
Abstract
The increasing geospatial data availability has enabled extensive urban mobility studies. However, some tasks require point-of-interest labels, which are missing or inaccurate on public datasets. In this context, the existing solutions fail to utilize different types of convolutional filters regarding graph neural networks, thereby hindering their performance in labeling place categories. To address these shortcomings, this work proposes a new model to annotate points of interest semantically characterized by a hybrid architecture that uses a spatial and spectral filter integrated with a self-attention mechanism. Our results demonstrate an improvement of up to 25.05% in F1-Score compared to three state-of-the-art models across three different datasets.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others


1 Introduction
Location-based social networks (LBSNs) capture the intrinsic mobility characteristics of visitation patterns, providing a vast source of data. Thereby, the availability of such amount of data contributes to broad research topics towards understanding human routine and preferences through mobility such as place recommendation [11], inferring the next place that the user tends to visit [3], learning urban region representations [24], and describe urban functional zones [12]. These studies rely on place categories, e.g., shopping, food, or nightlife, distinguishing a space or a mobility trajectory semantically, thus supplying relevant information to accurately accomplish the desired task.
Nowadays, there are various LBSNs data sources available, such as Yelp, Foursquare, and Gowalla. The first source possesses reviews of geolocated business places, while Foursquare and Gowalla characterize the interactions, i.e., visits also called check-ins, between places and humans. However, these data sources frequently have missing features, and incorrect or inconsistent labels, e.g., a place can be a restaurant in Foursquare and have another label in Yelp [20], leading to errors in different domains, such as site selection and urban planning [19]. In addition, there are a number of geolocated datasets from different sources containing only the position (i.e., latitude/longitude) that could be enriched by their semantic categories such as crime events, trajectory data, and geotagged social media data [1]. Therefore, it is necessary to develop methods that can accurately label the points of interests (POIs), a problem also known as semantic venue annotation, since the place category is essential for gaining in-depth knowledge of user displacements [16].
Various approaches have explored different methods to address the semantic venue annotation problem. [19] propose a machine learning model, while [25] leverage spatial representation learning to label the POIs. Additionally, [3] formulated the temporally sorted visits as a graph and applied graph neural networks. Although this model outperforms others, it solely relies on spectral-based convolution, neglecting the benefits of diverse convolution operations available [31].
Based on that, we propose a novel method, called HAVANAFootnote 1 (Hybrid Attentional Graph Convolution for Semantic Venue Annotation) that integrates spatial and spectral convolution to enhance the accuracy of semantic venue annotation. Specifically, our model combines the spatial and spectral convolution, represented respectively by Graph Attention Network (GAT) [23] and Auto-Regressive Moving Average (ARMA) [2], into a hybrid block. Furthermore, the output of this novel block is aggregated using self-attention [22] and a two-layer feedforward network with residual connections [10]. In summary, the contributions of this study, in terms of model architecture, are two-fold:
-
Propose a hybrid spatial-spectral-based convolution.
-
Output aggregation based on a combination of self-attention, feedforward network, and residual connections.
In the experiments, HAVANA outperforms other three state-of-the-art methods by up to 25.05% on the F1-score averaged, 19.9% on the weighted F1-score, and 16.26% on accuracy in three different datasets.
The remainder of this study is organized as follows: Sect. 2 describes the related work. Section 3 presents the fundamental theory related to graph neural networks. Section 4 details the preprocessing and the model proposed. In Sect. 5 the results and the ablation study are discussed. In Sect. 6 the ethical use of location-based services is considered. Finally, in Sect. 7 we present the conclusion and future works.
2 Related Work
In this section, previous works addressing semantic venue annotation have been examined, and their limitations are discussed. The solutions are separated into three domains: classic machine learning models, representation learning, and graph neural networks.
Considering the classical machine learning models, [29] fuse explicit attributes related to user shifting behavior in different time intervals, with implicit attributes that capture the similarities between the places and users. [18] adapt the k nearest neighbors algorithm under the most favorable assumption to ensure the most probable label given mobility records distance between places categories. [19] evaluate the importance of four different attributes – visual, operation (i.e., closing/opening hours), spatial and textual – modeling the problem with XGBoost.
