
Abstract
Acute Myeloid Leukemia (AML) is one of the most lethal and aggressive forms of hematological cancer, characterized by the rapid proliferation of immature leukocytes. This disease is diagnosed by highly trained specialists who meticulously analyze microscopic images of blood smears. This work explores the feasibility and effectiveness of using eight Convolutional Neural Network (CNN) architectures to form specialized ensembles capable of accurately differentiating between mature and immature leukocytes. We used voting ensemble techniques and the bagging method to integrate CNNs that achieved the best individual performances. The bagging strategy, explicitly using the EfficientNet B3 CNN, stood out by achieving an accuracy of 96.62%, a precision of 98.11%, and a Kappa index of 92.27% on a dataset of 48,100 blood cell images. This performance enhancement highlights the superior diagnostic capabilities of this approach compared to the individual architectures of CNNs in identifying cell types in the context of AML diagnosis.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others


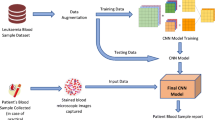
1 Introduction
Blood plays a crucial role in transporting oxygen and nutrients to all organs and comprises three main types of cells: erythrocytes, platelets, and leukocytes. Erythrocytes are responsible for the transport of gases such as oxygen and carbon dioxide; platelets are essential in the blood clotting process [16]; and leukocytes, or white cells, are tasked with defending the organism. Additionally, leukocytes can be classified as mature (fully developed cells) or immature (cells in the development process).
All these cells originate in the bone marrow and are regularly released into the bloodstream. The healthy development of blood cells can be compromised by the disproportionate increase in abnormal blood cells, becoming the primary cause of blood cancer. Leukemia originates when the malignancy of blood precursor cells manifests through their uncontrolled proliferation, primarily affecting leukocytes [27].
Leukemias can be categorized as either acute or chronic. The acute form manifests rapidly, requiring immediate therapeutic intervention, while chronic leukemias progress more slowly, often not requiring immediate treatment after diagnosis. They can also be grouped based on the types of white blood cells they affect: lymphoid or myeloid [15]. Thus, the main types of leukemia are Acute Lymphoblastic Leukemia (ALL), Acute Myeloid Leukemia (AML), Chronic Myeloid Leukemia (CML), and Chronic Lymphocytic Leukemia (CLL).
AML stands out as the most lethal variant among the four leukemia subtypes, with approximately 20,380 new cases and about 11,300 deaths in the United States in 2023, according to data from the National Cancer Institute. The five-year average survival rate is 31.7%Footnote 1. From 2009 to 2019, it was the most prevalent leukemia in Brazil, with 10,554 casesFootnote 2. The disease carries an unfavorable prognosis, and any delay in accurate diagnosis has a severe and negative impact on the patient’s survival capacity.
Currently, no specific screening methods are available for early detection of leukemia before the onset of symptoms. Physicians advise that vulnerable individuals undergo regular medical examinations, including physical assessments and routine blood tests. The detection of an increase in leukocyte count during these tests may indicate the presence of various factors, such as infection, stress, inflammation, or, in some cases, bone marrow disorders, including the possibility of leukemia.
Subsequently, the blood smear examination is conducted by trained technical personnel to carry out morphological analyses, count, and identify anomalies in blood cells. This process prioritizes the detection of specific characteristics associated with each type of leukemia. According to Sadek et al. [19], the diagnostic criterion for AML is established when the count of blasts (immature leukocytes) reaches or exceeds 20%. Figure 1 displays examples of mature and immature leukocytes. Biermann et al. [3] described that mature leukocytes typically exhibit more segmented and ring-shaped nuclei, while immature ones have larger, more rounded, and less segmented nuclei.
Considering the low survival rate, especially among adults diagnosed with AML, and the inherent challenges of manual leukocyte classification for diagnosing AML, it becomes crucial and indispensable to develop tools that utilize computational technology and advances in machine learning methods. These tools aim to assist specialist technicians in validating and supporting the diagnostic process.
Convolutional Neural Networks (CNNs) have demonstrated exceptional performance in image classification. In this study, in addition to analyzing individual networks, we explored various ensemble techniques, including majority voting, weighted voting and bagging. We chose to use distinct architectures, selected for their topological innovations and methods, to optimize image classification. Specifically, we propose an ensemble using the bagging technique with the EfficientNet B3 architecture to classify mature and immature leukocytes in blood smear images aimed at detecting AML. For analysis, we constructed a dataset by combining information from three public datasets, totaling 48,100 images, enhancing our model’s diversity and robustness.

