
Abstract
This paper investigates the use of Behavior Cloning (BC) for autonomous driving from a bird’s-eye view (BEV) perspective in simulated urban environments. BC uses supervised learning to mimic expert driving behaviors. Previous works have applied BC in the CARLA simulator but did not fully address the challenges of traffic light compliance. Our approach enhances BC by integrating a kernel density estimator to adjust training sample weights based on action density, thereby improving the learning of rare but critical actions such as stopping at red lights and accelerating at green lights, specially in scenarios of scarce number of expert demonstrations. Using BEV inputs, which provide an abstract top-down view of the driving environment, our method simplifies the policy learning process. The trained convolutional neural network (CNN) outputs steering and acceleration actions based on these BEV inputs and additional state variables. Experimental results in the CARLA simulator demonstrate that our weighted BC method significantly improves driving performance, achieving higher route completion compared to standard BC. This weighted approach proved to be crucial in learning correct driving behaviors, particularly in test environments not encountered during training, highlighting its potential for enhancing autonomous vehicle navigation.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others


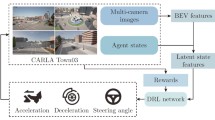
1 Introduction
Autonomous driving has traditionally been implemented using separate modules for perception, planning, and control, organized in a sequential pipeline [13, 15, 16, 21]. However, learning-based approaches have been gaining popularity as they attempt to address the complexities of autonomous driving in various scenarios, whether in simulation or real-world environments.
Most of these learning-based approaches rely on Behavior Cloning (BC), which employs supervised learning on a collection of expert demonstrations gathered offline [2, 3, 6, 7, 19]. For example, a human driver generates a set of input (observations) and corresponding desired output pairs.
Codevilla [6, 7] employed BC for autonomous driving in the CARLA simulator. He collected a large dataset of human driving and augmented it using image processing techniques to train end-to-end policies conditioned on the desired route. Further improvements in BC were introduced in [4], where a large deep ResNet network was used for feature extraction. This approach combined data from cameras, LiDAR, and radar to create comprehensive feature maps. The work also incorporated a probabilistic motion planner to account for uncertainties in the trajectory.
Couto [11] has shown results on behavior cloning on the CARLA simulator, but the agent did not have to respect traffic lights. In this work, we investigate an approach where the agent is able to navigate the city while respecting traffic lights, i.e., breaking when the light is red, and crossing the traffic light when it is green. Only relying on regular BC to train an agent is not enough in a scenario with limited amount of training routes and where the agent needs to break at the red light and accelerate from stillness when light turns to green. To solve that, we employ a kernel density estimator [18] to estimate the actions density from the expert dataset. Then, the training samples are weighted in the BC loss function individually by setting the weight equal to the inverse of the actions’ density. In this way, we can account for the underrepresented actions in the expert set, i.e., those happening at traffic light transitions. This weighting is needed because we are considering only eight routes as training data.
Instead of learning directly from raw camera pixels as in [11, 12], the agent in this work has structured image inputs that are more abstract and meaningful to the navigation task. To decouple feature representation from policy learning [8, 14] has its advantages as potentially easing up the learning task. In our context, this decoupling is accomplished by using a mid-level representation of the vehicle’s raw camera images. For example, Bird’s-Eye View (BEV) representations of the road ahead have been used as mid-level inputs for trajectory generation and motor control networks in [2] and [20], respectively. In BEV representation, the camera scene is projected onto a top-down view, segmenting areas of interest, like vehicle lanes and sidewalks, into different colors [21]. By using BEV as input for the control policy, the learning process can focus on the navigation problem, leveraging a more abstract and simplified view of the road ahead. The policy here is represented by convolutional neural networks, mapping the BEV image to control actuators such as steering and acceleration.
Experimental results in the CARLA simulator demonstrate that our weighted BC method significantly improves driving performance, achieving higher route completion compared to standard BC. This weighted approach proved to be essential in learning correct driving behaviors, particularly in test environments not encountered during training.
