
Abstract
In this work, we address the challenge of training machine learning models on sensitive clinical data while ensuring data privacy and robustness against data corruption. Our primary contribution is an approach that integrates Conformal Prediction (CP) techniques into Federated Learning (FL) to enhance the detection and exclusion of corrupted data contributors. By implementing a client-dropping strategy based on an adaptive threshold informed by the interval width metric, we dynamically identify and exclude unreliable clients. This approach, tested using the MedMNIST dataset with a ResNet50 architecture, effectively isolates and discards corrupted inputs, maintaining the integrity and performance of the learning model. Our findings demonstrate that this strategy prevents the potential 10% decrease in accuracy that can occur without such measures, confirming the efficacy of our CP-enhanced FL methodology in ensuring robust and private data handling in sensitive domains like healthcare.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others


1 Introduction
With advancements in computer systems and medicine, computer-assisted diagnoses have become more prevalent, aiding specialists in decision-making [19]. Often, the data involved are sensitive, and their dissemination is constrained by privacy and security regulations. An example of such regulations is the Brazilian General Data Protection Law (Lei Geral de Proteção de Dados - LGPD) [4], which reflects a common legislative approach among various countries. Furthermore, the Brazilian Bank Secrecy Law (Lei de Sigilo Bancário) [3] imposes additional restrictions on the circulation and disclosure of data, often resulting in a scarcity of large and accessible datasets [1]. This scenario presents a significant challenge for the training of deep learning models, which typically require extensive datasets.
In this context, Federated Learning (FL) [21] offers a compelling strategy for building collaborative models among entities holding sensitive data without the needed of sharing it. FL achieves this by training multiple local models on decentralized datasets and then aggregating these models to form a comprehensive global model. This methodology permits all participating entities to benefit from the collectively derived insights while maintaining the confidentiality of their data [7]. Moreover, as the models are trained locally, the overall demand for computational power is significantly diminished. This efficiency allows for the integration of larger datasets into the training process without the need for high-cost computational resources. By implementing federated learning, institutions can leverage diverse datasets for the enhancement of medical AI applications, thereby advancing healthcare innovations without breaching data privacy.
Addressing the data sharing challenge through Federated Learning (FL) is not straightforward. The difficulty arises because participants in a federated learning setup might contribute inconsistently, that is, some participants may not contribute effectively, while others could inadvertently or maliciously introduce corrupted data. Managing such corrupted data is a significant challenge; it can severely degrade the performance and reliability of the overall model. Ensuring that models maintain their robustness in the face of corrupted data is therefore a crucial obstacle that must be overcome [15].
Previous approaches have faced challenges in balancing data privacy with model reliability [10]. This work integrates Conformal Prediction (CP) techniques [2, 16] within a federated learning framework, enhancing both the robustness and reliability of the model by providing a measure of uncertainty for each client. CP, a statistical approach that validates the confidence level of predictions, allows for the use of CP metrics to develop an adaptive threshold strategy. This strategy identifies and manages clients contributing corrupted data during aggregation rounds, thereby ensuring that central model training incorporates only reliable data.
The primary objective of this work is to test the hypothesis that applying conformal prediction techniques within a federated learning context can enhance the robustness and reliability of trained models in medical applications, particularly in distributed scenarios where corrupted data may be present. Two research questions arise from this hypothesis: (RQ1) How does the introduction of corrupted data affect the precision and reliability of trained models in a federated learning context? (RQ2) Can a client-dropping strategy based on conformal prediction metrics effectively reduce the negative effects of corrupted data on a global model in a federated learning context? To address these research questions and the hypothesis, we conducted experiments using the MedMNIST dataset [20], comparing the results of a traditional neural network approach with those of a federated approach. Additionally, we developed a strategy to manage clients with bad/corrupted data based on an adaptive conformal prediction threshold. This threshold uses the interval width metric to determine whether a client should be dropped during an aggregation round.
The experimentation revealed that the proposed strategy is resilient in the presence of corrupted data, with an average accuracy difference of less than 2% between an expected scenario with no corrupted data and a scenario with a corrupted client using the proposed approach. In contrast, a scenario with corrupted data without the proposed strategy showed almost a 10% decrease in accuracy. Furthermore, applying the proposed approach in a context with no corrupted clients resulted in a difference of less than 1% and even enhanced accuracy in some datasets. These results demonstrate that the proposed strategy is resilient against corrupted data and does not negatively impact scenarios without corrupted clients.
