
Abstract
Portfolio optimization is a task in which an agent constantly rebalances a predefined portfolio of assets in order to mitigate losses and maximize profits. A very effective way to solve this task is using a reinforcement learning agent that learns an optimal investment strategy by interacting with the environment, but due to the current lack of open source tools to accelerate the development of such an agent, its implementation is quite difficult. Therefore, to reduce this obstacle, this paper introduces RLPortfolio, a Python library which provides the necessary tools to develop, train and evaluate reinforcement learning agents whose function is to optimize financial portfolios over time. The library contains a simulation environment that implements the state-of-the-art mathematical formulation of the portfolio optimization task, a policy gradient algorithm developed specifically to train agents to solve this task and four state-of-the-art deep neural network architectures that can be used as the agent’s action policy. This paper also demonstrates the results of an agent trained with RLPortfolio to optimize a financial portfolio composed of ten high-volume stocks from the Brazilian market, proving the reliability of the solutions contained in the library while also showing that it produces agents that perform better than classical approaches.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others


1 Introduction
Worldwide, numerous investors and financial institutions manage portfolios containing diverse assets that total over 100 trillion dollars [14]. In order to maximize profits, managers are constantly changing the amount invested in each component of the portfolio in a process called portfolio optimization. Consequently, the most favorable optimization generates an investment strategy that increases the future value of a portfolio and/or mitigates its risk.
Recently, with the introduction of algorithmic trading, several machine learning (ML) techniques have been utilized in order to create an agent that automatically optimizes a financial portfolio and, among them, reinforcement learning (RL) [31] approaches have shown to be extremely effective [4]. In the RL approach, an agent learns an optimal behavior by trial and error while interacting with a trading environment and receiving positive or negative rewards that are, respectively, proportional to the profits achieved and losses incurred. Those rewards are, then, utilized by training algorithms to maximize the expected future rewards of the agent, consequently maximizing the expected profit of the investment strategy. RL techniques are, thus, fundamentally suitable to the portfolio optimization task.
Despite its suitability, there are few libraries that developers and researchers can use to design, implement, train and test the performance of portfolio optimization agents with reinforcement learning considering the state-of-the-art formulation of the problem and using novel deep learning and mathematical frameworks. To address the lack of available tools, this paper contributes RLPortfolioFootnote 1, a Python library designed to facilitate the development of portfolio optimization systems using reinforcement learning. RLPortfolio offers a comprehensive suite of features, including:
-
A cutting-edge policy gradient training algorithm [12];
-
Four state-of-the-art neural network policy architectures [12, 25, 26];
-
A training environment that simulates market dynamics over time [3].
The library is open-source and leverages modern tools such as Pandas [32], PyTorch [22], and Gymnasium [33], ensuring seamless integration with other machine learning frameworks.
The remainder of this article is organized as follows. Section 2 describes the research area, its achievements and gaps. Section 3 introduces the mathematical formulation of the portfolio optimization problem and Sect. 4 describes how reinforcement learning can be applied to solve it. Section 5 introduces the developed library and its features while Sect. 6 describes the results of the application of RLPortfolio in the Brazilian market. Finally, Sect. 7 concludes this paper.
2 Related Work
Over the years, many methods have been created to generate a strategy that makes profit in the portfolio optimization task. Recently, with the advent of artificial intelligence, many of those methods have successfully applied the predictive capabilities of several machine learning techniques [9, 10, 13] so that the future values of assets are forecasted and considered in the decision-making. In this context, reinforcement learning approaches to optimize a portfolio have gained popularity specially after Jiang et al. [12] introduced a mathematical formulation of the problem, described a policy gradient training algorithm and achieved great results using a convolutional neural network named EIIE (Ensemble of Identical Independent Evaluators).
