
Abstract
This study aims to develop a predictive model for classifying emotions in instrumental music excerpts using machine learning techniques. The methodology involves experiments with three distinct datasets, including a newly created dataset for this research. The models employed include Random Forest, Multi-Layer Perceptron, and Convolutional Neural Network architectures. The experimental results, conducted with a single dataset for testing and validation, were generally positive. However, when attempting to generalize the models using different datasets, a considerable reduction in generalization capability was observed. Despite this, the study presents promising results, indicating that increasing the number of training data can significantly improve the models’ generalization capability.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others

1 Introduction
Music plays a fundamental role in daily life, often used to express emotions and increasingly in therapeutic treatments. It has the ability to evoke a wide range of emotions, acting as a means of communication that transcends linguistic barriers. However, identifying and classifying the emotions evoked by music presents significant challenges due to the variations in individual listeners’ perceptions, resulting in a substantial degree of disagreement among them [9].
This study aims to develop a sentiment analyzer for music using concepts of Artificial Intelligence (AI) and Machine Learning (ML). The analysis of instrumental music, in particular, presents unique challenges, as the absence of lyrics requires emotional interpretation to be derived exclusively from musical elements such as melody, harmony, rhythm, and timbre. This emotional complexity in purely instrumental compositions is often neglected by approaches that focus solely on song lyrics, as noted in previous studies [4, 6].
Specifically, this study seeks to develop a predictive model capable of classifying emotions in instrumental music using advanced machine learning techniques. The methodology adopted involves conducting various experiments with three distinct datasets, including a proprietary dataset created specifically for this research. The machine learning models employed include Random Forest, Multi-Layer Perceptron, and Convolutional Neural Networks, each selected for their distinct capabilities in modeling and data analysis.
The datasets used were labeled based on five primary emotions: Happiness, Sadness, Dramaticism, Romanticism, and Aggressiveness. One of the datasets was developed for exclusive use in this work.
2 Methodology
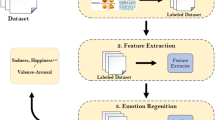
The adopted methodology was structured into fundamental sequential steps, with datasets defined and emotional labels standardized into five categories: Happiness, Sadness, Dramaticness, Romanticism, and Aggressiveness. The process begins with data treatment, followed by a methodological bifurcation depending on whether Deep Learning techniques are used. For approaches involving Deep Learning, spectrograms are created, followed by the application of Transfer Learning and optimization of parameters, culminating in the training, testing, and generalization phases of the model. Alternatively, in the absence of Deep Learning, feature extraction is performed, followed by verification of dataset balance; in case of imbalance, the SMOTE algorithm is applied. Subsequently, the optimal parameters for training are determined, followed by the testing and generalization stages.

AI Development
The general flow of the methodology included the steps presented in Fig. 1.
2.1 Data Acquisition
The first dataset [1] consists of 2500 musical excerpts, each 5 s long. These excerpts are labeled with five distinct emotions: happiness, sadness, romanticism, aggressiveness, and dramaticness, so no adaptation was needed. The dataset is originally organized uniformly, with 500 excerpts for each class.
The second dataset [2] consists of 400 musical excerpts, initially distributed across four genres (rock, classical, pop, and electronic). However, for this study, only 322 excerpts, each 10 s long, were used. This dataset was originally labeled with nine emotions: amazement, solemnity, tenderness, nostalgia, calm, power, activation, tension, and sadness. To adapt these emotions to the context of this work, the Emotion Wheel [7] was used as a reference, mapping each emotion to the closest ones.
The third dataset was developed using a web platform specially designed for this study. This dataset comprises a total of 371 music excerpts, each with a duration of 10 s. The labeling of the excerpts was conducted through evaluations provided by 164 users, ensuring a diversity of opinions and perspectives. During the dataset creation, ties in the labeling were identified. To address these ties impartially and ensure each excerpt maintained a single label, one of the labels was randomly selected.