This work is subdivided as follows: Sect. 2 presents related works; the data used is presented in Sect. 3; Section 4 presents proposed methodology, followed by experiments and results in Sect. 5; finally, conclusions and future researches are presented on Sect. 6.
2 Related Works
Although studies on Federated Learning (FL) are relatively recent, they already show promising results. In [9], the authors conducted tests on three different datasets (MNIST, MIMIC-III, and ECG), and in all three cases, the models were able to maintain good predictive performance. Additionally, the federated approach proved robust against data distortion and imbalanced distribution, demonstrating that, besides promoting data security, federated learning can bring various other benefits.
Other recent approaches combine Graph Neural Networks (GNNs) with federated learning [6]. It shows that this hybrid approach, in addition to the evident privacy gains, was able to maintain high-quality predictive performance, matching or even surpassing centralized learning in some cases. However, the authors noted that federated GNNs perform worse on datasets with non independent and identically distributed data distribution (non-IID split) compared to centralized approaches. They suggest that future work should address this and other challenges in the field of FL.
In [14], a study on various model aggregation techniques was conducted. Using the MNIST dataset, the authors tested Federated Averaging (FedAvg), Federated Stochastic Variance Reduced Gradient, and CO-OP, achieving the best results with FedAvg. They also noted that FedAvg is efficient with or without independent and identically distributed (i.i.d.) partitioning, and for i.i.d. partitioning, the performance is similar to the centralized approach. This reinforces the hypothesis that federated learning can avoid data exchange while maintaining the efficiency of trained models in various scenarios.
Related to the training and aggregation process, the FOLB algorithm was proposed in [13]. It promises to accelerate and improve the convergence of FL models. The algorithm analyzes the computation capacity, communication, and heterogeneity of the clients to perform client sampling in each training round. It assigns different weights to each client’s model during the aggregation process. The authors conducted empirical tests and demonstrated that the algorithm improves the convergence speed, accuracy, and stability of models across many tasks and datasets.
Regarding information security in federated learning, [12] discusses that, despite providing a learning environment without the need to share data, federated learning still presents some vulnerabilities that designers must be aware of. Poisoning attacks and inference attacks threaten the learning environment by allowing malicious clients to distort the produced data, making gradient descent inefficient and hindering the construction of an effective model. Additionally, analyzing data provided by the server, such as weights and/or loss from each training round, can infer input data and their labels from other clients in the federated network.
In high-stakes decision-making scenarios (e.g., medical), the lack of model interpretability can lead to distrust among users. In [11], the authors propose Conformal Prediction (CP) analysis as an effective and simple way to provide statistical confidence in predictions, offering clear information about prediction uncertainty without requiring direct modification to the model training process. In their experimentation, they conducted CP analysis on a model trained under the FL paradigm using 6 subsets from MedMNIST (Blood, Derma, Path, Tissue Retina, Organ3d). They achieved up to \(97\%\pm 0.7\%\) coverage and found a correspondence between conformal uncertainty and prediction task difficulty (measured by class entropy).
In summary, the studies discussed in this section highlight the growing importance and promising potential of federated learning. Various works demonstrate, in different contexts and types of data, that federated approaches are robust and efficient. However, it is crucial to recognize and address the identified vulnerabilities, such as poisoning and inference attacks, to ensure the integrity and security of federated learning systems. Unlike the work in [11], we not only analyze CP but also introduce a client-dropping strategy.
3 MedMNIST Dataset
The MedMNIST dataset [20] consists of a collection of 18 subsets of biomedical images standardized in a format similar to MNIST. This dataset comprises 12 subsets of pre-processed data in \(28\times 28\) (2D) and six more subsets in \(28\times 28\times 28\) (3D). Among these subsets, only the Path, Blood, Derma, and Retina datasets are in RGB format, while the others are in grayscale. This data collection was developed to address a variety of tasks, such as binary/multi-class classification, ordinal regression, and multi-label tasks, and it covers a wide range of data scales, ranging from 100 to 100,000 images. Figure 1 presents examples of all the used datasets.

Adapted from [20].
Used subsets of MedMNIST Dataset.