Examples of (a) Mature and (b) Imature Leukocytes.
This paper is organized as follows: Sect. 2 presents related work, citing the most relevant studies. Section 3 introduces the image dataset, the techniques applied, and the evaluation metrics adopted in the study. Section 4 presents the results and discussions, and Sect. 5 discusses the conclusions and future work.
2 Related Work
In recent years, numerous studies in the literature have explored image datasets to classify various types of leukemia, employing Machine Learning (ML) and Deep Learning (DL) techniques. The principal methodologies identified are discussed below.
An example of leukemia classification is found in works such as Ahmed et al. [2] and Aftab et al. [1], which address the four basic types of leukemia: AML, CML, CLL, ALL, in addition to a class representing images without leukemia. On the other hand, there are papers like Claro et al. [5] that focus exclusively on classifying the two types of acute leukemias (AML and ALL), along with a class representing images without leukemia.
Another approach for diagnosing AML involves classifying and counting different types of leukocytes, focusing on immature leukocytes in blood samples. However, this approach still needs to be explored, with few publications addressing binary classification. Some of the works using this approach are discussed below.
Khanam et al. [10] presents an advanced approach for the diagnosis of AML using the ANCOM convolutional neural network, aiming to identify all AML subtypes and healthy leukocytes automatically. The study utilized an image set from Johns Hopkins Hospital, totaling 18,365 images. Random sampling and data augmentation techniques were employed to balance the dataset, achieving an accuracy of 95% for binary classification.
Rahman and Ahmad [18] propose a methodology to precisely detect immature leukocytes using the convolutional neural network architectures AlexNet, ResNet50, DenseNet161, and VGG-16. After training and validation with the optimization of various parameters, the best-performing model was the modified AlexNet, achieving an accuracy of 96.52%, an area under the curve (AUC) of 94.94%, and an F1-score of 97.00%. They utilized a dataset from Johns Hopkins Hospital with 18,365 images, consisting of 3,532 immature leukocytes and 14,833 mature leukocytes.
Dasariraju et al. [7] began their research with binary classification distinguishing between mature and immature leukocytes. Positive results for immature leukocytes were further subdivided into four classes: Erythroblasts, Monoblasts, Promyelocytes, and Myeloblasts. The LMU-DB dataset (University Hospital of Munich), consisting of 15,192 images, was used. The procedure started with the segmentation of the nucleus using Multi-Otsu thresholding. Subsequently, features were extracted, and an SVM-based classifier was applied. The achieved results show an accuracy of 92.99% for binary classification.
The three studies, as presented in Table 1, address the binary classification of leukocytes using different deep-learning techniques and methodologies. Khanam et al. [10] utilize the ANCOM neural network, achieving an accuracy of 95%. Rahman and Ahmad [18] implement transfer learning with a modified AlexNet, achieving an accuracy of 96.52%. Meanwhile, Dasariraju et al. [7] apply an SVM-based classifier, obtaining an accuracy of 92.99%. The main deficiencies include data imbalance, model complexity, lack of comprehensive comparisons with other methodologies, and the use of only a single fold in testing, which may limit the robustness and generalization of the results.
3 Materials and Methods
To conduct a comparative analysis of acute myeloid leukemia (AML) image classifications, we evaluated pre-trained Convolutional Neural Networks. We selected eight distinct architectures: DenseNet201, EfficientNet B3, InceptionV3, ResNet50, ResNet101, VGG16, VGG19, and Xception. This choice was based on a meticulous review of the literature, in which each of these architectures demonstrated remarkable capabilities in image classification tasks. The diversity of the architectures allows for the exploration of a wide range of characteristics of leukocyte images, essential for enhancing the precision of classification between mature and immature cells.
3.1 Proposed Method
After analyzing the results obtained from both individual CNNs and committees, the proposed approach was developed as illustrated in Fig. 2, where we adopted a bagging ensemble technique to improve image classification using the EfficientNet B3 architecture, which achieved the best results in leukocyte classification. Initially, all images are standardized to 300\(\,\times \,\)300 pixels, ensuring consistency in the input data. We used the bootstrap method to train ten distinct models (N = 10), each on randomly selected data subsets with replacement, processed over 100 epochs in batches of 64 images.