After Jiang’s work, many papers were able to enhance its framework and perform even better. Liang et al. [17], for example, applied noise to input data so that EIIE could more efficiently generalize its policy of actions. Subsequently, Shi et al. [25] applied ideas inspired by inception convolutional neural networks in order to consider multiple temporal windows in the learning process. Weng et al. [35], on the other hand, made use of xception convolutional neural networks in conjunction with attention gating techniques and Soleymani et al. [28] employed autoencoders to enrich the input data with financial indicators. Recently, the research area is moving towards three main ideas: the use of graph neural networks to model the relationships between assets and their implications in their investment values [26, 29, 30], the modeling of the solution as a multiagent system [18, 20] and the application of transformer-like architectures in the agent policy network [15, 37].
Therefore, it is clear that even at the forefront of the research field, the mathematical formulation and the training algorithm introduced in Jiang’s paper [12] continue to be effectively applied. For that reason, a few open-source implementations of the original framework were developed, such as PGPortfolio [11] and DeepPortfolioManagementReinforcementLearningV2 [2], but they are not currently maintained, which means that they make use of outdated frameworks and are not easy to use. There are, on the other hand, modern environments [5, 6] and frameworks [38] that can be used to develop reinforcement learning models but they don’t implement neither state-of-the-art formulations nor the training algorithm. Recently, however, Costa et al. [3] introduced a simulation that applies Jiang’s formulation and that can be easily used to train reinforcement learning agents, but a modern open-source implementation of the training algorithm for portfolio optimization agents remains, to the best of our knowledge, nonexistent.
3 Mathematical Definition of Portfolio Optimization
The portfolio optimization task is defined as the periodic reallocation of the resources of the portfolio by an automated system in order to increase profits and mitigate losses. The system has initially a fixed amount of cash (or any form of risk-free asset defined by the developer) that can be distributed in the assets of the portfolio: at the beginning of each time step, the system analyzes market data and decides the percentage of resources that will be allocated in each asset. The small intervals of time in which the system is able to rebalance the portfolio are called reallocation periods and the size of a time step is constant and defined in the beginning of the task.
This paper makes use of the mathematical formulation presented in [12], so the following hypotheses are assumed:
-
There is no slippage, so that orders placed are immediately completed at the last price.
-
The system’s buying and selling orders do not impact the market prices.
These hypotheses come from the assumption that the market has high liquidity and trading volume. Therefore, to ensure this formulation is close to real-world, it is advisable to use data from markets with these features.
Considering a portfolio of n assets, the weights vector or portfolio vector \(\vec{W_{t}}\) is a vector of size \(n + 1\) that contains the percentage of resources (or weights) invested in each asset of the portfolio and its remaining cash at time step t. This way, given that \(\vec{W_{t}}(i)\) is the i-th element of \(\vec{W_{t}}\), two constraints must be respected:

It is important to highlight that, in this work, the first value \(\vec{W_{t}}(0)\) of the weights vector contains the weight of the remaining cash (or a risk-free asset).
At each time step t, there is also a price vector \(\vec{P_{t}}\) that contains the current price (or value) of all the assets including the uninvested amount of cash. \(\vec{P_{t}}\) is in the form \([1, \vec{P_{t}}(1), \vec{P_{t}}(2), ..., \vec{P_{t}}(n)]\) because, in this work, the first value is related to the risk-free cash and, since it is used as a reference asset (all the other prices are calculated in relation to this one), its value is always equal to 1.
Since the price of the assets probably change over time, \(\vec{P_{t}}\) and \(\vec{P_{t-1}}\) may be different. So the value of the portfolio \(V_{t}\) and the weights vector \(\vec{W_{t}}\) can change during time step t and thus it is necessary to define \(V_{t}^{f}\) and \(\vec{W_{t}^{f}}\), which represent, respectively, the portfolio value and the weights vector at the end of the time step t. It is possible to calculate the final weights vector using the following equation:
where \(\cdot \) is the dot product of two vectors, \(\odot \) is the element-wise multiplication and \(\oslash \) is the element-wise division.
With those definitions in hand, it is possible to recursively calculate the portfolio value \(V_{t}\) over time through the following equations:
in which \(\mu _{t}\) is the transaction remainder factor (trf) at time step t, a value between 0 and 1 that reduces the portfolio value in order to simulate the effects of brokerage fees considering the reallocation of the portfolio from \(\vec{W_{t-1}^{f}}\) to \(\vec{W_{t}}\). Details about how to calculate \(\mu _{t}\) can be found in [12].