In Sect. 2, we present the bird’s-eye view representation employed as input to the convolutional neural network, the behavior cloning loss for the agent, and the kernel density estimation used to generate the weights per sample for the modified loss function. The agent architecture is presented in Sect. 3. Finally, the experiments and conclusions are shown in Sects. 4 and 5.
2 Methods
2.1 Bird’s-Eye View - BEV Representation
The bird’s-eye view of a vehicle represents its position and movement in a top-down coordinate system [2]. The vehicle’s location, heading, and speed are represented by \(p_t\), \(\theta _t\), and \(s_t\) respectively. The top-down view is defined so that the agent’s starting position is always at a fixed point within an image (the center of it). Furthermore, it is represented by a set of images of size \(W \times H\) pixels, at a ground sampling resolution of \(\phi \) meters/pixel. The BEV of the environment moves as the vehicle moves, allowing the agent to see a fixed range of meters in front of it. For instance, the BEV representation for the vehicle whose three frontal cameras are shown in Fig. 1(a) is given in Fig. 1(b), where the desired route, drivable area and lane boundaries are shown as three BEV channels. Besides, other three BEV channels for the traffic lights representing the state of the traffic lights (green or red) at different timesteps are shown in Fig. 1(c). Figure 1(d) shows the integrated six-channel BEV image used as input to the agent.

a) Images from three frontal cameras positioned on the left, center, and right side of the vehicle. These images were taken after the initial interactions of the agent in the CARLA simulation environment. Each camera captures a 256\(\times \)144 RGB image. The corresponding bird’s-eye view channels that our agent uses are shown in (b), (c) and (d), computed at the same moment as shown in (a). b) Three BEV 192\(\times \)192 channels that represent, from left to right, the desired route, drivable area, and lane boundaries. c) BEV’s traffic lights channels at timesteps (–1, –9, –16), i.e., representing the past states of the traffic light channel (grey color is red light off; white color means red ligh on). d) The final image displays all three channels combined in different colors. (Color figure online)
2.2 Behavior Cloning (BC)
Behavior cloning is a supervised learning approach used in imitation learning, where the goal is to learn a policy that mimics the behavior of an expert. In this work, we want to learn a policy for an autonomous vehicle that outputs two actions (acceleration, steering) based on a Bird-Eye-View (BEV) representation of the environment and additional scalar state variables as input. For this reason we need to train a CNN to output these two continuous actions based on input from the BEV and the state variables.
The loss function for behavior cloning is typically based on the difference between the actions predicted by the learned policy and the actions taken by the expert in the training data. Let: \( \pi _{\theta }(s) \) be the policy parameterized by \(\theta \), which maps a state \( s \) to an action \( a \); and \( \mathcal {D} = \{(s_i, a_i)\}_{i=1}^N \) be the dataset of \(N\) state-action pairs collected from the expert, where \( s_i \) is a state and \( a_i \) is the corresponding action taken by the expert.
Although the behavior cloning loss function can be defined as the mean squared error (MSE) between the predicted actions and the expert actions (or the cross-entropy loss if the actions are discrete), in this work, we model a stochastic policy and, for that reason, the policy is represented by a Beta distribution. The Beta distribution is suitable for modeling variables that are bounded within an interval, such as acceleration and steering actions within \([-1, 1]\).
Given the actions \(a_i = (a_{i}^\textrm{acc}, a_{i}^\textrm{steer})\) and the policy \(\pi _{\theta }(s_i) = (\alpha _{i}^\textrm{acc}, \beta _{i}^\textrm{acc}, \alpha _{i}^\textrm{steer},\) \(\beta _{i}^\textrm{steer})\), where \(\alpha \) and \(\beta \) are the shape parameters of the Beta distribution, the loss function will be based on the negative log-likelihood of the Beta distribution.