Considering the nature of the data in the MedMNIST datasets, some were excluded from this work. The Chest subset was discarded because it is multi-label (the same image belongs to one or more classes simultaneously), and the 3D subsets—Organ, Nodule, Adrenal, Fracture, Vessel, and Synapse—were also excluded. Therefore, the remaining 11 datasets used in this work are: Blood, Breast, Derma, Oct, OrganA, OrganC, OrganS, Path, Pneumonia, Retina, and Tissue.
Each dataset used in this study is from a medical domain. The descriptions of each dataset are as follows:
-
The Blood dataset regards the problem of classifying blood cells.
-
The Breast dataset comprises breast ultrasound images divided into two conditions: normal or benign (1), and malignant (2).
-
The Derma dataset contains dermatoscopic images of pigmented skin lesions, split into seven different diseases.
-
The OCT dataset includes optical coherence tomography (OCT) images for retinal diseases, divided into four diagnoses.
-
The OrganA/C/S datasets consist of computed tomography (CT) scan images of body organs from three viewing planes: axial, coronal, and sagittal.
-
The Path dataset is made up of histological images of colorectal cancer used to predict the survival of individuals, collected from two subsets: NCT-CRC-HE-100k (training and validation) and CRC-VAL-HE-7k (testing).
-
The Pneumonia dataset consists of pediatric chest X-ray images classified as pneumonia or normal.
-
The Retina dataset contains fundus images used for ordinal regression to classify the severity of diabetic retinopathy into five levels.
-
The Tissue dataset consists of images of human renal cortex cells divided into eight classes.
It is worth noting that the image formats were not altered, and no preprocessing was applied to the data. Table 1 provides details for each of the datasets used.
4 Methodology
In this section, we outline the methodology adopted for this studyFootnote 1 and the metrics used for evaluation. First, we present the model used for the evaluation process, along with the federated learning strategy employed. Next, we introduce and describe the proposed approach that utilizes conformal prediction for client-dropping. Finally, we detail the metrics used to evaluate the model, including an in-depth description of the conformal prediction metrics used.
4.1 Model Used on Training Process
The authors of [20] used the ResNet architecture [18] for their benchmark. For this reason, the ResNet50 architecture was employed in this study without pre-trained weights, with modifications only to the input data format and the number of neurons in the last layer to suit each data subset. The ResNet50 architecture consists of 49 convolutional/pooling layers, with the final layer being fully connected for classification.
For comparison purposes, the same model used in federated training was also evaluated in a centralized context. The model was trained for a proportional number of epochs and evaluated on the same test data.
In both cases, the validation data were used to identify the best model during training. The model with the lowest loss and highest accuracy rate during the global epochs was used to calculate the metrics and report the results.
4.2 Federated Learning
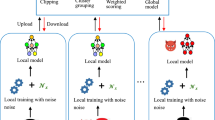
Federated Learning (FL) [21] is a technique for training deep learning models that operates in a distributed environment, allowing for the collaborative learning of a global model while the data remains locally on the users’ devices. In contrast to centralized approaches, where all data is available in a single location for model training, FL allows diverse devices and servers to perform training in parallel without data centralization, avoiding data exchange [7]. Figure 2 shows the workflow of the FL technique used in this work.

A client, with his respective portion of data D (\(D^C\) all clients have the entire training dataset, \(D^F_i\) each client has a portion of the entire training dataset), trains a local model \(M^{L} _{i}\). Those local models are aggregated generating a new global model \(M^{G}_{i}\), which is then distributed across all clients for a new training round. This process is repeated for a number of global epochs, and after that the final global model is evaluated.