We also implemented an early stopping mechanism that monitors validation loss to prevent overfitting. If loss does not improve after a specific number of epochs, training is stopped, and the weights of the best-performing model are saved. This strategy saves training time and ensures that the models are optimally trained without overfitting.
During the testing phase, each model in the ensemble makes independent predictions, and the final classification is determined by averaging these predictions using a decision threshold of 0.5. The final classification distinguishes between mature and immature leukocytes. This approach leverages the diversity of the models in the committee and enhances the robustness of the classification system, ensuring an accurate analysis of leukocyte maturation.

Proposed Method using a Bagging Ensemble.
3.2 Image Dataset
This study combined three datasets, resulting in 48,100 images categorized into mature and immature classes. Table 2 illustrates the combination of images used.
The Johns Hopkins Hospital dataset, as described in Sidhom et al. [20], contains images of blood smears featuring different types of individual leukocytes (.jpg format, 360\(\,\times \,\)360 pixels) from 106 patients diagnosed with AML and Acute Lymphoblastic Leukemia (ALL) across various age groups and genders. Initially, the images were organized by the patient, but they were reorganized by type of leukocyte since the leukocyte identification is present in each patient’s folder. This reorganization process resulted in a total of 18,365 images.
In the dataset from the University Hospital of Munich, as referenced in Matek et al. [14], there are 15,192 images of blood smears with individual leukocytes (.tiff format, 400\(\,\times \,\)400 pixels) from 100 patients diagnosed with AML. These data were collected between 2014 and 2017, covering 13 classes of images.
The dataset from the Central Laboratory of the Clinical Hospital of Barcelona, described by Boldu et al. [4], consists of 14,543 images of individual cells. The dataset is organized into eight distinct groups: neutrophils, eosinophils, basophils, lymphocytes, monocytes, immature granulocytes (promyelocytes, myelocytes, and metamyelocytes), erythroblasts, and platelets or thrombocytes. The images are 360\(\times \)363 pixels in size, in .jpg format, and have been annotated by specialized clinical pathologists.
3.3 Evaluated CNN Architectures
CNNs have been widely employed in the field of machine learning. Thanks to their deep architectures, CNNs can map image features at various levels of abstraction, which has significantly contributed to the development of more accurate medical diagnostic tools. In many cases, CNNs surpass the accuracy of conventional feature extraction methods [21], thus demonstrating their potential and effectiveness in analyzing and interpreting medical images.
CNNs designed for the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) were evaluated. In Kornblith et al. [11], the authors concluded that the better a CNN architecture adapts to the ImageNet dataset, the better it will transfer to other datasets. The architectures evaluated for ensemble formation are indicated in Table 7, which refers to the topological depth of the network, number of parameters, input resolution, and year of publication for each (Table 3).
3.4 Transfer Learning
Transfer Learning is a method where knowledge gained by a neural network on one task is used to improve performance on another related task. This technique reduces the need to re-adjust all the parameters of the CNN from scratch [22].
The proposed method utilizes pre-trained convolutional neural networks to identify mature and immature leukocytes. During development, eight neural networks were evaluated using Shallow Fine-Tuning (SFT), which involves freezing layers from the beginning of the CNN to extract features from the input images and classify them.
The network architecture was first loaded to implement this, excluding the dense layers at the top. Subsequently, the pre-trained convolutional layers were frozen. Custom dense layers were then added to the convolutional layers to tailor the model to the specific needs of binary leukocyte classification. Finally, the model was compiled using the Adam optimizer, the binary cross entropy loss function, and the accuracy metric, preparing it for training.
3.5 Ensembles of Classifiers
The ensemble approach, also known as the ensemble technique, is a method that existed long before the advent of the deep learning paradigm [6]. The theory behind it is pretty simple and is based on the well-known notion of the “wisdom of crowds”: instead of relying on just one model for prediction, a set of multiple (pre-trained) models is created. The results of these models are combined into a final classification through a voting mechanism. The original idea was developed to reduce the variance of classifiers, aiming to achieve better overall performance [8].