On another view, the representation learning methods assume that similar places have similar latent features, and thus the objective is to project the features to obtain representations that contribute to semantic venue annotation. Hence, HMRM [5] possesses a collaborative component to learn seven mobility-related matrices with non-negative matrix factorization given co-occurrences between time, places, and visits frequencies matrices. Aside from the decomposition, [25] apply dual contrastive learning, assigning a similarity constraint between the context category and the targeted category to the Skip-Gram model.
Similarly, the graph neural network-based methods aim to project the features into latent space, minimizing the distances between similar places, thereby naturally modeling the problem of semantic venue annotation [31]. For instance, [3] propose the PGC-NN that utilizes a multi-view comprising individual and collective mobility matrices as input into a spectral convolution filter ARMA [2] to label the places. Another study introduces the STPA (Spatial-Textual POI Annotation) [30] which merges spatial and textual characteristics. Spatial features are derived from a Delaunay graph and a graph convolutional network [14] while the textual is based on the names of POIs and a Transformer module [22]. For aggregation, attention weights are applied to these features. On the other hand, leveraging the power of multi-modal data, [8] rely on the higher-order networks by modeling the relationship between users’ mobility and places with hypergraph. To accomplish the classification, the study uses a graph convolution network for hypergraphs.
Despite the advances, the application of multiple spectral and spatial convolutional operators in semantic venue annotation remains unexplored. Inspired by performance achieved by hybridization applied in hyperspectral image classification [28], our proposed method introduces a graph hybrid component, addressing different data modalities as specified in [3, 8, 30]. Additionally, to output aggregation, the novel model combines a two-layer feedforward network and a self-attention weight with residual connections to prevent overfitting [10].
3 Preliminaries and Problem Definition
In this section, definitions and theories required to comprehend the model proposed are presented. Specifically, the definition and the usage of check-ins on points of interest, as well as the structure of the graph neural networks are discussed.
3.1 Semantic Venue Annotation
A location-based social network contains check-ins \(C = \{(p_i, t_i)\}\), which are events characterizing a user’s visit to a place \(p_i\) on a timestamp \(t_i\). This place is known as a Point of Interest (POI) \(p = \langle l, cat \rangle \), which is represented by a location l and a category cat. Therefore, each user can be represented as a general graph G(V, E) given his/her temporally ordered events where \(V = \{p_1, p_{i}, \ldots , p_{n}\}\) is a set of POIs visited and \(E = \{e_1, e_{i}, \ldots , e_{m}\}\) is a set of displacements from a source place s to a destination place d at a timestamp, then \(e_i = \langle p_s, p_d, t_i \rangle \). Considering that multi-view features provide a richness and diverse perspective to comprehend the data [26], we propose a multi-view graph hybrid learning with individual and collective mobility components to infer the place categories correctly.
3.2 Hybrid Graph Neural Networks
In the light of multi-view graph learning, we leverage the strengths of graph neural networks to correlate the places and mobility patterns addressing the semantic venue annotation task. Then, this section introduces the theory behind the different convolutions used in the proposed model.
Note that classifying places’ categories is the same as the node classification task. For this reason, nodes and places are used interchangeably. Thus, given G(V, E) the general graph presented in the previous section, each place has a feature vector represented by \(\vec{f}\). Let \(A \in \mathbb {R}^{n \times n}\) the adjacency matrix of graph G and n the length of the set V, it is possible to define the information propagation and the neighborhood feature aggregations using the spatial and spectral convolution operators [31].
The spatial convolution relies on the graph topology, propagating the information through the neighborhood [9]. Although the size of the neighborhood impacts the node representation learning quality, a large neighborhood leads to inefficiency due to time constraints. Therefore, to surpass these problems, GAT [23] use an attention-based aggregation module [22], where \(\vec{f}\) is weighted by its importance to a specific node.