For the federated model experimentation, the data was divided in two ways. In the first format, each client has access to all entries in the dataset. This strategy is referred to in the experiments as “Complete Dataset”. Although this format is not realistic, it serves as an upper bound on accuracy performance. In the second format, referred to as “Fragmented Dataset” in the experiments and closer to a real-world scenario, each client has \(\frac{1}{Q_c}\) percent of the dataset, where \(Q_c\) is the total number of clients in a given execution. This second strategy allows the repetition of the same training/validation instance among clients. However, despite possible repetitions, there is considerable data diversity among clients. They can be described as:
-
Complete Dataset: Let D be the dataset, and \(M_g\) be the global model. In the complete dataset format, each client \(c_i\) with data \(D_i\) has access to the entire dataset D, that is
$$\begin{aligned} D_i = D, \quad \forall i \in \{1, 2, \ldots , Q_c\}. \end{aligned}$$(1) -
Fragmented Dataset: In the fragmented dataset format, each client \(c_i\) has access to a \(\frac{1}{Q_c}\) fraction of the dataset \(D_i\), that is
$$\begin{aligned} D_i = \frac{D}{Q_c}, \quad \forall i \in \{1, 2, \ldots , Q_c\} \end{aligned}$$(2)
There are various strategies for manipulating and calculating the loss value during federated training. Among the existing ones, Federated Averaging (FedAvg) was chosen due to the good results presented by [14, 17]. In this context, the loss function value of a global epoch is calculated using the average error found on each client. This value is used to update the global model weights, which are then redistributed to all clients. It can be defined as:
-
Federated Averaging: Each client \(c_i\) trains a local model \(M_{l_i}\) on its local dataset \(D_i\) and computes the local loss \(L_{l_i}\). The local models and losses are then sent to the server to update the global model \(M_g\). The global loss (\(L_g\)) is defined as:
$$\begin{aligned} L_g = \frac{1}{Q_c} \sum _{i=1}^{Q_c} L_{l_i}. \end{aligned}$$(3) -
Updating the global model weights: The global model weights are updated using the average of the local models’ parameters, described as:
$$\begin{aligned} M_g = \frac{1}{Q_c} \sum _{i=1}^{Q_c} M_{l_i}. \end{aligned}$$(4)
It is worth pointing out that the updated global model \(M_g\) is then redistributed to all clients for the next round of training. The entire process can be seen in Algorithm 1. Besides, in both federated and local training, the test data is used only for metric calculation and not for training.

Proposed Federated Model Experimentation
4.3 Measuring Uncertainty with Conformal Prediction
For the conformal prediction [2] analysis, two metrics were used: interval width (|I|) and coverage rate (CR). The interval width can be mathematically defined as:
where \(Q{\alpha }\) is the \(\alpha \) quantile of the residual distribution \(R = |\hat{y}_i - y_i|\) (\(\hat{y}_i\) being the prediction and \(y_i\) the true label), indicating how far predictions are from true labels. The smaller the |I|, the less uncertainty there is in the predictions [5, 16].
The coverage Rate can be mathematically defined as:
where n is the number of instances, \(I(x_i)\) is the prediction interval for instance \(x_i\), and f is a function that returns 1 if the condition is true and 0 otherwise. The higher the coverage rate, the more reliable is the predicted interval in containing the true values [8].
4.4 Conformal Prediction Based on Strategy for Dropping Clients
During the federated training process, clients can encounter issues and return incorrect parameters for global model merging during the global epoch. This issue can be the result of various factors, such as network problems, corrupted data, an so on. To address this issue, we propose simulating a corrupted client by replacing its data with a random array of the same dimensions.
To mitigate the negative impact of a corrupted client, we introduce a client-dropping strategy based on the interval width metric. A client is excluded from a given aggregation round if its interval width is greater than a specified threshold T, that is, \(|I_{i}| > T\), where \(|I_{i}|\) is the interval width of the i-th client calculated in Eq. (5). This threshold, which varies over the aggregation rounds, is calculated as
where \(Q_c\) is the number of clients. In practical terms, clients with interval widths 5% greater than the average are discarded and not used in computing the new global model weights. The 5% threshold was determined in preliminary runs.
This strategy aims to enhance the robustness of federated learning by effectively identifying and excluding corrupted clients. It is worth to highlight that this strategy also can remove no-corrupted clients and a client is removed during a global epoch, although, it can be used in a next global epoch, since it can be fixed during the training.
To the best of the authors’ knowledge, no other work that proposes a client drop strategy in the same way as described was found, that is, no other work used the interval width metric to drop clients in FL context. The metrics used, on the other hand, are derived from adaptations of existing works (Sect. 4.3).
4.5 Evaluation Metrics
Besides the conformal prediction metrics, accuracy (ACC) is used for evaluating the trained models. Accuracy can be defined as the number of correct classifications (where the predicted class matches the expected class) divided by the total number of classifications made. Accuracy ranges from 0 to 1 (or from 0% to 100%), where a value closer to one indicates a higher accuracy rate and better model predictions.