Constructing an ensemble of classifiers involves three main phases: generating base classifiers, selecting ensemble members, and defining the decision mechanism [26]. In addition to the individual analysis of Convolutional Neural Networks (CNNs), this study created ensembles using the Voting method, which incorporates both majority and weighted voting. The bagging technique was also employed to enhance the diversity and robustness of the classifiers in the tests.
Voting is a fundamental ensemble technique that aggregates the predictions of several models to improve classification performance. In this approach, each model independently predicts the output, and the final decision is made based on either the majority vote or the weighted vote of all models. In the majority voting scheme, each classifier votes for a specific class, and the class receiving the most votes is selected as the final output. This technique is particularly effective when the individual classifiers are diverse, and their errors are uncorrelated [8]. In the weighted voting scheme, different weights are assigned to each classifier based on their performance. This ensures that more reliable classifiers have a greater influence on the final decision, potentially improving overall accuracy [12].
Bagging is an algorithm framework that trains several different models respectively and then lets all models vote to test the output of samples [17]. As shown in Fig. 3 of Zhang et al. [23], Bagging adopts a sampling with replacement to generate multiple training subsets, which are employed to train classifiers [25]. Each training process is independent, so parallel computing could accelerate the process [9]. Particularly, the training subset in Bagging is selected randomly, meaning different subsets can contain the same data. Additionally, Bagging introduces randomization in the training process of each classifier. After training, all classifiers are combined to reduce the variance in prediction results.

Structure of Bagging classifier. Adapted from Zhang et al. [23].
3.6 Evaluation Metrics
The technique of stratified k-fold cross-validation was used. This approach randomly distributes instances from the dataset into k subsets (or folds), which are mutually exclusive and of approximately equal size while maintaining the same proportion observed in the original dataset. Thus, the CNN model is fitted and tested k times, and in each iteration, a different subset is reserved for evaluation. In contrast, the remaining k-1 subsets are used for fine-tuning the network parameters. This technique is valuable for assessing the model’s performance across different datasets and can provide a more reliable estimate of its generalization ability.
The image dataset was divided into five folds (k = 5), resulting in 20% of the instances comprising the test subset. This subset is not used during the network training but is employed in the final evaluation of the classifiers’ performance. The images in the remaining folds were divided into two subsets: the training subset, used to adjust the network weights based on the loss observed during training, and the validation subset, which comprises 20% of the total training subset. The latter monitors the training process and identifies potential overfitting issues.
Values from the confusion matrix were used to evaluate the methodology’s performance. From these values, five metrics widely recognized in the literature were calculated: accuracy (A), precision (P), recall (R), F1-score (F), and Kappa index (K). The selection of these metrics is justified by their importance in providing a holistic view of the model’s performance, as highlighted by Zhang et al. [24]. These metrics are crucial for comprehensively testing machine learning models, enabling not only the assessment of overall effectiveness (accuracy) but also the precision and the model’s ability to identify all relevant positive instances (recall), balance these measures (F1-score), and measure agreement adjusted for chance (Kappa).
The Kappa index is recommended as an appropriate measure of accuracy because it can adequately represent the confusion matrix. This index considers all elements of the confusion matrix, not just those on the main diagonal, unlike overall classification accuracy, which considers only the main diagonal elements. The Kappa coefficient is calculated using the formula 1:
According to [13], the value of K can be interpreted in the following way: K \(\le 20\%\): Poor; \(20\%\) < K \(\le 40\%\): Fair; \(40\%\) < K \(\le 60\%\): Good; \(60\%\) < K \(\le 80\%\): Very Good; and K > \(80\%\): Excellent.
4 Results and Discussions
From the fine-tuning techniques presented, experiments were conducted to determine the most effective approach for the problem at hand. During the experiments, the selected evaluation metrics were considered. The k-fold cross-validation method was adopted with K equal to 5 to ensure a robust evaluation of the models. Through empirical evaluation, different architectures were tested to optimize the obtained results. All experiments were performed on a computer with an Intel(R) Core(TM) i5 processor at 2.90 GHz, 16 GB of RAM, and an Nvidia Zotac GeForce RTX 3060 12 GB graphics card with 3584 cores.
4.1 Individual Classification
This section presents the individual results obtained with the eight evaluated architectures. The networks were trained for 100 epochs using a batch size of 128 images. A parameter was used to monitor the network’s learning progress, setting a patience value of 15 epochs. If accuracy did not improve after this period, the training was terminated.
