
Abstract
With the exponential growth in artificial intelligence, privacy and data acquisition concerns have surged, prompting stricter data protection laws. Federated Learning (FL) addresses these issues by enabling model training without accessing private data, allowing geographically dispersed clients to participate without sharing data. This study deployed an IBM FL platform using Docker containers across two clients and conducted training with the MNIST dataset using the two most common FL strategies: Federated Stochastic Gradient Descent (FedSGD) and Federated Averaging (FedAvg). The results validated the platform’s deployment and assessed the performance of each strategy in terms of model accuracy and client hardware capabilities. Performance metrics, including CPU and RAM usage, network traffic, and model accuracy, were collected. Despite the higher resource demands, both strategies achieved satisfactory model accuracy, with FedAvg showing slightly better efficiency for the small-scale deployment. The results emphasize the potential of FL for predictive maintenance in industrial applications, enabling decentralized data utilization while ensuring data privacy and security.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others


1 Introduction
Traditional machine learning methods typically rely on centralized datasets to train models. However, this centralized approach carries significant risks, especially concerning data breaches that could expose all the training data [1, 9]. In response to these concerns, Federated Learning (FL) has emerged as a promising solution. FL enables model training across geographically dispersed clients without the need to share their private data, thereby preserving data privacy and security.
This work is part of an industrial solution to enhance predictive maintenance within production engineering. The project focuses on developing a multi-sensory platform capable of acquiring and transmitting air parameters (e.g., saturation, temperature, and flow speed) from geographically apart industrial air exchange systems. The collected data will be used to train machine learning models to improve predictive maintenance routines.
The primary goal of this study is to deploy an FL platform using Docker container technology to train models and check its functionality by comparing the performance of machine learning models using different FL strategies. The deployment process involves several tasks aimed at installing a pre-developed application into its intended operational environment [5]. After a successful deployment, performance tests are conducted utilizing the usual FL techniques for machine-learning model algorithms and the results are discussed.
2 Federated Learning Overview
As industries grow, more technology is being required and developed. Among those technologies, Federated Learning is proposed as a pioneering approach to some common issues faced in machine learning, such as privacy and data storage. In [7] a review application in industrial engineering is presented.
With the advent of deep learning (DL), the need for data acquisition in several science instances has increased. This is mainly because DL models are usually interpolators, meaning they present the best results when the input is similar to the data used for training models. Therefore, a huge amount of heterogeneous data is required to achieve decent accuracy [16].
In light of this characteristic, Google presented in 2016 the concept of federated learning (FL), which can be described as a machine learning technique to provide decentralized collaborative learning across different nodes [10]. The FL architecture comprises multiple parties and an aggregator agent. Firstly, a global model is generated and sent to each party. Then, the model will be trained in each party with its own data set, meaning each model will have a different result by the end of the process [9].
An update that contains the difference between the base model and the new one is then generated by the parties and sent to the aggregator agent. The agent then merges the updates and creates a new global model sent to each party, and so on [10].
To understand Federated Learning comprehensively, we will explore its key components and methodologies. The following subsections will delve into data distribution methods, training models, and essential algorithms that form the backbone of federated learning.
2.1 Data Distribution
Data can be distributed and used in the FL context in different ways. The conventional way consists of having multiple parties training a model independently, and the data in all parties possess the same features. Such distribution results in the so-called Horizontal Federated Learning (HFL) approach [8].
In contrast to HFL, one can find the Vertical Federated Learning (VFL) which consists of training a model where each party’s data contains different features of the same set of individuals [8]. Essentially, all parties have data related to the same entities but with different features. For example, in a healthcare scenario, one party might have medical records (features) for a set of patients (entities), while another party might have lifestyle information (different features) for the same set of patients.
To summarize, the main difference between HFL and VFL lies in how the training data is distributed among parties. The HFL will focus on training multiple data samples sharing the same features, whereas the VFL will use the same sample but different features [13].
2.2 FL Training Design
From a system perspective, the FL scenarios aim to train machine learning models using disparate data to maintain privacy and overall model performance. It is imperative that data is not moved across parties and not even visualized by the central server. To achieve that, there are mainly two system designs: cross-device and cross-silo [9].
The objective of cross-device FL is minimizing the function F(w), which is defined by Eq. 1 [9]:
In Eq. 1, \(F_k(w)\) is the local objective function for the device k with model weights w. The term \(p_k\) represents the importance given to the contribution of the k device to the global model objective function.
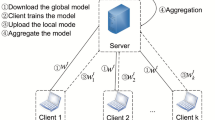
Usually, in the cross-device setting, the parties are user-owned IoT (Internet of Things) instruments such as cell phones, tablets, edge devices, and others [8]. Figure 1 depicts the covered steps of the cross-device learning system whose main steps are [8]:
-
1.
Initially, the model \( G_0 \) (represented as a neural network image in the upper rectangle) is untrained and initialized with random weights. A subset of the available devices is selected at the beginning of each round;
-
2.
After selecting \( k \) devices, the initial weights \( w \) of the global model \( G_n \) are sent to the devices;
-
3.
Each device trains the model on its dataset \( D_k \), resulting in local models \( g_{nk} \);
-
4.
Privacy mechanisms anonymize the local models, which are then sent to the aggregator;
-
5.
The aggregator combines local models using an aggregation algorithm to create a new global model \( G_{n+1} \). The process repeats from Step 1 until a stopping condition, like the maximum number of rounds or model convergence, is met.