2.2 Data Processing
In the second audio dataset, where each track had an average of 45 evaluations by different users, several preprocessing steps were necessary to prepare the data for analysis. First, the csv file containing the evaluations was read, and the final annotations were determined by the mode of each music track in the dataset.
Additionally, tracks containing vocals were removed, as lyrics could distort the AI’s understanding of the musical characteristics being analyzed. Thus, the focus remained on working only with the instrumental aspects of the tracks.
All collected data were converted to “.wav” format to ensure uniformity in file type and facilitate subsequent audio processing steps. Audio normalization was also performed, adjusting the volume of each track to avoid significant disparities between different audios. Noise removal was also executed, ensuring the audio was as clean as possible without interference that could affect the subsequent analysis.
2.3 Feature Extraction
In the approach used for Random Forest and Multi-Layer Perceptron techniques, an average calculation strategy for specific features was adopted to ensure equity between the different audio excerpts in the datasets while maintaining code consistency.
To select the best features, a permutation between features extracted from an audio excerpt was performed. All tested features are previously described in the Librosa library documentationFootnote 1. The criterion used for selecting the best features was based on the highest average accuracy in training the three AI models. Thus, a unique set of features was standardized for the trained models.
The adopted approach brought benefits in comparing and interpreting results between different datasets and contributed to maintaining code integrity, allowing efficient implementation without the need for specific changes for each dataset throughout the development. The features considered are described below.
-
RMS Energy: Represents the average energy of the audio signal over time. It is also a practical measure of the energy of vibration.
-
Time and Rhythm: Represented by the beats per minute (BPM) rate. Its objective is to provide information about the speed and rhythm of the music, commonly used for identifying musical genres and analyzing rhythmic patterns. The calculation is based on the root mean square (RMS) value for each frame from the audio samples.
-
Mel Spectrogram: A visual representation of the audio signal spectrum in Mel frequency bands, which is a logarithmic transformation applied to the frequency domain components. The goal is to represent the sound components, giving greater importance to those that most sensitize the human ear [5].
-
Mel-Frequency Cepstral Coefficients (MFCCs): MFCCs are based on extracting the signal’s energy within critical frequency bands. Cepstral measures, based on the Mel scale, indicate the spectrum’s shape, obtaining a response with logarithmic (non-linear) approximation concerning frequency, simulating the human ear [8].
-
Zero-Crossing Rate: The ZCR describes the dominant frequency of the music and is often used to detect silence frames (segments).
-
Spectral Centroid: The spectral centroid characterizes the signal spectrum. It indicates where most of the energy is concentrated in terms of frequency, seeking an average frequency of the signal weighted by the amplitude of each spectral component.
2.4 SMOTE
The Synthetic Minority Over-sampling Technique (SMOTE) is widely used to address class imbalance in datasets by creating synthetic examples for the minority class. SMOTE starts with the random selection of a minority class sample and then selects the k-nearest neighbors of that sample. Among these neighbors, one is randomly chosen, and a synthetic data point is generated between the chosen neighbor and the initial sample. This process is repeated until the dataset is balanced [3].
The application of SMOTE in this work can be observed in Fig. 2. In this figure, it is noted that the class with the fewest labels, “aggressiveness,” after applying the technique, has the same amount of data as the class with the most labels, “happiness.” This balancing is essential to ensure that the machine learning algorithms are not biased in favor of the majority classes, thus improving the model’s ability to generalize to new data.

SMOTE Technique
2.5 Mel Spectrogram
In the approach used for Convolutional Neural Networks (CNNs), the original audio signal was transformed into a mel spectrogram, allowing the model to explore temporal and frequency patterns more intuitively and accurately, similar to image analysis. The images were generated using version 1.0.2 of the Librosa library.