Additionally, during the CNNs’ training, the binary cross-entropy cost function and the Adam optimizer were employed. The dense layers at the network’s top were not included, and the pre-trained convolutional layers were frozen. Two custom dense layers were added for the binary classification step: the first composed of 256 neurons with ReLU activation, followed by an output layer with one neuron and sigmoid activation.
The results obtained are described in Table 4, highlighting EfficientNet B3 as the architecture with the best performance, achieving an accuracy of 94.21%, precision of 95.74%, recall of 95.76%, F1-Score of 95.75%, and a Kappa index of 86.69%, which is considered excellent. Including the Squeeze-and-Excitation (SE) attention mechanism in EfficientNet B3 likely contributed significantly to its superior performance. This mechanism enhances the network’s ability to focus on the most relevant features within an image by adaptively recalibrating channel-wise feature responses, leading to more effective feature representation and extraction. The standard deviation analysis showed values close to 0, indicating little variation in results across the folds. These results surpassed those of the other individual architectures, demonstrating the effectiveness of the SE module in improving the network’s accuracy and robustness.
4.2 Ensemble of CNNs
We conducted 120 experiments to evaluate the robustness of various convolutional neural network (CNN) architectures in an ensemble context. We explored combinations of three networks, selected from eight possibilities, using majority and weighted voting methods. Additionally, we implemented the bagging method on all eight networks evaluated to enhance the robustness of the classifications. The consolidated results indicated that the ensemble approach significantly improved performance metrics compared to individual classifiers. However, the bagging strategy stood out, surpassing the ensembles that employed voting methods and achieving superior results.
The analysis of Table 5 reveals that forming ensembles by combining different convolutional neural network (CNN) architectures and using voting methods significantly increased classification metrics. Notably, the ensemble composed of DenseNet 201, EfficientNet B3, and ResNet 50, using majority voting, achieved the best results: an accuracy of 94.93%, a precision rate of 96.21%, a recall of 96.30%, an F1-score of 96.27%, and a Cohen’s Kappa index of 88.35%. These results substantially surpass the metrics achieved by the individual networks, highlighting the superior efficacy of the ensemble approach.
Table 6 illustrates the best results achieved with bagging ensemble, applied to various individual neural networks. Among them, the set that used the EfficientNet B3 network stood out notably, achieving an accuracy of 96.62%, precision of 98.11%, recall of 96.89%, F1-Score of 97.50%, and a Kappa coefficient of 92.27%. The superiority of EfficientNet B3 can be largely attributed to its attention layer, which allows the model to focus on the most relevant features within complex images, significantly enhancing classification precision.
Furthermore, a low standard deviation in the results obtained through bagging must be considered, as it indicates high consistency and reliability of the classification metrics. By combining multiple instances of the same network, the bagging method forms a more stable model that better resists data variability and minimizes the chances of overfitting. This stability is enhanced by the attention layer of EfficientNet B3, which enables each model in the ensemble to concentrate on different nuances of the data efficiently. This combination of bagging and focused attention contributes to stronger generalization and more accurate classification.
Figure 4 illustrates a comparative that synthesizes the top performances from individual, ensemble, and bagging approaches, providing a clear visual representation of how different methodologies enhance the effectiveness of convolutional neural network (CNN) architectures. The chart highlights that the bagging approach using EfficientNet B3 stands out across all metrics, achieving superior accuracy, precision, recall, F1-score, and Kappa coefficient. This method exhibits exceptional stability and minimal variability, underscoring its robustness against data inconsistencies and ability to maintain high performance.

Performance Comparison of CNN Models Across Different Methods.
The data presented in Table 7 provide a clear comparative view of the advancements achieved in the methodologies for classifying leukocyte images. Our research, which implemented a bagging strategy using a combination of three public datasets, achieved an impressive accuracy of 96.62%. This not only surpasses the accuracy levels reported in other studies but also marks a significant milestone by utilizing a considerably larger dataset of 48,100 images.