On the other hand, the spectral convolution transforms the adjacency matrix into a Laplacian matrix assuming the advantages of filtering noises using the spectral domain applying spectral filters. These filters operate on eigenvectors of the Laplacian matrix, which is computationally costly. Therefore, some works try to approximate the eigenvectors to alleviate this processing overhaul [7, 14]. In this work, we used the Auto Regressive Moving Average (ARMA) [2] filter since it captures a higher-order neighborhood with fewer parameters compared to the other spectral filters.
Thus, the principles applied by spectral and spatial convolution are different; the first is governed by the structure of the graph, while the latter evaluates the local neighborhood. Then, to harness these two important principles, we combine the ARMA convolution and GAT convolution into one block named hybrid convolution that inputs an adjacency matrix and a feature vector, producing two outputs corresponding to each convolution.
3.3 Adjacencies and Features
The method proposed comprises a two-view adjacency matrices and feature vectors characterizing a multi-view graph learning: (1) an individual component representing the visiting user pattern, (2) a collective component capturing the general mobility pattern. Considering the location-based social network data, we can view the general graph \(G = (V,E)\) from different perspectives, i.e., individual patterns and collective patterns, which provide fine- and coarse-grained information on visitation patterns, respectively.
Regarding the graph neural network modeling, the characteristics are divided into adjacency matrix and feature matrices as discussed above. The individual features are represented by the sets \(\mathcal {A}' = \{A^u, A^u_{wd}, A^u_{we}\} \subset \mathcal {A}\) and \(F' = \{T^u, T^u_{wd}, T^u_{we}, \textit{Dur}^u, \textit{Dis}^u\} \subset F\). Correspondingly, the collective features are represented by the adjacency matrix \(A^f\) and the feature matrix \(T^f\). Considering the multi-view features, the set of adjacency matrix can be defined as \(\mathcal {A} = \mathcal {A}' \cup \{A^f\}\) and the set of feature matrix can be defined as \(F = F' \cup \{T^f\}\).
Regarding the adjacency matrices set \(\mathcal {A}'\), \(A^u \in \mathbb {R}^{\left| P^{u} \right| \times \left| P^{u} \right| }\) represents the adjacency of points of interest categories consecutively visited by a user u, where \(P^{u}\) is the places set. The matrix \(A_{wd}^{u} \in \mathbb {R}^{\left| P^{u} \right| \times \left| P^{u} \right| }\) specifies the adjacency of the categories of POIs visited consecutively during the weekdays, while \(A_{we}^{u} \in \mathbb {R}^{\left| P^{u} \right| \times \left| P^{u} \right| }\) denotes the adjacency of weekends.
With respect to set F, the matrix \(T^{u} \in \mathbb {R}^{\left| P^{u} \right| \times 48}\) describes the temporal individual characteristics, where each value stands for the total number of visits to a POI by a user u in each hour of the day, i.e., 24-time slots for weekdays and 24-time slots for weekends. This matrix captures the global correlations between visits and timestamps. Besides that, we have two other specific matrices for weekdays and weekends, formally described as \(T_{wd}^{u} \in \mathbb {R}^{\left| P^{u} \right| \times 24}\) and \(T_{we}^{u}\in \mathbb {R}^{\left| P^{u} \right| \times 24}\). Furthermore, \(Dur^u \in \mathbb {R}^{\left| P^u \right| \times \left| P^u \right| }\) denotes the median duration of consecutive visits to the POIs \(P^u\). Finally, \( Dis^{u} \in \mathbb {R}^{\left| P^{u} \right| \times \left| P^{u} \right| }\) represents the geodesic distance between consecutively visited POIs by a user u.
Equivalently, the collective features follow a similar definition. The matrix \(A^{f} \in \mathbb {R}^{\left| P \right| \times \left| P \right| }\) describes all the visits to the POIs and the \(T^f \in \mathbb {R}^{\left| P \right| \times 48}\) defines the count of interactions given a time slot, 24-time slots on weekdays and 24-time slots on weekends. Due to the length of the set P, it is not possible to store these features matrices in-memory, thus the Pointwise Mutual Information (PMI) is applied in order to measure the associativity between two points of interest by the co-occurrence, i.e., evaluates the context of the visits to a POI.