The probability density function of the Beta distribution [10] is:
where \(B(\alpha , \beta )\) is the Beta function, a normalization constant to ensure that the total probability is 1. To transform actions in \([-1, 1]\) to \([0, 1]\), we use:
The negative log-likelihood loss for the Beta distribution can then be written as:
This loss function accounts for the probabilistic nature of the Beta distribution, ensuring that the model learns to predict parameters (\(\alpha , \beta \)) for the distribution of actions rather than the actions directly. This approach allows for modeling uncertainty and variability in the predicted actions.
2.3 Kernel Density Estimation
A Kernel Density Estimator (KDE) is a non-parametric way to estimate the probability density function (PDF) of a random variable. For each data point in the sample, the kernel function is centered at that point. The KDE is then computed by summing up all these kernel functions and normalizing by the number of data points. Mathematically, the KDE for a point \(x\) is given by:
where \( \hat{f}(x) \) is the estimated density at point \( x \), \( n \) is the number of data points, \( h \) is the bandwidth, \( x_i \) are the data points, and \( K \) is the kernel function.
The Gaussian kernel, often used in KDE, is a type of kernel function that assigns weights to data points based on their distance from the point where the density is being estimated. The Gaussian kernel is defined by the standard normal distribution, and it ensures that closer points have a higher influence on the density estimate than points further away. The mathematical form of the Gaussian kernel \( K \) is:
where \( u \) is the standardized distance between the point where the density is being estimated and the data point, scaled by the bandwidth \( h \).
In this work, the KDE is used to weigh the training samples in the BC loss in (1). By using the inverse of the kernel density estimation of the actions as weights, we give more importance to less frequent actions. This approach can help the model learn better on underrepresented parts of the action space.
The resulting weighted BC loss function can be written as:
where: \( w_i = \frac{1}{\textrm{KDE}(a_i)} \); and \( \textrm{KDE}(a_i) \) is the kernel density estimation evaluated at the action \( a_i \). The KDE is estimated for the actions in the training set. Then the weights \(w_i\) are calculated as the inverse of the KDE for each action.
This approach ensures that the loss function accounts for the density of actions in the training set, giving higher importance to less frequent actions.
3 Agent
3.1 Input Representation
The input \( s \) to the agent’s policy is a six-channel 192\(\,\times \,\)192 image produced by a module in CARLA simulator that has access to the city map. This image represents the mid-level bird’s-eye view of the vehicle’s current position. In this work, the BEV contains three channels, the road, the route and the lane, and also three more channels representing the history of the traffic lights at time steps –16, –9 and –1.
Additionally, the agent receives the current speed of the vehicle and the last values of the policy actuators (previous acceleration and steering). These additional inputs are incorporated further down in the network, specifically in the first fully connected layer.
3.2 Output Representation
The vehicle in CARLA has three actuators: steering \([-1, 1]\), throttle \([0, 1]\), and brake \([0, 1]\). Our agent’s action space is \(\textbf{a} \in [-1, 1]^2\), where the two components correspond to steering and acceleration. Braking is implied when acceleration is negative, ensuring the agent cannot brake and accelerate simultaneously [17].
Instead of using the Gaussian distribution for the policy’s actions, we employ the Beta distribution \(\mathcal {B}(\alpha , \beta )\). The Beta distribution’s bounded support is suitable for real-world applications like autonomous driving, where actions are naturally constrained [17]. This approach avoids the need for clipping or squashing inputs to enforce constraints, allowing explicit computation of the policy loss \(\mathcal {L}_P\).
The Beta distribution also handles extreme driving scenarios, such as sharp turns and sudden braking, effectively. The parameters \(\alpha \) and \(\beta \), which are outputs of the policy neural network \(\pi _\theta \), control the shape of the distribution, enabling the policy to adapt to these critical behaviors.
3.3 Network Architecture
In this work, we train a network architecture, shown in Fig. 2, to learn to control an autonomous vehicle, using steering and acceleration actuators, based on the current BEV and some state variables as inputs. The Convolutionary Neural Network (CNN) maps the BEV into an embedding vector of size 256. Similarly, the scalar state variables are embedded into a vector of size 256 by a standard MLP (multi-layer perceptron layer). Together they form the current representation of the environment the agent faces. This concatenated embedding vector is processed by another MLP to map to the desired action.

