, I.: Detection of glaucoma using cup to disc ratio from spectral domain optical coherence tomography images. IEEE Access 6, 4560–4576 (2018). https://doi.org/10.1109/ACCESS.2018.2791427
Khalil, T., Akram, M.U., Raja, H., Jameel, A., Basit, I.: Detection of glaucoma using cup to disc ratio from spectral domain optical coherence tomography images. IEEE Access 6, 4560–4576 (2018). https://doi.org/10.1109/ACCESS.2018.2791427
Li, J., et al.: Multi-scale GCN-assisted two-stage network for joint segmentation of retinal layers and disc in peripapillary OCT images. Biomed. Opt. Express 12, 2204–2220 (2021)
Phadikar, P., Saxena, S., Ruia, S., Lai, T.Y.Y., Meyer, C.H., Eliott, D.: The potential of spectral domain optical coherence tomography imaging based retinal biomarkers. Int. J. Retina Vitreous 3(1), 1–10 (2017). https://doi.org/10.1186/s40942-016-0054-7
Ronneberger, O., Fischer, P., Brox, T.: U-Net: convolutional networks for biomedical image segmentation. IEEE Access 1, 16591–16603 (2015). https://doi.org/10.1109/ACCESS.2021.3053408
Roy, A.G., et al.: ReLaynet: retinal layer and fluid segmentation of macular optical coherence tomography using fully convolutional networks. Biomed. Opt. Express 8, 3627–3642 (2017). https://doi.org/10.1364/boe.8.003627
Sander, B., Larsen, M., Thrane, L., Hougaard, J.L., Jørgensen, T.M.: Enhanced optical coherence tomography imaging by multiple scan averaging. Br. J. Ophthalmol. 89(2), 207–212 (2005). https://doi.org/10.1136/bjo.2004.045989
Schmidt-Erfurth, U., Sadeghipour, A., Gerendas, B.S., Waldstein, S.M., Bogunović, H.: Artificial intelligence in retina. Prog. Retin. Eye Res. 67, 1–29 (2018). https://doi.org/10.1016/j.preteyeres.2018.07.004
Sedai, S., et al.: Uncertainty guided semi-supervised segmentation of retinal layers in OCT images. In: Shen, D., et al. (eds.) MICCAI 2019. LNCS, vol. 11764, pp. 282–290. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-32239-7_32
Shelhamer, E., Long, J., Darrell, T.: Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 39(4), 640–651 (2017). https://doi.org/10.1109/TPAMI.2016.2572683
Taha, A.A., Hanbury, A.: Metrics for evaluating 3D medical image segmentation: analysis, selection, and tool. BMC Med. Imaging (2015). https://doi.org/10.1186/s12880-015-0068-x
Yu, F., Koltun, V.: Multi-scale context aggregation by dilated convolutions. In: 4th International Conference on Learning Representations, ICLR 2016 - Conference Track Proceedings (2016)
Zang, P., Wang, J., Hormel, T.T., Liu, L., Huang, D., Jia, Y.: Automated segmentation of peripapillary retinal boundaries in OCT combining a convolutional neural network and a multi-weights graph search. Biomed. Opt. Express 10(8), 4340 (2019). https://doi.org/10.1364/boe.10.004340
Zhuang, J.: LadderNet: multi-path networks based on U-Net for medical image segmentation, pp. 2–5 (2019)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Fernandes, G.C., Lavinsky, F., Rigo, S.J., Bohn, H.C. (2023). Exploring Artificial Intelligence Methods for the Automatic Measurement of a New Biomarker Aiming at Glaucoma Diagnosis. In: Naldi, M.C., Bianchi, R.A.C. (eds) Intelligent Systems. BRACIS 2023. Lecture Notes in Computer Science(), vol 14197. Springer, Cham. https://doi.org/10.1007/978-3-031-45392-2_30
Download citation
DOI: https://doi.org/10.1007/978-3-031-45392-2_30
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-45391-5
Online ISBN: 978-3-031-45392-2
eBook Packages: Computer ScienceComputer Science (R0)