4 HAVANA
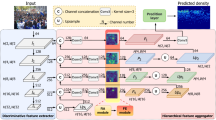
HAVANA is structured into three modules as shown in Fig. 1: individual, collective, and an aggregation module. The individual and collective components associate different levels of mobility information to accurately represent the places’ context. The third module is the aggregation of each block by applying the self-attention weighting with residual connections.

HAVANA comprises three modules: individual, collective, and aggregation. The latter component, which is generally represented in this figure, is responsible for combining the outputs of each hybrid convolutional block.
On the one hand, the individual component comprises five hybrid convolutional blocks \(B_h\), with each block consisting of GAT [23] and ARMA [2] networks. On the other hand, the collective component is composed of a single hybrid block \(B_h\) and a feedforward block \(B_{MLP}\). Each convolution block \(B_h\) takes two inputs: an adjacency matrix \(A_i \in \mathcal {A}\) and a feature matrix \(F_i \in F\), thereby, following the formulations outlined in Sect. 3. Furthermore, for spectral filtering, the Laplacian matrices derived from the set \(\mathcal {A}\) are defined and represented by the set \(\mathcal {L}=\{L^u, L^u_{wd}, L^u_{we}, L^f\}\). Accordingly, the hybrid block produces an output for GAT convolution and another output for ARMA convolution, defined mathematically by Eq. 1.
Regarding the first expression in Eq. 1, which characterizes the spatial convolution, the \(\alpha \) denotes the attention weighting for the graph \(A_i\), given by \(\alpha _{uv}= \exp (e_{uv})/\sum _k{\exp (e_{uk})}\), where \(e_{ij} = LeakyReLU(a^T[Wh_{GAT_i} || Wh_{GAT_j}]))\), and k defines the length of neighborhood of node \(v \in A_i\). Moreover, \(F_i\) is the feature matrix, \(A_i\) is the adjacency matrix, and \(\sigma (\cdot )\) represents the activation function.
In the second expression of Eq. 1, t defines the number of iterations of convolution, which we assume equals 1 to prevent the over-smoothing problem [4]. The \(\tilde{L_i}\) is the normalized Laplacian matrix, defined as \(\tilde{L_i} = D_i^{-1/2}A_iD_i^{-1/2}\), where \(D_i^{-1/2}\) is the normalized diagonal degree matrix. Note that the initial features are equal to the feature matrix, i.e., \(h_{ARMA}^{(0)} = F_i\).
Moreover, the feedforward block \(B_{MLP}\) takes only one input, the matrix \(T^f \in \mathbb {R}^{|P^u| \times 48}\) and its outputs are defined by Eq. 2.
The final module consists of output aggregation of each block that is performed in two stages as illustrated in Fig. 2. The first stage comprises the sum aggregation, graph convolutions concatenation, and the MLP aggregation. The second stage is represented by the self-attention mechanism and the final feedforward layer to output the label probabilities.
Initially, the outputs of the individual and collective components are represented by two distinct sets, as illustrated in Fig. 2. The first set contains the ARMA block outputs, and an output of the feedforward block, represented by Eq. 3. Analogously, the second set includes the GAT output, and the other output of the feedforward block, represented by Eq. 4.
Firstly, to incorporate the information learned in the convolutional blocks, each set \(S_i\) is aggregated according to Eq. 5, where \(b_i\), \(W_i\), \(w_j\) are learnable parameters, and \(Y_{j,i}\) is an embedding from the set \(S_i\), such that \(Y_{1, 1} = \mathbf {h^{(t)}_{ARMA}}(L^u, T^u)\), \(Y_{2, 1} = \mathbf {h_{GAT}}(A^u, T^u)\) and so forth. The goal is to add non-linearities in order to prevent overfitting.
The next step of the first aggregation stage is the concatenation of set \(S_i\) and the sum aggregation \(Z_i\), denoted by \(Y'_i = S_i \Vert Z_i\), where \(\Vert \) represents the concatenation operator.