Cross-device federated learning system overview. Source: [8]
On the other hand, the main objective of Cross-Silo Federated Learning can be formally described as minimizing the L(W) function described by Eq. 2.
where L(W) is the global loss function for the global model W, i represents the client, j is the data provider (i.e., silos) with the local model \(w_j\) trained from data feature \(x^i_j\) [8]. In the context of cross-silo, the data silos used as parties tend to be of commercial grade, providing a less heterogeneous environment and generally having better computational resources than IoT devices [8]. Figure 2 depicts the chain of events for the cross-silo system whose main steps are [8]:
-
0.
Participants align datasets using techniques like secure multi-party communication or key-sharing, ensuring data alignment by ID. Unmatched data is discarded;
-
1.
A third-party aggregator distributes encryption key pairs to each party and initializes partial models. The last party usually holds the labels, while others have training features;
-
2.
The first party trains on a mini-batch of local data, encrypts the output with homomorphic encryption, and sends it to the next party;
-
3.
The second party performs a forward pass, calculates the loss (since it holds the labels), and sends intermediate outputs to the first party. The loss is sent to the aggregator;
-
4.
Both parties compute partial gradients, add encryption, and send them to the aggregator to prevent data leakage;
-
5.
The aggregator decrypts the gradients, calculates exact gradients using the loss, and sends them back to the parties for model updates. The process repeats from Step 1.