So that the iterative calculation of portfolio values is mathematically well-defined, it is necessary to have an initial state. In this work, it is considered that the time step \(t = 0\) contains the initial values of the simulation: during that step, the portfolio investment only consists of cash and there is no change in the portfolio value. So, given a user-defined initial portfolio value \(V_{0}\), the initial conditions at \(t = 0\) are:
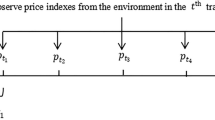
Figure 1 shows a diagram representing the whole process described in this section.

Diagram depicting the portfolio optimization process over time. In the reallocation periods, the action \(\vec{W_{t}}\) performed by the agent and the current portfolio weights \(\vec{W^{f}_{t-1}}\) are used to calculate \(\mu _{t}\), which simulates the effects of the fees in the portfolio value (\(V^{f}_{t-1} \rightarrow V_{t}\)). At the end of every simulation step, the portfolio value and weights are updated (\(V_{t}, \vec{W_{t}} \rightarrow V^{f}_{t}, \vec{W^{f}_{t}}\)) due to variations of asset prices.
Usually, the logarithmic rate of return \(r_{t}\) is used to evaluate the performance of the portfolio rebalancing between two time steps. It is given by
This way, since \(V_{0} = V_{0}^{f}\), it is possible to determine the final portfolio value at any moment,
where T is the number of time steps to be considered.
In the portfolio optimization task, a system tries to determine the optimal sequence of weights vector \([\vec{W_{0}}, \vec{W_{1}}, ..., \vec{W_{T}}]\) that maximizes the final portfolio value \(V_{T}^{f}\).
4 A Reinforcement Learning Solution
One way to optimize a portfolio is to train a reinforcement learning agent. In this type of learning, an agent aims to learn a policy of actions \(\pi \) by continuously interacting with an environment. At each time step t, the environment provides an observation \(O_{t}\) that contains information about the current situation of the environment. This observation is utilized by the agent to define its state \(S_{t}\), which is used as input in the agent’s policy \(\pi \) in order to generate an action \(A_{t}\) to be applied in the environment (the policy can, thus, be seen as a mapping \(\pi : S \rightarrow A\)). When the agent performs an action in the environment, the latter returns a reward \(R_{t}\), a numeric value which is determined based on the outcome of the performed action: actions that yield good outcomes produce higher rewards. The objective of the reinforcement learning is to iteratively generate a policy that maximizes the expected sum of the rewards received by the agent.
In order to apply this approach to the portfolio optimization task, it is necessary to define a policy that can not only handle a continuous state space but also a continuous action space. As stated before, the policy can be seen as a mapping \(\pi : S \rightarrow A\), so it would be necessary to implement a function that maps every possible state value to a specific action, something not computationally viable. Since this issue is present in many real-world tasks, deep reinforcement learning (DRL) [16] solutions were designed to solve it by using neural networks as a function that can manage continuous values and that approximates close ones, generalizing the state and the action space. DRL has achieved remarkable results in many tasks [7, 27] and, for that reason, it is utilized in the portfolio optimization task.
In this work, the agent’s state space, the action space and the reward function are modeled as follows:
-
State space: The agent can utilize any time series that contains historical values related to each asset in the portfolio. The size of this time series t represents the number of historical values that are considered in the state. Therefore, for a portfolio composed of n assets, the time series can be represented as a matrix of sizes (n, t). This matrix representation, however, only represents a single feature and, in the portfolio optimization task, usually multiple features are used in the state representation: Weng et al. [35], for example, shows that the time series of closing, high and low prices of assets are the most important features in an RL agent, but other features such as the time series of indicators and transaction volumes can also be used. This way, the state space is a three-dimensional matrix of sizes (f, n, t), in which f represents the number of features, n denotes the number of assets in the portfolio and t is the size of the time window of the time series. It is important to highlight that, in this work, all the time series used as feature in the state space must have the same time window and, thus, the same number of values. Figure 2 contains a diagram representing how a time series can be used as a feature to build the state of the agent.