Network architecture. The BEV (state) input is processed by a CNN (MLP) to create an image (state) encoding. Both image and state encodings are concatenated and fed into a final MLP that outputs the actions.
Figure 3 shows the detailed network architecture.

Detailed network architecture. The BEV input consists of 6 channels of 192\(\,\times \,\)192 resolution, while the State input correponds to the last executed actions, and the current speed measurements. The final policy output corresponds to the two parameters \(\alpha \) and \(\beta \) of the Beta distribution for both acceleration and steering (thus, the two heads).
4 Experiments
In this section, the proposed BC with weigthed loss function is compared with the standard BC approach for autonomous vehicle navigation tasks in urban scenarios using the CARLA simulator.
4.1 Dataset Generation
The environment and trajectories are sourced from the CARLA Leaderboard evaluation platform [1]. Specifically, the town01 environment from this platform, along with ten predefined trajectories, is used to create the expert dataset.
The expert dataset is generated using a deterministic agent that navigates with a dense point trajectory and a classic PID controller [5]. The dense point trajectory offers numerous points at a high resolution, while a sparse point trajectory has significantly fewer points, giving the agent only a general direction. Therefore, the dense point trajectory is employed to generate the expert’s training data, whereas the sparse point trajectory is used by the agent for broader guidance. Thus, the agent has no access to the dense point trajectory. Besides, the expert breaks at the detection of red traffic lights and accelerates when the light turns back to green.
In Fig. 4, one of the 10 routes executed by the expert to create the labeled training set of demonstrations is illustrated. The line that starts in yellow and ends in red represents the desired trajectory (not visible to the agent as it is). The sparse trajectory appears as yellow dots, generated every 50 m or when the vehicle is about to change its movement (e.g., from straight to turn and vice versa).
The ten trajectories in the expert set were recorded at a rate of 10 Hz, producing 10 observation-action pairs per second. For the shortest route of 1480 samples (average route of 2129 samples), this equates to 2.5 min (3.5 min) of simulated driving. Altogether, the ten trajectories resulted in 21,287 labeled samples (30 GB of uncompressed data). The entire set corresponds to approximately 36 min or 8 km of driving.

(a) The town01 environment of the agent includes one of the routes used by the expert to collect data. This highlighted path measures 740 m, featuring 20 points in the sparse trajectory (indicated by yellow dots) and 762 points in the dense point trajectory (not shown). (b) The town02 is used to evaluate the trained agent in a new environment. (Color figure online)
4.2 Training and Inference
The network shown in Fig. 3 is trained with 8 routes from the expert dataset of town01 environment, where the agent must also respect traffic lights. The first agent (Weighted BC) weighs the samples according to the density of the actions using (3) as loss function, whereas the second agent (BC) considers all actions with same weight, i.e., it removes the higher importance of less frequent actions, using (1) as the conventional BC loss function.
4.3 Evaluation
Although training is offline in town01 environment, we still evaluate both BC and weighted BC agents as their model’s parameters are updated. Every eight training epochs, both agents are evaluated using all ten routes from the same training town (Fig. 5). As four random runs are executed for each agent, the mean and standard deviation of the number of incomplete routes is plot in Fig. 5. One incomplete route means that the vehicle committed an infraction before completing the route. As the total number of routes is ten for town01, both BC and Weighted BC start at 10, the minimum performance. As training evolves, both agents improve the performance by committing less infractions, such as going out of the correct lane or passing a red light, but the Weighted BC agent attains the minimum error faster, i.e., it can complete all routes without any infractions and respecting traffic lights.

Evaluation of both BC policies (weighted and regular) throughout its learning epochs. At every eight training epochs, both BC and Weighted BC agents are evaluated in all ten routes of town01. The vertical axis presents the number of incomplete routes. Four runs were executed for each agent, with mean and standard deviation shown by the solid line and the shaded area, respectively. In the beginning, both agents commit infractions in all routes and, thus, the number of incomplete routes is ten since one infraction ends the route uncompleted. The Weighted BC agent is able to achieve zero infractions by the end of training, unlike the BC agent.