The main difference between the mel spectrogram and the spectrogram is that the frequencies are converted to the Mel scale. The goal is to reduce the amount of correlated information without losing relevant information [5]. The conversion to the Mel scale is given by the equation:
The different types of mel spectrograms generated in this work are presented in Fig. 3. The figure shows five randomly selected audio excerpts, representing the five emotional classes used in this study: happiness, sadness, aggressiveness, romanticism, and dramaticness.

Mel Spectrograms
2.6 Model Training
The Scikit-Learn libraryFootnote 2 was used for model training. The training process included splitting the data for training and validation and choosing hyperparameters, ensuring that the validation data were entirely new to the model.
The data were split into 80% for training and 20% for testing, ensuring the model was tested on unseen data. This split was done randomly to avoid any bias in the resulting sets.
The selection of hyperparameters for each model was based on methods like random search, aiming to explore a wide range of possible combinations efficiently, resulting in a configuration that maximized model quality.
Hyperparameter combinations were performed using cross-validation, where the data were divided into multiple subsets (folds). The model was trained on some of these subsets and tested on the remaining ones, ensuring all data were used for validation at some point. This approach is particularly useful for relatively small datasets, as it allows the model to be evaluated more comprehensively using all available data for both training and validation.
Tables 1, 2, and 3 show the hyperparameters explored for training the Random Forest, Multi-Layer Perceptron, and Convolutional Neural Network models, respectively.
3 Experiments
Given the diversity of data types, combinations between models and datasets were conducted, resulting in a total of nine distinct experiments as described in Table 4.
In each experiment, a search for the best parameters was conducted, and the model was trained with the data previously separated for the training set. Subsequently, the model’s performance was evaluated by analyzing the confusion matrix [10] constructed with the predictions resulting from the data reserved for the test set. Crucial metrics such as precision, recall, and f1-score were considered for this evaluation.
4 Results
For each of the nine experiments described in Sect. 3, the resulting metrics are presented in Table 5. These results can be interpreted as the averages generated from the values of each labeling.
4.1 Prediction on Other Datasets
Similarly to the tests, the prediction sets were distinct from those used in each experiment, ensuring that all data were entirely new to the models, not being used in the training or validation sets. For each experiment, two prediction sets that had already been used in the study were employed.
Table 6 focuses on showing the accuracy of each of the proposed validations.
4.2 Additional Experiments
For cases where the validation and training datasets are the same, they were treated separately. For training and testing, 70% of the dataset was randomly split.
The remaining 30% of the dataset was used for validation. Similar to previous experiments, for each dataset, the three presented models were implemented.
Thus, experiments with identifiers 10 and 11 relate to the RF model, while identifiers 12 and 13 were trained with the MLP model, and the others with CNN. All experiments follow the order 1, 2, and 3 regarding the datasets. The results can be seen in Table 7.
5 Model Performance
Analyzing Table 5, we can observe that the performance of the models varies according to the dataset and the model used. The Multi-Layer Perceptron (MLP) model consistently demonstrated superior performance in most experiments. However, when considering generalization capability, the Convolutional Neural Network (CNN) model proved to be more robust in some cases.
The validation results presented in Table 6 show that the generalization of the models was inferior when tested on different datasets from those on which they were trained. This reinforces the idea that the generalization capability of the models was compromised due to the intrinsic differences between the datasets.
The number of samples had a significant influence on the models’ performance. Models trained with Dataset 1, which has a larger number of samples (2500), consistently outperformed those trained with Datasets 2 and 3, which have fewer samples (322 and 371, respectively). This result suggests that increasing the amount of available data can improve the models’ generalization capability.
The results of additional experiments, where the datasets were split into 70% for training and 30% for validation, corroborate this observation. Models trained with Dataset 1 performed better in validation compared to those trained with the other datasets.
Differences in the properties of the datasets, such as the source of annotation and the intrinsic variability of the data, also affected the models’ performance. The discrepancy in validation results suggests that models trained on a specific dataset may not be applicable to other datasets with different characteristics. This highlights the importance of using a diverse and comprehensive dataset for training.