-
Action Space: At each time step t, the agent is responsible to provide the weights vector \(\vec{W_{t}}\) to the environment so that it can be used to rebalance the portfolio as explained in Sect. 3. Therefore, the action space is a vector of size \((n+1)\), where n is the number of assets in the portfolio.
-
Reward function: Since the agent’s goal is to maximize the expected sum of rewards received at each time step, the reward function plays a crucial role in defining the learning objective. Consequently, there are numerous potential functions that can be employed. In the context of portfolio optimization, any metric of profit, risk, or financial indicator can be used. In this work, we utilize the logarithmic rate of return, as introduced in Eq. 5, to construct the reward function. This choice trains the agent to maximize profit effectively.

Visual representation of state space highlighting how a specific feature is used to construct the final three-dimensional structure.
5 RLPortfolio: Implementing the RL Solution
Given the lack of open-source libraries that implement the formulations presented in Sect. 3 and the RL solution introduced in Sect. 4, we developed a Python library called RLPortfolio. This library aims to simplify the development of portfolio optimization systems, allowing researchers to focus on new algorithmic and deep learning architectural solutions. Additionally, it enables developers to train an agent with just a few lines of code.
RLPortfolio also aims to provide benchmarks to the research field, implementing a state-of-the-art training algorithm [12] and some notable neural networks as policies [12, 25, 26] to solve the portfolio optimization task.
In order to be reliable, easy to use, and achieve good performance, this project has the following features:
-
The library makes use of recent versions of modern frameworks;
-
The code has the main functionalities tested with unit tests to minimize possible implementation errors;
-
The classes and functions are documented so that the user can understand how to use it;
-
The library is modular so that it can be easily used with other reinforcement learning frameworks;
-
The API is easy-to-use and contains several parameters in order to cover multiple different situations;
-
The project is open source.
The architecture of RLPortfolio consists primarily of three components: a Gymnasium [33] environment implementing all the formulations presented in Sect. 3, a policy gradient algorithm based on [12], and a neural network as a deterministic policy \(\pi : S \rightarrow A\) such as introduced in Sect. 4. As it can be seen in Fig. 3, these three components work together to implement the training loop. The environment is responsible for simulating the effects of the agent action \(A_{t}\), simulate the passage of time and return the appropriate reward \(R_{t}\). The agent is composed of the algorithm and the policy. The algorithm provides the state \(S_{t}\) and the agent’s last action \(A_{t-1}\) to the policy and it is also responsible to calculate the gradients so that the policy can be trained through gradient ascent. The policy, on the other hand, is responsible to choose the best action to be performed based on its inputs. It is important to highlight that by splitting the training logic, the user can replace any of the components by a custom one (including implementations from other libraries).

The three main components of RLPortfolio.
5.1 The Environment
The environment can be any Gymnasium [33] environment which implements the state space, the action space and the reward function introduced in Sect. 4 so that custom environments implementing different mathematical formulations of the portfolio optimization can be used. It is important to note that custom environments must provide the necessary information to the algorithm, therefore it is crucial to read the documentation that accompanies RLPortfolio.
Currently, RLPortfolio contains an environment based on POE [3] that implements the mathematical formulations presented in Sect. 3 and simulates the passage of time and the interactions between the trading agent and the market. POE was chosen as the foundation of this work because it is, for the best of our knowledge, the Gymnasium environment that adheres the best to the mathematical definition of the portfolio optimization task and is built upon modern libraries such as Numpy [8] and Pandas [32]. Additionally, POE is very configurable, so that the user can easily set, for example, the commission fee rate, the normalization method, the features to be considered in calculations, the size of the state time window, etc.
By defining the initial value of the portfolio and inputting a Pandas dataframe containing the time series of the temporal features to be considered, the environment will scroll through time from the initial to the last time of the input data calculating the effects of the agent’s rebalancing on the portfolio. Completely scrolling through all time ranges of the input data defines an episode.