To understand what the action’s density given by KDE and, consequently, the weights in the BC loss function, look like for the first route in town01 (shown in Fig. 4), we record both actuators’s values, acceleration and steering, from our expert as it follows the route as well as the corresponding logarithm of the action’s density for each timestep of the route. These values are plot in Fig. 6, where we can see that different actions will produce different weights in the loss function since some of them are less frequent than others in the expert dataset. The highest action density corresponds to going straight with constant acceleration and zero steering, for instance, between timesteps 470 and 900. The least frequent action happens after a traffic light turns from red to green, which corresponds to a higher, but shorter, acceleration period.

Logarithm of the density of actions, given by KDE, during navigation of a route in town1, shown in Fig. 4. The expert encounters three red traffic lights, during which it breaks (acceleration is \(-1\)), and subsequently accelerates as soon as it turns green. Two left turns and two right turns can be observed by examining the steer actuator of the expert. (Color figure online)
The driving performance for both agents as well as the expert is presented in Table 1. The understanding of the \(\uparrow \) or \(\downarrow \) in the table is as follows. For instance, the lower (\(\downarrow \)) the Red Light Infraction, which is #/Km or the number of infractions per kilometer, the better. In the same vein, the higher the Infraction Penalty (or the Driving score), the better is the performance. The expert has maximum driving score, being able to complete all routes with no red light infraction in both town01 and town02. The number of crossed traffic lights is just a non-performance metric, just counting the times that the vehicle cross them. An equivalent result is achieved by Weighted BC in town01, the training environment, but not by regular BC, which presents a mean driving score of 81. In town02, a test environment, Weighted BC performs significantly better than BC. Videos with the agent controlling the vehicle in CARLA are available at https://sites.google.com/view/weighted-bc, comparing both BC and Weighted BC agents.
5 Conclusion
In this work, we proposed a weighted behavior cloning approach that improves agent learning by giving higher weights to underrepresented actions in the expert training set of driving behaviors. The application consisted of route navigation in two simulated cities in the CARLA realistic simulator for autonomous vehicles, while respecting traffic lights. As the action space of the expert is not uniformly visited, and the expert training dataset is somewhat limited (only 10 routes in town01), a Kernel Density Estimator was employed to infer the action density which, in turn, was converted to a weight per observation-action pair. In our investigated scenario, the weighted loss function for BC proved to be crucial to learn the correct behavior, showing significantly better driving performance than regular BC, specially for the test city town02 not used during training. Future work include extensions to cities with pedestrians and other vehicles and more advanced behavior cloning approaches such as implicit behavioral cloning [9] to account for multimodal action distributions.