Unlike previous studies, such as Khanam et al. [10], who used the ANCOM architecture on 18,365 images to achieve a 95% accuracy, or Rahman and Ahmad [18] who modified AlexNet to achieve a slightly higher accuracy of 96.52%, our approach significantly expands the size and diversity of the dataset. The use of machine learning by Dasariraju et al. [7] with Random Forest on the same number of images as the first two studies, but achieving only 92.99% accuracy, further underscores the effectiveness of our method. The substantial increase in the number of images in our study not only contributes to the robustness and generalization of the classification model but also enhances the heterogeneity and diversity of the data.
When considering computational efficiency, it’s clear that despite its higher accuracy, the CNN ensemble naturally requires more computational resources for training and inference. In comparison, EfficientNet B3, the top-performing individual network, provides a more resource-efficient and faster option. The decision between these approaches should weigh the need for diagnostic accuracy against the available resources, especially in clinical environments where speed and efficiency are critical.
5 Conclusion
The implementation of ensemble methods using bagging with the EfficientNet B3 architecture has shown substantial promise in improving the accuracy of leukocyte classification for the early detection of AML. Our study demonstrated significant improvements in performance metrics compared to individual models.
Using a diverse dataset comprising over 48,100 images from three different public image collections provided robustness in the training and validation of the models. This extensive dataset allowed a thorough evaluation of the ensemble’s performance under various image conditions, ensuring the generalization and reliability of our findings.
The promising results obtained in this study suggest that ensemble methods can be a significant step in developing more accurate diagnostic tools in medical imaging. Integrating multiple networks into a bagging ensemble reduced variance and enhanced predictive reliability, which is crucial for clinical applications.
While our research utilizing a bagging strategy with the EfficientNet B3 architecture achieved impressive precision, there are several opportunities for enhancement. Despite the substantial size of our dataset, which includes 48,100 images, further diversification of data sources is essential to improve the model’s robustness and its ability to generalize across different clinical scenarios. Integrating generative networks or Large Vision Models (LVMs) during the transfer learning stage could significantly enhance feature robustness. Additionally, employing advanced ensemble techniques such as boosting and stacking may further refine model accuracy and adaptability. These techniques focus on improving training on challenging instances and synthesizing predictions from diverse models, which could lead to more precise and reliable diagnostic tools in medical imaging.
References
Aftab, M.O., Awan, M.J., Khalid, S., Javed, R., Shabir, H.: Executing spark bigdl for leukemia detection from microscopic images using transfer learning. In: 2021 1st International Conference on Artificial Intelligence and Data Analytics (CAIDA). pp. 216–220. IEEE (2021)
Ahmed, N., Yigit, A., Isik, Z., Alpkocak, A.: Identification of leukemia subtypes from microscopic images using convolutional neural network. Diagnostics 9(3), 104 (2019)
Biermann, H., Pietz, B., Dreier, R., Schmid, K.W., Sorg, C., Sunderkötter, C.: Murine leukocytes with ring-shaped nuclei include granulocytes, monocytes, and their precursors. J. Leukoc. Biol. 65(2), 217–231 (1999)
Boldú, L., Merino, A., Acevedo, A., Molina, A., Rodellar, J.: A deep learning model (alnet) for the diagnosis of acute leukaemia lineage using peripheral blood cell images. Comput. Methods Programs Biomed. 202, 105999 (2021)
Claro, M., Vogado, L., Veras, R., Santana, A., Tavares, J., Santos, J., Machado, V.: Convolution neural network models for acute leukemia diagnosis. In: 2020 International Conference on Systems, Signals and Image Processing (IWSSIP). pp. 63–68. IEEE (2020)
Dasarathy, B.V., Sheela, B.V.: A composite classifier system design: Concepts and methodology. Proc. IEEE 67(5), 708–713 (1979)