It is important to highlight that the modified environment included in RLPortfolio has some improvements over POE:
-
It contains two methods to calculate the transaction remainder factor \(\mu _{t}\);
-
Traditional loops have been replaced with faster vectorized operations;
-
It is able to return a state with more assets than the portfolio, something useful to graph neural network [36] approaches;
-
Unit tests were created to ensure that the environment is correctly implementing the mathematical formulation introduced in Sect. 3;
-
More effective normalization methods were added;
-
The graphs generated by the original environment were visually improved.
5.2 The Algorithm
There are several reinforcement learning algorithms that can be used to train a RL agent and those algorithms are present in many open-source libraries such as Stable Baselines 3 [23], ElegantRL [19] and Tianshou [34]. Those algorithms can be used with the environment introduced in the previous section but, according to [17], they do not achieve good performance like the policy gradient (PG) one presented in Jiang’s work [12]. For that reason, the algorithm included in RLPortfolio is a modified version of PG.
As the agent interacts with the environment, the PG algorithm for portfolio optimization saves its experiences in the replay buffer ordered in time. Eventually, after the replay buffer saves a certain number of experiences greater than or equal to batch_size, a batch of experiences is sampled in order to calculate the objective function
in which \(T_{1}\) and \(T_{2}\) are, respectively, the first and the last time step of the sampled experiences ordered in time, \(\mu _{t}\) is the transaction remainder factor, \(\vec{W_{t}}\) is the agent’s performed action and \(\vec{P_{t}}\) is the vector containing the prices of the assets. Note that this objective function is analogous to the logarithm of the rate of the value of the portfolio from steps \(T_{1}\) to \(T_{2}\), therefore the agent will try to maximize profits.
Additionally, since this work considers that batches with overlapping temporal data (for example, batches \([T_{1}, T_{2}]\) and \([T_{1} + 1, T_{2} + 1]\)) are different representations of the trading process, at each time step t the algorithm samples a batch of sequential data starting at \(T_{1} < t - batch\_size\) through a geometrical distribution:
in which \(\beta \in (0, 1]\) is the probability of selecting the most recent batch. The bigger the value of \(\beta \), the more recent batches will be sampled.
5.3 The Policy
Finally, the last component of the training routine is the policy, which must be a neural network whose inputs are the state of the agent and its last performed action. With those two values, the policy must output the next action of the agent (\(\vec{W_{t}} = \phi (\vec{s_{t}}, \vec{W_{t-1}})\)). The policy needs to have knowledge about the last action \(W_{t-1}\) to learn effectively how to avoid abrupt rebalancings in the portfolio and, consequently, avoid losses related to commission fees.
In RLPortfolio, the policy can be any PyTorch [22] neural network with those inputs and outputs. But in order to provide some benchmarks to be used in the research area, the library contains four implementations of state-of-the-art policies: the original recursive and convolutional neural networks solution introduced in [12], the multi-scale convolutional solution from [25] that considerably improves the original architecture and the graph neural network approach presented in [26], which is one of the first works implementing graph approaches.
6 Application in the Brazilian Market
In order to demonstrate the performance of RLPortfolio, a small experimentFootnote 2 is done by applying the formulation presented in the Brazilian market. A portfolio with 10 high-volume assets (VALE3, PETR4, ITUB4, BBDC4, BBAS3, RENT3, LREN3, PRIO3, WEGE3, ABEV3) was created and a simple EIIE convolutional agent [12] was trained using the historical daily close, high and low prices of the stocks from 2011/01/01 to 2019/12/31 (2233 trading days). The performance of the agent was then tested in the period from 2020/01/01 to 2020/12/31 (248 trading days), which includes the beginning of the COVID-19 pandemic, that considerably impacted the Brazilian stock market. The data utilized was collected from Yahoo Finance websiteFootnote 3. Table 1 summarizes the hyper-parameters used in the training process.
In this experiment, three metrics are used to evaluate the portfolio’s performance:
-
Final accumulative portfolio value (FAPV): This metric is calculated by dividing the final value of the portfolio by its initial value (\(V_{T}^{f}/V_{0}\)). Good portfolios aim to achieve higher FAPV.
-
Maximum drawdown (MDD) [21]:] As the name suggests, this metric calculates the maximum drop of the portfolio value. Strategies with high MDD (in absolute value) are considered risky, so the objective is to generate an agent with MDD as close to zero as possible.