Aggregation processing flow. Each component output has a residual connection to the final aggregation to prevent overfitting.
Each output aggregated set \(Y'_i\) passes through the second aggregation phase, as represented in Eq. 6. In this phase, the parameters are represented by \(b \in \mathbb {R}^{50}\) and \(W \in \mathbb {R}^{50 \times 50}\) that are learned during the training; the dimensionality of 50 was chosen empirically. This layer augments the features to a higher dimensionality in order to explore the correlations produced by the hybrid blocks.
After augmenting the dimensionality of the hybrid output features with a feedforward layer, we have \(h_{agg}^{(1)}\) and \(h_{agg}^{(2)}\) being the representation of the sets \(Y'_1\) and \(Y'_2\), respectively. Subsequently, the attention mechanism [22] is introduced to importance weighting of joint individual and collective features denoted by \(X' = h_{agg}^{(1)} \Vert h_{agg}^{(2)}\). Therefore, the key, query, and value matrices are defined as \(K = X' W_{x'}^{(1)}\), \(Q = X' W_{x'}^{(2)}\) e \(V = X' W_{x'}^{(3)}\), obtaining the output \(\mathbf {h_{att}} = softmax(\dfrac{QK^T}{\sqrt{d}}V)\).
Finally, for the latter aggregation step, represented by the last MLP block in Fig. 2, the input consists of a skip connection [10] to prevent overfitting, given by the concatenation \(X'' = Y'_1 \Vert Y'_2 \Vert \mathbf {h_{att}}\). Hence, to correlate each feature extracted through the HAVANA learning process, the input vector \(X''\) is the input to the feedforward layer \(\mathbf {h_{out}} = ReLU(b_6 + \mathbf {W_6} X'')\), which represents the final output of the model.
4.1 Loss Function
The cross-entropy loss function was used to measure the error between the observed and predicted values, which relates the vector \(h_{out}\) and the point of interest labels contained in the dataset. Therefore, a softmax is applied for the output feature set as follows: \(\hat{Y} = \frac{\exp (\textbf{h}_{\textbf{out}_{i}})}{\sum _i^D \textbf{h}_{\textbf{out}_{i}}}\), where D is the dimensionality of output features. Hence, the loss function is represented by \(L(Y, \hat{Y}) = -\sum _i p(x_i) \log (\hat{Y})\), where \(p(x_i)\) is the target probability distribution. Note that the distribution is a one-hot encoding, given K categories.
5 Experiments and Results
In this section, the method proposed, HAVANA, is compared to three state-of-the-art models: k-FN [18], STPA – a spatial component of [30] –, and PGC-NN [3]. These baselines were selected because of their methods’ reproducibility and importance since k-FN is based on machine learning while STPA and PGC-NN stand for graph neural networks.
In addition to these methods, we conducted experiments with the non-negative matrix factorization method HMRM [5], which represents the low-rank decomposition matrix theory; however, it runs out of memory with the two bigger datasets. HMRM relies on different matrix correlating places and check-ins leading to high memory usage since it follows the \(O(|C|\times |P|)\), such that C is the check-ins set and P is the set of points of interest. The authors of HMRM do not conduct experiments with this volume of data either. Therefore, we do not include the results for HMRM.
Furthermore, this section addresses the ablation study, aiming at exploring thoroughly each module of the method proposed, and analyzing the performance when removing some of them. Thus, this study focuses on explaining the contribution to the learning of each HAVANA module.
5.1 Data and Test Environment
Considering various location-based social data publicly available, the Gowalla dataset [6] was chosen to compare the HAVANA with state-of-the-art methods. This dataset is widely recognized and has been used in different experiments. We selected three states of the United States that have the most number of check-ins: Florida, California, and Texas, with 859, 984, 2, 249, 070, and 3, 061, 324 records, respectively. Table 1 shows the statistics of the three datasets.