Cross-silo federated learning system overview. Source: [8]
The training procedure for cross-silo FL also happens in rounds but with one significant difference: all silos take part in every round of the training.
Therefore, the choice of targeted devices significantly influences the system selection. In cross-device FL, user-owned IoT devices like cellphones, tablets, and edge devices are common, leading to a diverse range of specifications. Conversely, cross-silo FL typically involves commercial-grade data silos, offering a more uniform environment with superior computational resources compared to IoT devices [8]. Thus, the type of devices used as parties in training will determine the most suitable FL system.
2.3 Federated Learning Algorithms
After establishing the main concepts of FL and its benefits and challenges, it becomes clear that the next step is optimization to address common issues, such as unbalanced data sets and limited communication.
Two algorithms used to contour these challenges are the Federated Stochastic Gradient Descent (FedSDG) and the Federated Averaging (FedAvg) as they are the most common in the FL context [8].
To apply the FedSDG in FL, a C fraction of clients is chosen in each round and the gradient of the loss over all the data held by the clients is computed. Therefore, C refers to the global batch size with \(C = 1\) representing the full batch setup [11].
A typical implementation is with \(C=1\) and a fixed learning rate \(\eta \) [11]. In this scenario, each client k will compute \(g_k = \nabla F_k(w_t)\) (the average gradient on its local data for model \(w_t\)). Then, the central server aggregates these gradients and applies the update \(w_{t+1} \leftarrow w_t - \eta \sum _{k=1}^K \dfrac{n_k}{n} g_k\) since that \(\sum _{k=1}^K \dfrac{n_k}{n} g_k = \nabla f (w_t)\).
An equivalent update is found by \(\forall k, w_{t+1}^k \leftarrow w_t - \eta g_k\) followed by \(w_{t+1} \leftarrow \sum _{k=1}^K \dfrac{n_k}{n} w_{t+1} ^ k\). This means that each client will locally take one step of gradient descent on the current model using its local data. The server then takes a weighted average of the resulting models [11].
Conversely, the Federated Averaging algorithm, FedAvg, is an extension of the FedSDG. The main concept is following the same steps motioned above, but also iterating the local update \(w_k \leftarrow w^k - \eta \nabla F_k(w^k)\) in each client multiple times before the averaging step [11].
Besides the previous hyperparameters C and \(\eta \), the FedAVG will count with two more. B represents the local mini-batch size and E is the number of iterations through the local data before the global model is updated [14].
It is worth noting that both algorithms work with cross-silo and cross-device training design. For this work, cross-silo was used since it is an industry-oriented project.
3 Methodology
This section outlines the sequential steps taken in this study, including the selection of the Federated Learning (FL) library, deployment mechanism, hardware setup, dataset, neural network model, FL parameters, network configuration, and evaluation criteria.
3.1 FL Library
Given the enterprise-oriented nature of the application, which prioritizes privacy, security, and rapid model specification, the IBM FL library was selected for this project. This library was chosen for its robust cryptographic methods, extensive range of FL strategies, and support for various machine learning models. According to [15], from the most notable libraries, only Flower and IBM FL are production-ready libraries.
A comparison between FL platforms (Pysyft, Flower, IBM FL, TFF and FedML) was performed and is available at [17].
3.2 Hardware
The FL platform’s main components include a central server (aggregator) and client devices. Two devices were chosen as silos for this study. Table 1 presents the hardware configurations for each device (silo).
3.3 Dataset
To test the platform, the Modified National Institute of Standards and Technology (MNIST) dataset [3] was used. This dataset contains 28\(\,\times \,\)28 pixel grayscale images of handwritten digits (0 through 9) and corresponding labels. It is a standard benchmark for machine learning algorithms.
3.4 Neural Network Overview
For pattern recognition tasks involving images, Convolutional Neural Networks (CNN) are commonly used [4]. The training model used in the experiment is a Keras CNN classifier, a built-in feature in the FL library. Since this model aims to test the platform, the suggested model in the IBM guide was used. It was configured to possess two convolutional layers with activated ReLu, one pooling layer, one dropout, flatten, and two dense layers to compose the fully-connected layers segment.
3.5 FL Parameters
Two categories of tests were conducted to explore the platform’s capabilities, each repeated five times. The main variable between the tests was the FL strategy used: FedSGD and FedAvg. Table 2 summarizes the training parameters.
3.6 Network Configuration
The platform’s deployment involved creating a private VPN connection to ensure secure data transmission. A WebSocket connection was established between the FL Client App and the Web App backend, along with a Flask connection between the aggregation service and local training services.
3.7 Evaluation Criteria
In terms of model training, threshold metrics were used. A threshold metric quantifies classification prediction errors, meaning that it is a fraction or ratio of a class classification and its expected classification. They are usually used when it is expected to minimize the number of errors [2].
The platform’s performance was evaluated based on hardware metrics (CPU and RAM usage), network traffic, and model training metrics. Threshold metrics, which measure classification prediction errors, were used to assess accuracy, loss, precision, recall, F1 score, and the confusion matrix for each global model.
4 Results
This section addresses the achieved results and discusses how they compare to the expected output from the platform setup. Data was collected from each FL strategy (FedAvg and FedSDG) through a Python script using the psutil and time libraries.
4.1 Resource Usage for FedAvg Strategy
The project’s initial proposition was to use edge devices such as Raspberry Pi devices to perform the role of parties. Therefore, the main concern with the deployment was the resources required to execute a full FL round, given that edge devices are known for their limited hardware capabilities.
Figure 3(a) and Fig. 3(b) show the CPU usage while using the FedAvg strategy from clients IPT-N-0007 and IPT-N-0311 respectively. Each CPU presents the same 20-peak behavior, indicating that model training occurred as expected, with each peak representing one training round.

(a) CPU usage from device IPT-N-0007 in FedAvg. (b) CPU usage from device IPT-N-0311 in FedAvg.
Figures 4(a) and 4(b) show the RAM usage for both devices during the experiment. The scale indicates that device IPT-N-0311 uses almost 600 MB/s more RAM than IPT-N-0007, likely due to having more available memory. This may jeopardize using edge devices as parties due to their limited RAM resources.

(a) RAM usage from device IPT-N-0007 in FedAvg. (b) RAM usage from device IPT-N-0311 in FedAvg.
The next criterion to analyze is the network traffic from both parties. Figure 5(a) and 5(b) depicts both devices network traffic. Since the training procedure encloses receiving and sending the model parameters, peak patterns like CPU usage are also expected.

(a) Network traffic from device IPT-N-0007 in FedAvg. (b) Network traffic from device IPT-N-0311 in FedAvg.
Both figures show a very distinctive exponential-shaped curve from the network traffic. That can happen due to a phenomenon entitled communication overhead.Footnote 1 After every round, the model gets more accurate, which means that some parameters will no longer be altered. Therefore, the size of the exchanged communication keeps getting smaller after every round.
4.2 Resource Usage for FedSDG Strategy
The same analysis was conducted for the FedSDG strategy. Figure 6 show the CPU usage for both parties.