-
Sharpe ratio (SR) [24]:] This ratio is created by dividing the returns of the portfolio by its variance. So, simplistically speaking, it measures the returns obtained by the risk taken and, consequently, the higher the SR, the better.
RLPortfolio calculates all these three metrics at the end of the testing period, so it is easy to evaluate different strategies in the same period of time. The experiment also compares the performance between the EIIE convolutional approach and four classical strategies:
-
Best stock: This benchmark strategy consists of investing the entire portfolio value in the stock with the highest FAPV in the testing period. Note that this strategy is not feasible in the real world since the agent needs to know in advance the performance of the stocks in the portfolio to select the best one. Nevertheless, it serves as an excellent benchmark for comparison purposes.
-
Follow the loser: This approach invests in the stock that had the worst FAPV in the training period predicting that its value will rise.
-
Uniform buy & hold: This popular strategy involves equally investing in all the stocks within the portfolio and not performing any reallocations.
-
Follow the winner:] Finally, this method invests in the stock with the best FAPV in the training set predicting that its value will continue to rise in the test set.
As it can be seen in Table 2, the agent trained in RLPortfolio achieves higher performance in all three metrics when compared to classical approaches. The fact that it is able to outperform the best performing asset in the test period shows that the agent is effectively rebalancing the portfolio considering the state of the market in order to maximize the returns. Figure 4 shows the times series of the portfolio values of all the strategies during the test period.

Portfolio value of the tested strategies during the test period.
The library is also integrated with Tensorboard [1], which allows the user to keep track of several variables during the agent’s training. Figure 5, for example, shows the evolution of the training and testing FAPV performance during the training episodes (the test set was not used to tune hyper-parameters, its performance was only logged in order to generate this visualization). The figure also shows the policy loss during training: the growing tendency in the loss indicates that the agent is effectively learning through gradient ascent.

Time series of metrics in the training (left and right) and testing sets (middle). The FAPV is plotted after every training step (left and middle), while the loss (right) is plotted after every gradient ascent.
7 Conclusions and Future Works
By implementing the mathematical formulation of the portfolio optimization task presented in Sect. 3 and the RL solution introduced in Sect. 4, RLPortfolio serves as an excellent tool for researchers and developers. It enables the easy implementation of RL agents that effectively optimize a portfolio over time. Additionally, the modularity of the library allows users to integrate algorithms, policies, and environments from other frameworks, enhancing the potential for comparative studies and accelerating advancements in the field.
Furthermore, Sect. 6 demonstrates that even one of the simplest convolutional architectures achieves excellent results in the Brazilian market, even during the COVID-19 pandemic. This not only confirms RLPortfolio’s effectiveness in training an agent but also underscores the feasibility of this approach in developing countries, markets that are typically underrepresented in research.
Finally, as RLPortfolio is open-source, its capabilities are poised to grow with contributions from new developers. Contributors can expedite and validate the introduction of future features, such as implementing agents that follow several classical strategies and other state-of-the-art policies for comparative studies, integrating with TensorFlow [1], creating interactive visualization tools, and introducing new environments with more realistic simulations.
Notes
- 1.
RLPortfolio is available at https://github.com/CaioSBC/RLPortfolio.
- 2.
The code can be found at https://github.com/CaioSBC/RLPortfolio_BRACIS.
- 3.
The website address is https://finance.yahoo.com/.