The experiments were conducted on Google Colab, with the following specification: Intel (R) Xeon (R) (8 Cores, 56M cache and 2.2GHz) with 51GB RAM. The HAVANA was developed using the Spektral libraryFootnote 2 and Tensorflow 2.14.
5.2 Results
Figures 3, 4, and 5 present the F1-score, weighted average F1-score and accuracy for the datasets of Florida, California, and Texas, respectively. In general, the results reveal that HAVANA outperforms all metrics presented, highlighting the improvement in the average F1-score. Specifically, it is notable the performance in Florida that presents a 25.05% improvement on average F1-score and 19.90% on weight F1-score.

F1-Score and Accuracy for Florida

F1-Score and Accuracy for California

F1-Score and Accuracy for Texas
The results for each category shown by Table 2 demonstrate that HAVANA surpasses the other methods in almost all scenarios, suggesting that the mechanisms adopted, i.e., attention weights and skip-connections, yielded notable performance on the semantic venue annotation task.
To interpret the results presented by Table 2, it is necessary to note that the points of interest are not balanced, and each state has its own distribution. For example, in Florida there are more check-ins of Food and Shopping, being, respectively, 247,082 and 201,433 check-ins. Similarly to Florida, Food and Shopping are also the most numerous, with 767,056 and 481,600 check-ins for California, while in Texas, these categories correspond to 999,982 and 700,992 check-ins.
The results presented to different states suggest that the method proposed exhibits strong generalizability to different mobility patterns and city organizations, as evidenced by improvements in the analyzed metrics. The consistent performance indicates that HAVANA possesses high adaptability to diverse spatio-temporal city characteristics, including the imbalanced category place distribution, as well as the variability of check-ins and users quantities.
Although the categories present an imbalanced distribution, it is improbable that this difference influenced the results. For example, the Travel category has fewer check-ins than the other classes, being 102,294 in Florida, 215,088 in California, and 182,541 in Texas; nonetheless, this category exhibits a great F1-score. This disparate can be explained due to the activity type that mobile users take in a place. For example, a Shopping location can be similar to another category, such as Food. This behavior is a known problem for semantic venue annotation task [24], e.g., to a user A, a location is a workplace, while to a user B, the same venue is a leisure place.
It is still noteworthy to highlight that STPA, PGC-NN, and k-FN do not present satisfactory results, since they exhibit a high variance on F1-Score within different states. Considering that, this lack of consistency in results suggests a higher sensibility to distinct states and spatio-temporal characteristics. On the other hand, as the proposed model comprises a hybrid convolution and weighting attention mechanism, it demonstrates a higher consistency in different contexts. Then, these performance gains compared to the state-of-the-art model reinforce the efficiency of the novel method.
5.3 Ablation Study
The hybrid convolution and aggregation block modules are the principal components of HAVANA that improve the classification accuracy jointly. To examine the contribution of each component in correctly inferring the label, experiments were conducted on an individual unit. Thus, the test named as M-ARMA is the model with GAT blocks removed, eliminating the hybrid learning. In this case, to carry out the aggregation, \(Y'_1\) behaves as \(X'\). In the same way, for the test M-GAT, \(Y'_2\) behaves as \(X'\). Finally, the test M-NO-AGG represents the model without the aggregation, aplying the softmax function on concatenation \(Y'_3 = \{Y_{1,1}, Y_{2,1}, \ldots , Y_{7,1}, Y_{1,2}, Y_{2,2}, \ldots , Y_{7,2}\}\).
Table 3 exhibits the experiment’s results, highlighting that all the tests decreased its performance on average F1-score compared to the complete model HAVANA. In scenarios such as Florida, the drop of F1-score was about \(28.78\%\) when comparing the HAVANA and the M-NO-AGG. In this context, it is noteworthy the reduction in all average F1-scores, accompanied by an increase in standard deviations. Therefore, these results indicate a higher variability removing the components of HAVANA. Additionally, the components demonstrated an important individual relevance to consistency and performance in the semantic venue annotation task, thus validating the hypothesis of hybrid learning proposed by this study.