6 Conclusion
This study aimed to develop a predictive model capable of classifying emotions in excerpts of instrumental music using machine learning techniques. The adopted methodology involved conducting experiments with three distinct datasets, including one created specifically for this research. The models used were Random Forest, Multi-Layer Perceptron, and Convolutional Neural Network.
The experimental results were generally positive when validated with a single dataset for testing and validation. However, there was a considerable reduction in the models’ generalization capability when using datasets different from the original ones. This indicates the need for improvements to increase the models’ generalization and robustness.
The results indicate that, although machine learning models can capture useful patterns to predict emotions in musical excerpts, there is a clear need for improvements. Increasing the diversity and comprehensiveness of the training datasets, as well as applying more advanced preprocessing and feature engineering techniques, are essential steps for future research in this area.
In summary, this work presents promising results and points to directions for future improvements, indicating that increasing the amount of training data and using more advanced techniques can significantly improve the generalization capability of machine learning models in classifying emotions in instrumental music.
Notes
References
akhmedsakip: music-berkeley-emotions. https://huggingface.co/datasets/akhmedsakip/music-berkeley-emotions
Aljanaki, A., Wiering, F., Veltkamp, R.C.: Studying emotion induced by music through a crowdsourcing game. Inf. Process. Manag. 52(1), 115–128 (2016). https://doi.org/10.1016/j.ipm.2015.03.004, https://www.sciencedirect.com/science/article/pii/S0306457315000424, Emotion and Sentiment in Social and Expressive Media
Apostolopoulos, I.D.: Investigating the synthetic minority class oversampling technique (SMOTE) on an imbalanced cardiovascular disease (CVD) dataset (2020)
Du, J.: Sentiment analysis and lyrics theme recognition of music lyrics based on natural language processing. vol. 20 (2024). http://journal.esrgroups.org/index.php/jes/article/view/2040
Lacerda, T.B., Miranda, P., Câmara, A., Furtado, A.P.C.: Deep learning and mel-spectrograms for physical violence detection in audio. In: Anais do XVIII Encontro Nacional de Inteligência Artificial e Computacional, pp. 268–279. SBC (2021)
Malheiro, R., Panda, R., Gomes, P., Paiva, R.P.: Classification and regression of music lyrics: Emotionally-significant features. In: International Conference on Knowledge Discovery and Information Retrieval. vol. 2, pp. 45–55. SciTePress (2016)
Plutchik, R.: Emotions and life: Perspectives from psychology, biology, and evolution. American Psychological Association (2003)
Rahmani, A.M., et al.: Enhanced classification of heart sounds using mel frequency cepstral coefficients: A comparative study of single and ensemble classifier strategies (2024)
Schmidt, E.M., Scott, J.J., Kim, Y.E.: Feature learning in dynamic environments: Modeling the acoustic structure of musical emotion. In: ISMIR, pp. 325–330 (2012)
Ting, K.M.: Confusion Matrix, p. 209. Springer US, Boston, MA (2010). https://doi.org/10.1007/978-0-387-30164-8_157
Acknowledgements
We would like to express our sincere gratitude to the tools and libraries used for data analysis and model development. We also acknowledge the valuable assistance of ChatGPT, which was used as a support tool for the initial review of this manuscript. We take full responsibility for the content presented, including the verification of originality and text accuracy. This work has been supported by the FAPERJ (260003/015313/2021).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2025 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Alves, C.F., Mozart, T.G., Kowada, L.A.B. (2025). Emotion Recognition in Instrumental Music Using AI. In: Paes, A., Verri, F.A.N. (eds) Intelligent Systems. BRACIS 2024. Lecture Notes in Computer Science(), vol 15414. Springer, Cham. https://doi.org/10.1007/978-3-031-79035-5_14
Download citation
DOI: https://doi.org/10.1007/978-3-031-79035-5_14
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-79034-8
Online ISBN: 978-3-031-79035-5
eBook Packages: Computer ScienceComputer Science (R0)