References
Abadi, M., et al.: TensorFlow: a system for large-scale machine learning. In: Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation, OSDI 2016, pp. 265–283. USENIX Association, USA (2016)
Amrouni, S.: Selimamrouni/Deep-Portfolio-Management-Reinforcement-Learning: V2.0. Zenodo (2022). https://doi.org/10.5281/zenodo.5993372
Costa, C.D.S.B., Costa, A.H.R.: POE: a general portfolio optimization environment for FinRL. In: Anais Do Brazilian Workshop on Artificial Intelligence in Finance (BWAIF), pp. 132–143. SBC (2023). https://doi.org/10.5753/bwaif.2023.231144
Felizardo, L.K., Paiva, F.C.L., Costa, A.H.R., Del-Moral-Hernandez, E.: Reinforcement Learning Applied to Trading Systems: A Survey (2022). https://doi.org/10.48550/arXiv.2212.06064
Haghpanah, M.A.: Gym-mtsim (2021)
Haghpanah, M.A.: Gym-anytrading (2023)
Hambly, B., Xu, R., Yang, H.: Recent advances in reinforcement learning in finance. Math. Financ. 33(3), 437–503 (2023). https://doi.org/10.1111/mafi.12382
Harris, C.R., et al.: Array programming with NumPy. Nature 585(7825), 357–362 (2020). https://doi.org/10.1038/s41586-020-2649-2
Henrique, B.M., Sobreiro, V.A., Kimura, H.: Literature review: machine learning techniques applied to financial market prediction. Expert Syst. Appl. 124, 226–251 (2019). https://doi.org/10.1016/j.eswa.2019.01.012
Hu, Y., Liu, K., Zhang, X., Su, L., Ngai, E.W.T., Liu, M.: Application of evolutionary computation for rule discovery in stock algorithmic trading: a literature review. Appl. Soft Comput. 36, 534–551 (2015). https://doi.org/10.1016/j.asoc.2015.07.008
Jiang, Z.: ZhengyaoJiang/PGPortfolio (2024)
Jiang, Z., Xu, D., Liang, J.: A Deep Reinforcement Learning Framework for the Financial Portfolio Management Problem (2017). https://doi.org/10.48550/arXiv.1706.10059
Khadjeh Nassirtoussi, A., Aghabozorgi, S., Ying Wah, T., Ngo, D.C.L.: Text mining for market prediction: a systematic review. Expert Syst. Appl. 41(16), 7653–7670 (2014). https://doi.org/10.1016/j.eswa.2014.06.009
Le, F.D.: Global Market Portfolio 2023 (2023). https://www.ssga.com/international/en/institutional/ic/insights/global-market-portfolio-2023
Li, J., Zhang, Y., Yang, X., Chen, L.: Online portfolio management via deep reinforcement learning with high-frequency data. Inf. Process. Manag. 60(3), 103247 (2023). https://doi.org/10.1016/j.ipm.2022.103247
Li, Y.: Deep Reinforcement Learning (2018). https://doi.org/10.48550/arXiv.1810.06339
Liang, Z., Chen, H., Zhu, J., Jiang, K., Li, Y.: Adversarial Deep Reinforcement Learning in Portfolio Management (2018). https://doi.org/10.48550/arXiv.1808.09940
Lin, Y.C., Chen, C.T., Sang, C.Y., Huang, S.H.: Multiagent-based deep reinforcement learning for risk-shifting portfolio management. Appl. Soft Comput. 123, 108894 (2022). https://doi.org/10.1016/j.asoc.2022.108894
Liu, X.Y., et al.: ElegantRL-Podracer: Scalable and Elastic Library for Cloud-Native Deep Reinforcement Learning (2022). https://doi.org/10.48550/arXiv.2112.05923
Ma, C., Zhang, J., Li, Z., Xu, S.: Multi-agent deep reinforcement learning algorithm with trend consistency regularization for portfolio management. Neural Comput. Appl. (2022). https://doi.org/10.1007/s00521-022-08011-9
Magdon-Ismail, M., Atiya, A.F., Pratap, A., Abu-Mostafa, Y.S.: On the maximum drawdown of a Brownian motion. J. Appl. Probab. 41(1), 147–161 (2004). https://doi.org/10.1239/jap/1077134674
Paszke, A., et al.: PyTorch: An Imperative Style, High-Performance Deep Learning Library (2019). https://doi.org/10.48550/arXiv.1912.01703
Raffin, A., Hill, A., Gleave, A., Kanervisto, A., Ernestus, M., Dormann, N.: Stable-baselines3: reliable reinforcement learning implementations. J. Mach. Learn. Res. 22(268), 1–8 (2021)