References
(2020). https://leaderboard.carla.org/
Bansal, M., Krizhevsky, A., Ogale, A.: Chauffeurnet: learning to drive by imitating the best and synthesizing the worst (2018). https://doi.org/10.48550/ARXIV.1812.03079. https://arxiv.org/abs/1812.03079
Bojarski, M., et al.: End to end learning for self-driving cars (2016). https://doi.org/10.48550/ARXIV.1604.07316. https://arxiv.org/abs/1604.07316
Cai, P., Wang, S., Sun, Y., Liu, M.: Probabilistic end-to-end vehicle navigation in complex dynamic environments with multimodal sensor fusion. IEEE Rob. Autom. Lett. 5(3), 4218–4224 (2020). https://doi.org/10.1109/LRA.2020.2994027
Chen, D., Zhou, B., Koltun, V., Krähenbühl, P.: Learning by cheating (2019)
Codevilla, F., Müller, M., Dosovitskiy, A., López, A.M., Koltun, V.: End-to-end driving via conditional imitation learning. In: 2018 IEEE International Conference on Robotics and Automation (ICRA), pp. 1–9 (2017). https://api.semanticscholar.org/CorpusID:3672301
Codevilla, F., Santana, E., Lopez, A., Gaidon, A.: Exploring the limitations of behavior cloning for autonomous driving. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 9328–9337 (2019). https://doi.org/10.1109/ICCV.2019.00942
Couto, G.C.K., Antonelo, E.A.: Hierarchical generative adversarial imitation learning with mid-level input generation for autonomous driving on urban environments. arXiv preprint arXiv:2302.04823 (2023)
Florence, P., et al.: Implicit behavioral cloning. In: Conference on Robot Learning, pp. 158–168. PMLR (2022)
Gelman, A., Carlin, J.B., Stern, H.S., Rubin, D.B.: Bayesian Data Analysis. Chapman and Hall/CRC, Boca Raton (1995)
Karl Couto, G.C., Antonelo, E.A.: Generative adversarial imitation learning for end-to-end autonomous driving on urban environments. In: 2021 IEEE Symposium Series on Computational Intelligence (SSCI), pp. 1–7 (2021). https://doi.org/10.1109/SSCI50451.2021.9660156
Liang, X., Wang, T., Yang, L., Xing, E.: CIRL: controllable imitative reinforcement learning for vision-based self-driving. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11211, pp. 604–620. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01234-2_36
Montemerlo, M., et al.: Junior: the stanford entry in the urban challenge. J. Field Rob. 25, 569–597 (2008). https://doi.org/10.1002/rob.20258
Ota, K., Jha, D.K., Kanezaki, A.: Training larger networks for deep reinforcement learning. arXiv preprint arXiv:2102.07920 (2021)
Paden, B., Cáp, M., Yong, S.Z., Yershov, D.S., Frazzoli, E.: A survey of motion planning and control techniques for self-driving urban vehicles. IEEE Trans. Intell. Veh. 1, 33–55 (2016)
Parizotto, L.M.S., Antonelo, E.A.: Cone detection with convolutional neural networks for an autonomous formula student race car. In: 26th ABCM International Congress of Mechanical Engineering (COBEM 2021) (2021)
Petrazzini, I.G., Antonelo, E.A.: Proximal policy optimization with continuous bounded action space via the beta distribution. In: 2021 IEEE Symposium Series on Computational Intelligence (SSCI), pp. 1–8. IEEE (2021)
Silverman, B.W.: Density Estimation for Statistics and Data Analysis. Routledge, Abingdon (2018)
Xu, H., Gao, Y., Yu, F., Darrell, T.: End-to-end learning of driving models from large-scale video datasets (2016). https://doi.org/10.48550/ARXIV.1612.01079. https://arxiv.org/abs/1612.01079
Zhang, Z., Liniger, A., Dai, D., Yu, F., Van Gool, L.: End-to-end urban driving by imitating a reinforcement learning coach. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 15202–15212 (2021). https://doi.org/10.1109/ICCV48922.2021.01494
Zhu, H., Yuen, K.V., Mihaylova, L., Leung, H.: Overview of environment perception for intelligent vehicles. IEEE Trans. Intell. Transp. Syst. 18(10), 2584–2601 (2017). https://doi.org/10.1109/TITS.2017.2658662
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Ethics declarations
Disclosure of Interests
The authors have no competing interests to declare that are relevant to the content of this article.
Rights and permissions
Copyright information
© 2025 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Antonelo, E.A., Couto, G.C.K., Möller, C., Fernandes, P.H. (2025). Investigating Behavior Cloning from Few Demonstrations for Autonomous Driving Based on Bird’s-Eye View in Simulated Cities. In: Paes, A., Verri, F.A.N. (eds) Intelligent Systems. BRACIS 2024. Lecture Notes in Computer Science(), vol 15413. Springer, Cham. https://doi.org/10.1007/978-3-031-79032-4_11
Download citation
DOI: https://doi.org/10.1007/978-3-031-79032-4_11
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-79031-7
Online ISBN: 978-3-031-79032-4
eBook Packages: Computer ScienceComputer Science (R0)