6 Ethical Statement
The increasing availability of location-based social network data provides sources to analyze human mobility under an individual perspective [27]. However, it introduces an ethical policy statement due to location privacy issues [13]. That is, given the location of each check-in it is possible to infer various personal attributes such as home and workplace, work hours, the next location visited, and other sensible information [15].
Since our study aims to enhance a method to classify a category place, we used Gowalla anonymized user identifier information, but we maintained the location without masking the latitude and longitude of a collected GPS point. Therefore, when considering using HAVANA in a pipeline with real-world company data, it is fundamental to anonymize the locations with an appropriate method, such as mix-zones [17] or CATS [21].
7 Conclusion and Future Works
In this work, a novel method named HAVANA is formulated with hybrid learning that includes spectral and spatial convolutions to annotate points of interest semantically. The results revealed a higher performance compared to three state-of-the-art models: PGC-NN, STPA, and k-FN. Hence, hybrid models that combine different types of convolution with aggregation blocks can represent a great advance in semantic venue annotation. Additionally, the application of this method in other related tasks of points of interest can also increase the performance, due to the similarity of convolution layers in tasks such as next place to visit and points of interest recommendation.
In the context of future work, it is necessary to enhance the feature engineering, exploring new matrices to represent the data more precisely, specially for collective features such as regional features characterizing the form of the city. This enhancement intends to potentialize the model capacity to consider the aspects of different cities.
Notes
- 1.
The code is available on https://github.com/gegen07/havana.
- 2.
References
Atluri, G., Karpatne, A., Kumar, V.: Spatio-temporal data mining: a survey of problems and methods. ACM Comput. Surv. (CSUR) 4, 1–41 (2018)
Bianchi, F.M., Grattarola, D., Livi, L., Alippi, C.: Graph neural networks with convolutional ARMA filters. IEEE Trans. Pattern Anal. Mach. Intell. 7, 3496–3507 (2022)
Capanema, C.G., de Oliveira, G.S., Silva, F.A., Silva, T.R., Loureiro, A.A.: Combining recurrent and graph neural networks to predict the next place’s category. Ad Hoc Netw. 138103016 (2023)
Chen, D., Lin, Y., Li, W., Li, P., Zhou, J., Sun, X.: Measuring and relieving the over-smoothing problem for graph neural networks from the topological view. In: Proceedings of the AAAI Conference On Artificial Intelligence,vol. 34, no. 04, pp. 3438–3445 (2020)
Chen, M., Zhao, Y., Liu, Y., Yu, X., Zheng, K.: Modeling spatial trajectories with attribute representation learning. IEEE Trans. Knowl. Data Eng. 4, 1902–1914 (2020)
Cho, E., Myers, S.A., Leskovec, J.: Friendship and mobility: user movement in location-based social networks. In: Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 1082–1090, KDD ’11, Association for Computing Machinery (2011)
Defferrard, M., Bresson, X., Vandergheynst, P.: Convolutional neural networks on graphs with fast localized spectral filtering. Adv. Neural Inf. Process. Syst. (2016)
Dubey, M., Srijith, P., Desarkar, M.S.: Multi-view hypergraph convolution network for semantic annotation in LBSNs. In: Proceedings of the 2021 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, pp. 219–227 (2021)
Gilmer, J., Schoenholz, S.S., Riley, P.F., Vinyals, O., Dahl, G.E.: Neural message passing for quantum chemistry. In: International Conference on Machine Learning, pp. 1263–1272, PMLR (2017)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Huang, T., Pan, X., Cai, X., Zhang, Y., Yuan, X.: Learning time slot preferences via mobility tree for next poi recommendation. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 8, pp. 8535–8543 (2024)