Sharpe, W.F.: The sharpe ratio. J. Portfolio Manag. 21(1), 49–58 (1994). https://doi.org/10.3905/jpm.1994.409501
Shi, S., Li, J., Li, G., Pan, P.: A multi-scale temporal feature aggregation convolutional neural network for portfolio management. In: Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, pp. 1613–1622. ACM (2019). https://doi.org/10.1145/3357384.3357961
Shi, S., Li, J., Li, G., Pan, P., Chen, Q., Sun, Q.: GPM: a graph convolutional network based reinforcement learning framework for portfolio management. Neurocomputing 498, 14–27 (2022). https://doi.org/10.1016/j.neucom.2022.04.105
Silver, D., et al.: Mastering the game of Go without human knowledge. Nature 550(7676), 354–359 (2017). https://doi.org/10.1038/nature24270
Soleymani, F., Paquet, E.: Financial portfolio optimization with online deep reinforcement learning and restricted stacked autoencoder–DeepBreath. Expert Syst. Appl. 156, 113456 (2020). https://doi.org/10.1016/j.eswa.2020.113456
Soleymani, F., Paquet, E.: Deep graph convolutional reinforcement learning for financial portfolio management - DeepPocket. Expert Syst. Appl. 182, 115127 (2021). https://doi.org/10.1016/j.eswa.2021.115127
Sun, Q., Wei, X., Yang, X.: GraphSAGE with deep reinforcement learning for financial portfolio optimization. Expert Syst. Appl. 238, 122027 (2024). https://doi.org/10.1016/j.eswa.2023.122027
Sutton, R.S., Barto, A.G.: Reinforcement Learning: An Introduction. A Bradford Book, Cambridge (2018)
The pandas development team: Pandas-dev/pandas: Pandas. Zenodo (2023). https://doi.org/10.5281/ZENODO.3509134
Towers, M., et al.: Gymnasium. Zenodo (2023). https://doi.org/10.5281/zenodo.8127026
Weng, J., et al.: Tianshou: A Highly Modularized Deep Reinforcement Learning Library (2022). https://doi.org/10.48550/arXiv.2107.14171
Weng, L., Sun, X., Xia, M., Liu, J., Xu, Y.: Portfolio trading system of digital currencies: a deep reinforcement learning with multidimensional attention gating mechanism. Neurocomputing 402, 171–182 (2020). https://doi.org/10.1016/j.neucom.2020.04.004
Wu, Z., Pan, S., Chen, F., Long, G., Zhang, C., Yu, P.S.: A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 32(1), 4–24 (2021). https://doi.org/10.1109/TNNLS.2020.2978386
Xu, K., Zhang, Y., Ye, D., Zhao, P., Tan, M.: Relation-aware transformer for portfolio policy learning. In: Twenty-Ninth International Joint Conference on Artificial Intelligence, vol. 5, pp. 4647–4653 (2020). https://doi.org/10.24963/ijcai.2020/641
Yang, X., Liu, W., Zhou, D., Bian, J., Liu, T.Y.: Qlib: An AI-oriented Quantitative Investment Platform (2020). https://doi.org/10.48550/arXiv.2009.11189
Acknowledgments
The authors would like to thank the Programa de Bolsas Itaú (PBI) of the Centro de Ciência de Dados (C\(^2\)D) at Escola Politécnica at USP, supported by Itaú Unibanco S.A., and the Brazilian National Council for Scientific and Technological Development (CNPq Grant N. 310085/2020-9). The authors would also like to thank student João Felipe Santiago Boccardo for proofreading and providing constructive criticism of the manuscript.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2025 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Costa, C.d.S.B., Costa, A.H.R. (2025). RLPortfolio: Reinforcement Learning for Financial Portfolio Optimization. In: Paes, A., Verri, F.A.N. (eds) Intelligent Systems. BRACIS 2024. Lecture Notes in Computer Science(), vol 15414. Springer, Cham. https://doi.org/10.1007/978-3-031-79035-5_29
Download citation
DOI: https://doi.org/10.1007/978-3-031-79035-5_29
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-79034-8
Online ISBN: 978-3-031-79035-5
eBook Packages: Computer ScienceComputer Science (R0)