(a) CPU usage from device IPT-N-0007 in FedSDG. (b) CPU usage from device IPT-N-0311 in FedSDG.
The presented behavior is almost identical to the one observed while using the FedAvg strategy. However, since the FedAvg algorithm is a variation of the FedSDG, a similar behavior was expected.
RAM usage in the experiment has also been tracked and is shown in Fig. 7 from devices IPT-N-0311 and IPT-N-0007 respectively. Once again, the observed behavior is similar to the one observed within the FedAvg strategy.

(a) RAM usage from device IPT-N-0007 in FedSDG. (b) RAM usage from device IPT-N-0311 in FedSDG.
Finally, the network traffic is analyzed and the results are shown in Fig. 8(a) and 8(b) for both IPT-N-0311 and IPT-N-0007 parties respectively.

(a) Network traffic from device IPT-N-0007 in FedSDG. (b) Network traffic from device IPT-N-0311 in FedSDG.
4.3 Training Results for FedAvg
The training results of the 5 experiments for FedAvg is presented in Table 3 and a confusion matrix is depicted in Fig. 9.
The F1 Score for all five experiments was above 0.87, indicating a decent classification model. Since the main objective of the experiments was testing the platform, the enhancement of the model performance by using extra layers, for instance, was neglected. The confusion matrix in Fig. 9 shows clearly defined diagonal squares.