5 Experiments and Results
In this section, we outline the experimental setup, as well as the results and their respective implications.
5.1 Experiments Setup
For the experiments described below, the model was trained for 10 local epochs and 10 global epochs (rounds), with data divided into batches of 128 images each. The Adam optimizer was used with a learning rate of \(10^{-3}\) to adjust the model parameters, and the adopted loss function was the cross-entropy loss. A 10% learning rate decay was applied at the 50th and 75th total epoch (i.e., at the first local epoch in the fifth round and the fifth local epoch in the seventh round).
It is worth noting that the choice of these hyperparameters follows [20], aiming to keep all variables constant except for the “federated versus centralized” comparison. Additionally, for each data subset and each form of data partitioning, the number of clients involved in the training process was varied, with tests conducted with three, four, five, and six clients.
The experiments were conducted on three different systems, within the same local network, with the following configurations: System 1: Intel I7-5820k 3.3 GHz; GPU TitanXP 12 Gb; RAM DDR4 12 GB; System 2: Intel I9-10900 2.80 GHz; GPU RTX 3090 24 GB; RAM DDR4 128 GB; and System 3: AMD Ryzen Threadripper 3960X 3.70 GHz; GPU RTX 3090 24 GB.
The distribution of systems and clients was defined as follows: (i) for the scenario with three clients, one client was assigned to each system; (ii) for four clients, two clients were on System 2 and one on the others; (iii) for five clients, two clients were on Systems 2 and 3, and only one on System 1; and (iv) for six clients, two clients were on each system. The server responsible for managing federated learning process and aggregation was always on System 3. The TensorFlow framework was used to manipulate the model, the Scikit-Learn library for calculating metrics, and the Flower framework to perform federated learning.
In addition to the above experiments, CP-related experiments were also conducted in this study. The model described in Sect. 4.1 was trained in the FL paradigm with three clients (one client per system) in both fragmented and complete dataset cases, using the same configuration as the previous experiments. For the CP-related configuration, the residual threshold was set to 0.3, and the conformal quantile was set to 0.95. These experiments were conducted in the following scenarios: S1 no data abnormalities; S2 one client with 100% corrupted data; S3 no data abnormalities along with the client-dropping strategy; S4 one client with 100% corrupted data along with the client-dropping strategy.
5.2 Experiment Results
The accuracy results achieved in the evaluations conducted in each scenario, using the ResNet50 model, are presented in Table 2. These results underscore the effectiveness and reliability of the trained model, as demonstrated by the presented data.
Regarding Table 2, it can be stated that clients who trained with the complete dataset generally achieved better results than those who trained with the subdivided dataset. Despite the difference between the strategy using the entire dataset and the one using only a portion of the dataset, it is noticeable that this difference is relatively small, typically around 0.05 or 5% in terms of accuracy.
When comparing the results of federated learning (FL) with those of local (centralized) training, it is evident that the federated model achieves comparable and, in some cases, even superior results. This phenomenon is particularly notable with fragmented datasets, where the federated model trains with different subsets of data on each client. This exposure to diverse scenarios during training enhances the model’s ability to generalize, contributing to its superior performance.
In the context of complete datasets, although the same data are used in all clients, the randomness during training also contributes to data diversification. This federated training approach results in more robust and adaptable models to different scenarios, demonstrating the effectiveness and advantages of this strategy compared to centralized training.
Still on complete datasets, it is notable that the variation in the number of clients had little impact on the obtained results, especially concerning the accuracy metric (see Table 2). This phenomenon suggests that, for this specific problem, the number of models in the aggregation had a less significant influence on the results than the amount of information available to each individual model. This observation highlights the importance of the quality and diversity of training data over the number of models used in the context of federated learning.
When comparing the accuracy obtained in the federated context with the results presented by [20], it is evident that the former stands out in five cases compared to the latter and shows comparable results in the others. This confirms the effectiveness and feasibility of this strategy.
5.3 Conformal Prediction and Client-Dropping Analysis
In this section, we present the results of the conformal prediction experiments across four scenarios (S1, S2, S3, and S4) as described in the experimental setup. This section addresses the RQ1 and the RQ2 research questions defined in the introduction. The experiments were conducted using only three clients, as no significant differences were observed in Table 2 when more clients were used, with each client utilizing the entire training dataset.