Dasariraju, S., Huo, M., McCalla, S.: Detection and classification of immature leukocytes for diagnosis of acute myeloid leukemia using random forest algorithm. Bioengineering 7(4), 120 (2020)
Dietterich, T.G.: Ensemble methods in machine learning. In: International workshop on multiple classifier systems. pp. 1–15. Springer (2000)
Khan, F.H., Saadeh, W.: An eeg-based hypnotic state monitor for patients during general anesthesia. IEEE Transactions on Very Large Scale Integration (VLSI) Systems 29(5), 950–961 (2021)
Khanam, A.S., Khan, M.H., Tabassum, F., Ripa, T.A., Jabid, T., Ali, M.S., Islam, M., Ovi, J.A., Hasan, M.: Classification of acute myeloid leukemia using convolutional neural network (2023)
Kornblith, S., Shlens, J., Le, Q.V.: Do better imagenet models transfer better? In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2661–2671 (2019)
Kuncheva, L.I.: Combining pattern classifiers: methods and algorithms. John Wiley & Sons (2014)
Landis, J.R., Koch, G.G.: The measurement of observer agreement for categorical data. Biometrics 33(1), 159–174 (1977)
Matek, C., Schwarz, S., Spiekermann, K., Marr, C.: Human-level recognition of blast cells in acute myeloid leukaemia with convolutional neural networks. Nature Machine Intelligence 1(11), 538–544 (2019)
Mrozek, K., Heerema, N.A., Bloomfield, C.D.: Cytogenetics in acute leukemia. Blood Rev. 18(2), 115–136 (2004)
Nascimento, M.d.L.P.: A interação entre as células hematológicas durante as suas atividades. Concluído em (2017)
Nguyen, T.T., Pham, X.C., Liew, A.W.C., Pedrycz, W.: Aggregation of classifiers: A justifiable information granularity approach. IEEE Transactions on Cybernetics 49(6), 2168–2177 (2019)
Rahman, J.F., Ahmad, M.: Detection of acute myeloid leukemia from peripheral blood smear images using transfer learning in modified cnn architectures. In: Proceedings of International Conference on Information and Communication Technology for Development: ICICTD 2022. pp. 447–459. Springer (2023)
Sadek, N.A., Abd-eltawab, S.M., Assem, N.M., Hamdy, H.A., EL-sayed, F.M., Ahmad, M.A.R., Elhamammy, R.H.: Prognostic value of absolute lymphocyte count, lymphocyte percentage, serum albumin, aberrant expression of cd7, cd19 and the tumor suppressors (pten and p53) in patients with acute myeloid leukemia. Asian Pacific Journal of Cancer Biology 5(4), 131–140 (2020)
Sidhom, J.W., Siddarthan, I.J., Lai, B.S., Luo, A., Hambley, B.C., Bynum, J., Duffield, A.S., Streiff, M.B., Moliterno, A.R., Imus, P., et al.: Deep learning for diagnosis of acute promyelocytic leukemia via recognition of genomically imprinted morphologic features. NPJ precision oncology 5(1), 38 (2021)
Tajbakhsh, N., Shin, J.Y., Gurudu, S.R., Hurst, R.T., Kendall, C.B., Gotway, M.B., Liang, J.: Convolutional neural networks for medical image analysis: Full training or fine tuning? IEEE Trans. Med. Imaging 35(5), 1299–1312 (2016)
Yosinski, J., Clune, J., Bengio, Y., Lipson, H.: How transferable are features in deep neural networks? Advances in neural information processing systems 27 (2014)
Zhang, H., Zhou, T., Xu, T., Hu, H.: Remote interference discrimination testbed employing ai ensemble algorithms for 6g tdd networks. Sensors 23, 2264 (02 2023)
Zhang, J.M., Harman, M., Ma, L., Liu, Y.: Machine learning testing: Survey, landscapes and horizons. IEEE Trans. Software Eng. 48(1), 1–36 (2020)
Zhang, L., Suganthan, P.N.: Benchmarking ensemble classifiers with novel co-trained kernel ridge regression and random vector functional link ensembles [research frontier]. IEEE Comput. Intell. Mag. 12(4), 61–72 (2017)
Zhou, Z.H.: Ensemble methods: foundations and algorithms (2012)
Zolfaghari, M., Sajedi, H.: A survey on automated detection and classification of acute leukemia and wbcs in microscopic blood cells. Multimedia Tools and Applications 81(5), 6723–6753 (2022)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2025 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Sousa, L.P. et al. (2025). Ensemble of CNNs for Enhanced Leukocyte Classification in Acute Myeloid Leukemia Diagnosis. In: Paes, A., Verri, F.A.N. (eds) Intelligent Systems. BRACIS 2024. Lecture Notes in Computer Science(), vol 15412. Springer, Cham. https://doi.org/10.1007/978-3-031-79029-4_28
Download citation
DOI: https://doi.org/10.1007/978-3-031-79029-4_28
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-79028-7
Online ISBN: 978-3-031-79029-4
eBook Packages: Computer ScienceComputer Science (R0)