Confusion matrix for Experiment 1 using FedAvg

Confusion matrix for Experiment 1 using FedSDG
4.4 Training Results for FedSDG
Table 4 shows the training metrics for the FedSDG strategy, with the corresponding confusion matrix depicted in Fig. 10.
Similar to the FedAvg experiments, the metrics for the FedSDG strategy were within the established thresholds. The confusion matrix in Fig. 10 shows well-defined diagonal squares.
The results evaluated the performance and resource usage of FedAvg and FedSDG Federated Learning strategies using multi-sensory device data. Both strategies achieved high accuracy and F1 scores, indicating effective classification models, with FedAvg showing slightly better resource efficiency. CPU and RAM usage were significant, particularly for devices with lower RAM capacity, and network traffic increased with model accuracy, with FedSDG consuming more bandwidth and taking longer. Scalability issues and data heterogeneity challenges were noted, underscoring the need for careful consideration in practical implementations.
5 Conclusion
This work aimed to deploy a federated learning library into an industrial platform and test its functionalities so that it can later be adapted to train with data acquired and transmitted from multi-sensory devices. To achieve the main objective, the library and several other features such as the dataset itself, were containerized and deployed in each device that worked as a client in the training process, through a Docker container.
Afterwards, the Websocket and Flask connections were established, and minor configurations such as export model function buttons were added. With the deployment process completed, two sets of five different global model training were executed using two different FL strategies, the FedAvg and FedSDG.
Nevertheless, when comparing the strategies hardware-wise, the results have shown that the FedSDG strategy consumes higher network bandwidth, ranging from 30% to almost 70% more, depending on the analyzed experiment. Moreover, the FedSDG took an average of 1,8 more minutes to finish the training procedure than the FedAvg. For a test training with only two parties, two minutes does not impact the final results, however, the full concept of FL is to be able to train on dozens or hundreds of devices, meaning, this network consumption can exceed the available network traffic and impact on several more minutes of delay.
Although the testing was a proof of concept made with only two parties, when extending to dozens of clients, some other challenges may appear such as the heterogeneity of data. According to [12], since each company is physically apart, the way data is sampled can vary for each party, and achieving a good performance model requires similar data sets in all parties.
As the project unfolded, the federated learning approach seemed even more fitting since one company could train a model with data from multiple branches, enhancing the predictive maintenance schedule and mitigating production costs. Moreover, this approach affords the company the ability to retain all data within its storage infrastructure, thereby ensuring the privacy and governance of each client’s data.
Future work could explore scalability testing with larger networks, incorporating more diverse datasets beyond MNIST, and investigating advanced aggregation techniques to improve performance and privacy. Additionally, comparing the IBM FL platform with other frameworks, examining the impact of communication delays, and customizing federated learning algorithms for specific use cases could further refine the platform’s effectiveness and applicability.
Notes
- 1.
Communication overhead is defined as the total number of packets to be transferred or transmitted from one node to another [6].
References
Anthem pays OCR \$16 million in record HIPAA settlement following largest U.S. health data breach in history (2020). https://www.hhs.gov/guidance/document/anthem-pays-ocr-16-million-record-hipaa-settlement-following-largest-us-health-data-breach
Brownlee, J.: Imbalanced classification with Python: better metrics, balance skewed classes, cost-sensitive learning. Mach. Learn. Mast. (2020)
Cohen, G., Afshar, S., Tapson, J., van Schaik, A.: EMNIST: an extension of MNIST to handwritten letters (2017)
Herman, R.L.: Introduction to Partial Differential Equations. R.L. Herman (2015). https://doi.org/10.1007/978-3-030-96896-0, https://math.libretexts.org/Bookshelves/Differential_Equations/Introduction_to_Partial_Differential_Equations_(Herman)/09%3A_Transform_Techniques_in_Physics/9.06%3A_The_Convolution_Operation
Heydarnoori, A., Mavaddat, F.: Reliable deployment of component-based applications into distributed environments. Third International Conference on Information Technology: New Generations (ITNG’06), pp. 52–57 (2006).https://doi.org/10.1109/ITNG.2006.112, https://ieeexplore.ieee.org/document/1611570
Kumar, N., Singh, Y.: Routing Protocols in Wireless Sensor Networks, p. 86–128. IGI Global (2017). https://doi.org/10.4018/978-1-5225-0486-3.ch004, http://dx.doi.org/10.4018/978-1-5225-0486-3.ch004
Li, L., Fan, Y., Tse, M., Lin, K.Y.: A review of applications in federated learning. Comput. Ind. Eng. 149, 106854 (2020). https://doi.org/10.1016/j.cie.2020.106854, https://www.sciencedirect.com/science/article/pii/S0360835220305532
Ludwig, H., Baracaldo, N. (eds.): Federated Learning. Springer (2022). https://doi.org/10.1007/978-3-030-96896-0
Ludwig, H., et al.: IBM federated learning (2020). https://doi.org/10.48550/arXiv.2007.10987
Manias, D.M., Shami, A.: Making a case for federated learning in the internet of vehicles and intelligent transportation systems. IEEE Network 35(3), 88–94 (2021). https://doi.org/10.1109/MNET.011.2000552
McMahan, H.B., Moore, E., Ramage, D., Hampson, S., y Arcas, B.A.: Communication-efficient learning of deep networks from decentralized data (2023). https://doi.org/10.48550/arXiv.1602.05629
Laydner de Melo Rosa, G., Mohanram, P., Gilerson, A., Schmitt, R.H.: Architecture for edge-based predictive maintenance of machines using federated learning and multi sensor platforms (2023). https://doi.org/10.20944/preprints202305.1563.v1
Nguyen, D.C., Ding, M., Pathirana, P.N., Seneviratne, A., Li, J., Vincent Poor, H.: Federated learning for internet of things. IEEE Commun. Surv. Tutor. 23(3), 1622–1658 (2021). https://doi.org/10.1109/COMST.2021.3075439
Nilsson, A., Smith, S., Ulm, G., Gustavsson, E., Jirstrand, M.: A performance evaluation of federated learning algorithms. In: Proceedings of the Second Workshop on Distributed Infrastructures for Deep Learning (2018). https://doi.org/10.1145/3286490.3286559, https://dl.acm.org/doi/pdf/10.1145/3286490.3286559
Saidani, A.: A Systematic Comparison of Federated Machine Learning Libraries. Master’s thesis, Technische Universität München (2023). https://wwwmatthes.in.tum.de/pages/1giyhi2qf7es2/Master-s-Thesis-Ahmed-Saidani
Sarma, K.V., et al.: Federated learning improves site performance in multicenter deep learning without data sharing. J. Am. Med. Inform. Association: JAMIA 28, 1259–1264 (2021)
Schulz, H.H.: Decentralized brilliance: deploying a federated learning platform and evaluating aggregation algorithms (2024). https://repositorio.ufsc.br/handle/123456789/255868
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2025 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Schulz, H.H., Moreira, B.G. (2025). Deployment of IBM Federated Learning Platform and Aggregation Algorithm Comparison: A Case Study Using the MNIST Dataset. In: Paes, A., Verri, F.A.N. (eds) Intelligent Systems. BRACIS 2024. Lecture Notes in Computer Science(), vol 15412. Springer, Cham. https://doi.org/10.1007/978-3-031-79029-4_22
Download citation
DOI: https://doi.org/10.1007/978-3-031-79029-4_22
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-79028-7
Online ISBN: 978-3-031-79029-4
eBook Packages: Computer ScienceComputer Science (R0)