Table 3 shows a considerable reduction in accuracy when a corrupted client is included in the experiment (S2), compared to experiments without a corrupted client (S1) and those where the corrupted client removal strategy is adopted (S3 and S4) for both dataset types (complete and fragmented). For instance, in the Path and Oct subsets, the accuracy dropped by approximately 47% and 24%, respectively. Conversely, in the Derma subset, the drop was approximately 3%.
It is important to note from Table 3 that in both complete and fragmented data scenarios, the client-dropping strategy does not impact training when no corrupted client is present (S3). However, it offers significant benefits when a corrupted client is included (S4). With the client-dropping strategy, the accuracy achieved was close to the ideal (S1) and, in some cases, even higher. This can be attributed to the global model being merged with local models that have less uncertainty, resulting in a more accurate and reliable model.
Even in scenarios where the drop in accuracy was mild, prediction uncertainty generally increased. Notable examples include the Derma and OrganA datasets, where slight drops in accuracy (3% and 2%, respectively) compared to scenario S1 were accompanied by significant increases in prediction uncertainty. Specifically, there were increases of 0.39 and 0.56 in interval width and decreases of 0.28 and 0.18 in coverage rate for each respective dataset. Additionally, results from S3 and S4 are very close to (and sometimes slightly better than) those from S1.
5.4 Discussion
As can be observed in Fig. 3, all models trained with fragments of the original dataset tend to have lower accuracy performance compared to models trained with the entire dataset. It is also noticeable that the models trained with six clients had results closest to the reference benchmark values conducted in [20]. Figure 4 graphically presents the accuracy results obtained by the models trained on fragmented datasets. As can be observed, in all federated models, the results were close to the reference benchmark values conducted in [20]. The federated strategy using six clients showed the best results across all datasets. More clients were not tested due to the lack of infrastructure to run the experiments.

Accuracy graph of all models trained with fragmented and complete datasets.
Changing focus to the CP analysis, it is possible to see that prediction uncertainty metrics (i.e. interval width and coverage rate) can be very useful to detected - and possibly discard - corrupted clients and their bad contribution to the learning process. Specially on cases where accuracy drops are mild, where the high uncertainty on corrupted client predictions would probably be masked, those metrics can provide good intel whether a client is corrupted or not.
In conclusion, it is possible to state that the federated approach succeeded in avoiding data sharing while building competitive models, in terms of accuracy, when compared to the centralized model extensively tested with MedMNIST in [20]. In certain cases, especially in the tests conducted on the Blood, Breast, Derma, Oct, and Pneumonia datasets, the federated approach outperformed the reference model, reinforcing the potential efficiency of the federated strategy.

Accuracy graph of the models trained with fragmented datasets.
6 Conclusion
This study proposes a client-dropping strategy using Conformal Prediction in the federated learning context. The proposed approach preserves the positive characteristics of federated learning, such as data security, while maintaining predictive power and generalization capability in scenarios with and without clients with corrupted data, specifically in the context of the 2D-classification subsets from the MedMNIST dataset. Additionally, it fosters a learning environment less likely to incorporate noise into the learned data representation.
Overall, the proposed strategy demonstrated effectiveness by producing results comparable to or even superior to local (centralized) training and normal federated learning scenarios without corrupted clients, with less than a 2% difference in accuracy on average. When the proposed approach was not used in scenarios involving a client contributing corrupted data, we observed an average accuracy reduction of nearly 10%. These results confirm the strategy’s validity and address the initial research questions. Additionally, the consistency in performance across varying client numbers in fragmented dataset scenarios indicates that data can be effectively distributed across multiple sites without compromising computational efficiency. Future research could focus on expanding federated learning strategies, assessing the impact of a higher proportion of corrupted clients, and exploring the challenges of non-iid data splits.