Huang, W., Cui, L., Chen, M., Zhang, D., Yao, Y.: Estimating urban functional distributions with semantics preserved poi embedding. Int. J. Geogr. Inf. Sci. 10, 1905–1930 (2022)
Keßler, C., McKenzie, G.: A geoprivacy manifesto. Trans. GIS 1, 3–19 (2018)
Kipf, T.N., Welling, M.: Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907 (2016)
Luca, M., Barlacchi, G., Lepri, B., Pappalardo, L.: A survey on deep learning for human mobility. ACM Comput. Surv. (CSUR) 1, 1–44 (2021)
Ma, J., Li, B., Mostafavi, A.: Characterizing urban lifestyle signatures using motif properties in network of places. Environ. Planning B: Urban Analytics City Sci. 4, 889–903 (2024)
de Mattos, E.P., Domingues, A.C., Silva, F.A., Ramos, H.S., Loureiro, A.A.: Slicing who slices: anonymization quality evaluation on deployment, privacy, and utility in mix-zones. Comput. Netw. 236 110007 (2023)
de Mattos Senefonte, H.C., Silva, T.H., Lüders, R., Delgado, M.R.: Classifying venue categories of unlabeled check-ins using mobility patterns. In: 2019 15th International Conference on Distributed Computing in Sensor Systems (DCOSS), pp. 562–569, IEEE (2019)
Milias, V., Psyllidis, A.: Assessing the influence of point-of-interest features on the classification of place categories. Comput. Environ. Urban Syst. 86, 101597 (2021)
Psyllidis, A., et al.: Points of interest (poi): a commentary on the state of the art, challenges, and prospects for the future. Comput. Urban Sci. 2(1), 20 (2022)
Rao, J., Gao, S., Zhu, S.: Cats: conditional adversarial trajectory synthesis for privacy-preserving trajectory data publication using deep learning approaches. Int. J. Geogr. Inf. Sci. 12, 2538–2574 (2023)
Vaswani, A., et al.: Attention is all you need. Adv. Neural Inf. Process. Syst. (2017)
Veličković, P., Cucurull, G., Casanova, A., Romero, A., Liò, P., Bengio, Y.: Graph attention networks (2018)
Wang, H., Li, Z.: Region representation learning via mobility flow. In: Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, pp. 237–246 (2017)
Xu, H., Xu, R., Chen, M., Liu, Y., Yu, X.: CAVE-SC: Inferring categories for venues using check-ins. Inf. Sci. 611, 159–172 (2022)
Yan, X., Hu, S., Mao, Y., Ye, Y., Yu, H.: Deep multi-view learning methods: a review. Neurocomputing 448 , 106–129 (2021)
Yang, Y., Pentland, A., Moro, E.: Identifying latent activity behaviors and lifestyles using mobility data to describe urban dynamics. EPJ Data Sci. 12(1), 15 (2023)
Yao, D., et al.: Deep hybrid: Multi-graph neural network collaboration for hyperspectral image classification. Defence Technol. 23, 164–176 (2023). ISSN 2214-9147
Ye, M., Shou, D., Lee, W.C., Yin, P., Janowicz, K.: On the semantic annotation of places in location-based social networks. In: Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 520–528 (2011)
Zhang, D., Xu, R., Huang, W., Zhao, K., Chen, M.: Towards an integrated view of semantic annotation for POIs with spatial and textual information. pp. 2441–2449 (2023)
Zhou, J., Cui, G., Hu, S., Zhang, Z., Yang, C., Liu, Z., Wang, L., Li, C., Sun, M.: Graph neural networks: a review of methods and applications. AI open 1 57–81 (2020)
Aknowledgements
The authors are thankful for the support of Manna Team, Softex, CNPq (Number 421548/2022-3) and Fapemig.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2025 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
dos Santos, G.B., Silva, P.H.C., Silva, F.A., Silva, T.R.M.B., Aylon, L.B.R. (2025). HAVANA: Hybrid Attentional Graph Convolutional Network Semantic Venue Annotation Model. In: Paes, A., Verri, F.A.N. (eds) Intelligent Systems. BRACIS 2024. Lecture Notes in Computer Science(), vol 15414. Springer, Cham. https://doi.org/10.1007/978-3-031-79035-5_20
Download citation
DOI: https://doi.org/10.1007/978-3-031-79035-5_20
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-79034-8
Online ISBN: 978-3-031-79035-5
eBook Packages: Computer ScienceComputer Science (R0)