References
Abad, G., Picek, S., Ramírez-Durán, V.J., Urbieta, A.: On the security & privacy in federated learning. arXiv preprint arXiv:2112.05423 (2021)
Angelopoulos, A.N., Bates, S.: A gentle introduction to conformal prediction and distribution-free uncertainty quantification. arXiv preprint arXiv:2107.07511 (2021)
Congresso Nacional: Lei complementar n\(^{\underline{\text{o}}}\) 105, de 10 de janeiro de 2001 (2001). https://www.planalto.gov.br/ccivil_03/leis/lcp/lcp105.htm
Congresso Nacional: Lei n\(^{\underline{\text{ o }}}\) 13.709, de 14 de agosto de 2018 (2018). https://www.planalto.gov.br/ccivil_03/_ato2015-2018/2018/lei/l13709.htm
Dunn, P.K., Smyth, G.K.: Randomized quantile residuals. J. Comput. Graph. Stat. 5(3), 236–244 (1996)
He, C., et al.: FedGraphNN: a federated learning system and benchmark for graph neural networks. arXiv preprint arXiv:2104.07145 (2021)
Kairouz, P., et al.: Advances and open problems in federated learning. Found. Trends® Mach. Learn. 14(1–2), 1–210 (2021)
Karimi, H., Samavi, R.: Quantifying deep learning model uncertainty in conformal prediction. In: Proceedings of the AAAI Symposium Series, vol. 1, pp. 142–148 (2023)
Lee, G.H., Shin, S.Y.: Federated learning on clinical benchmark data: performance assessment. J. Med. Internet Res. 22(10), e20891 (2020). https://doi.org/10.2196/20891, http://www.jmir.org/2020/10/e20891/
Li, S., Ngai, E., Ye, F., Voigt, T.: Auto-weighted robust federated learning with corrupted data sources. ACM Trans. Intell. Syst. Technol. (TIST) 13(5), 1–20 (2022)
Lu, C., Kalpathy-Cramer, J.: Distribution-free federated learning with conformal predictions. arXiv preprint arXiv:2110.07661 (2021)
Lyu, L., Yu, H., Yang, Q.: Threats to federated learning: a survey. arXiv preprint arXiv:2003.02133 (2020)
Nguyen, H.T., Sehwag, V., Hosseinalipour, S., Brinton, C.G., Chiang, M., Poor, H.V.: Fast-convergent federated learning. IEEE J. Sel. Areas Commun. 39(1), 201–218 (2020)
Nilsson, A., Smith, S., Ulm, G., Gustavsson, E., Jirstrand, M.: A performance evaluation of federated learning algorithms. In: Proceedings of the Second Workshop on Distributed Infrastructures for Deep Learning, pp. 1–8 (2018)
Park, S., et al.: Feddefender: client-side attack-tolerant federated learning. In: Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 1850–1861 (2023)
Shafer, G., Vovk, V.: A tutorial on conformal prediction. J. Mach. Learn. Res. 9(3) (2008)
Sun, T., Li, D., Wang, B.: Decentralized federated averaging. IEEE Trans. Pattern Anal. Mach. Intell. 45(4), 4289–4301 (2022)
Targ, S., Almeida, D., Lyman, K.: Resnet in resnet: generalizing residual architectures. arXiv preprint arXiv:1603.08029 (2016)
Yanase, J., Triantaphyllou, E.: A systematic survey of computer-aided diagnosis in medicine: past and present developments. Expert Syst. Appl. 138, 112821 (2019)
Yang, J., et al.: Medmnist v2-a large-scale lightweight benchmark for 2D and 3D biomedical image classification. Sci. Data 10(1), 41 (2023)
Zhao, Y., Li, M., Lai, L., Suda, N., Civin, D., Chandra, V.: Federated learning with non-IID data. arXiv preprint arXiv:1806.00582 (2018)
Acknowledgements
This work was carried out with the support of the Coordination for the Improvement of Higher Education Personnel - Brazil (CAPES) - Financial Code 001, the Minas Gerais State Research Support Foundation (FAPEMIG), the National Council for Scientific and Technological Development (CNPq), and the Federal University of Ouro Preto (UFOP/PROPPI).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2025 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Negrão, A., Silva, G., Pedrosa, R., Luz, E., Silva, P. (2025). Adaptive Client-Dropping in Federated Learning: Preserving Data Integrity in Medical Domains. In: Paes, A., Verri, F.A.N. (eds) Intelligent Systems. BRACIS 2024. Lecture Notes in Computer Science(), vol 15412. Springer, Cham. https://doi.org/10.1007/978-3-031-79029-4_8
Download citation
DOI: https://doi.org/10.1007/978-3-031-79029-4_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-79028-7
Online ISBN: 978-3-031-79029-4
eBook Packages: Computer ScienceComputer Science (R0)