
Abstract
In many data stream applications, there is a normal concept, and the objective is to identify normal and abnormal concepts by training only with normal concept instances. This scenario is known in the literature as one-class learning (OCL) for data streams. In this OCL scenario for data streams, we highlight two main gaps: (i) lack of methods based on graph neural networks (GNNs) and (ii) lack of interpretable methods. We introduce OPENCAST (One-class graPh autoENCoder for dAta STream), a new method for data streams based on OCL and GNNs. Our method learns representations while encapsulating the instances of interest through a hypersphere. OPENCAST learns low-dimensional representations to generate interpretability in the representation learning process. OPENCAST achieved state-of-the-art results for data streams in the OCL scenario, outperforming seven other methods. Furthermore, OPENCAST learns low-dimensional representations, generating interpretability in the representation learning process and results.
Access provided by University of Notre Dame Hesburgh Library. Download conference paper PDF
Similar content being viewed by others

1 Introduction
In many real-world applications, data arrives continuously as a data stream [8]. Real-world applications of data streams include the areas of health [24], fake news detection [25], and energy consumption [21]. In some of these applications, there is a known class or normal concept (positive class), and the objective is to identify between the known and unknown class by training only with instances of the known class [9]. Usually, this problem is solved through One-Class Learning (OCL)Footnote 1 [9, 25]. OCL is already commonly used in the data stream field in novelty detection, anomaly detection, and class of interest detection applications [9, 23].
Studies explore from the most classic OCL algorithms [14] to some more sophisticated ones based on clustering [18] to solve data stream tasks. The use of clustering strategies comes from the unsupervised characteristic of generating clusters to improve the challenging OCL task of training with only one class and then classifying two. We highlight two main gaps in the area of OCL for data stream. First, there is a lack of methods based on graph neural networks (GNNs). GNNs arrive with the same principle as cluster-based methods, i.e., exploring the unsupervised part of the graph (relations) through graph autoencoders [7]. GNNs have already been used in data streams [5] and OCL [30], but to the best of our knowledge, not for both areas.
The other gap is the lack of interpretable OCL methods for data streams. Interpretability is gaining more attention in data streams and other areas [12], mainly in interpretability related to the representation learning process [11]. One of the ways to provide this interpretability is to focus on the learned latent space, i.e., to produce low-dimensional representations inherently [22]. It is important to emphasize that we are not writing about methods that generate low dimensions after learning, such as PCA and t-SNE, but rather methods that generate latent representations that can be visualized at each learning epoch, i.e., enabling an interpretation of the model’s learning in real-time during training.
We propose OPENCAST (One-class graPh autoENCoder for dAta STream), a new method for data stream based on OCL and GNNs. OPENCAST is based on a GNN layer called FAConv, created for heterophilic graphs [3]. We chose this layer due to the natural concept of drift in data stream problems (concept of changing class characteristics), which can generate abnormal relations between entities of interest and non-interest class (concept of heterophile). OPENCAST is based on the state-of-the-art (SOTA) hypersphere loss function for GNNs and OCL [11]. Furthermore, to explore the concept of non-supervision to support the OCL task, OPENCAST uses a reconstruction loss function of graph autoencoders [32]. We introduce a new strategy in the field of GNNs and OCL, which is to weigh the loss functions through a parameter to deal with the concept of drift. Finally, we explicitly learn low-dimensional representations to introduce interpretability into OPENCAST naturally. In summary, our contributions are:
-
1.
We propose OPENCAST, a novel method for OCL in data streams;
-
2.
We show that learning low dimensional representations by OPENCAST generates interpretability for OCL in data streams without losing performance;
-
3.
OPENCAST obtains SOTA results for data streams against OCL methods.
2 Problem Formulation and Background
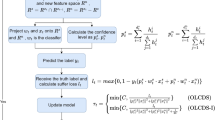
We assume that the data stream problem is divided into chunks (sliding window strategy [8]). \(\mathcal{D}\mathcal{S} = \{\mathcal{D}\mathcal{S}_0,\mathcal{D}\mathcal{S}_1,...,\mathcal{D}\mathcal{S}_m\}\) consists of the set of \(m+1\) chunks \(\mathcal{D}\mathcal{S}_i\) of the dataset, where \(\{(x_0, y_0), (x_1, y_1), ..., (x_n, y_n) \in \mathcal{D}\mathcal{S}_i\) are the \(n+1\) instances of chunk i and \(n+1\) labels of each instance, and \(\boldsymbol{x}_{j} \in \mathbb {R}^d\) is the feature vector of the j-th instance with d dimensions. The goal of OCL algorithms for data stream is to learn a function \(f: \mathcal{D}\mathcal{S}_i \rightarrow \mathcal {Y}\) in a way that \(f(\boldsymbol{x})\) predicts a label \(y \in \{+1, -1\}\). It is worth mentioning that the algorithms only train with information from a single label (\(+1\)) in each iteration, i.e., the algorithm learns the function f(.) with instances \(\boldsymbol{x_j}\), where \(y_{j} = +1\). In this work, for training, there may be instances of interest from more than one chunk before the one evaluated. Figure 1 illustrates this data flow process for OCL.

Illustration of the classification process in one-class learning. (Color figure online)
A graph is formally defined as \(\mathcal {G} = (\mathcal {V}, \boldsymbol{A})\), where each node \(v_i \in \mathcal {V}\) and \(\boldsymbol{A}\) is the adjacency matrix containing relations information between nodes. For each window (Iterations in Fig. 1), we have a \(\mathcal {G}_i\) with two sets of nodes: \(\mathcal {V}^{in}\) (set of interest with a single label, i.e., green balls in Fig. 1) and \(\mathcal {V}^{un}\) (unlabeled set, i.e., symbols without color in Fig. 1). We generate each \(\mathcal {G}_i\) through proximity between the instances. This type of graph is called k nearest neighbors graph, in which each node connects to its k nearest neighbors.
With the generated graph, we can apply GNNs to learn representations for the nodes and classify the nodes. The GNNs consider the structured representation of each node \(\boldsymbol{v}_i \in \boldsymbol{V}\) and the adjacency matrix \(\boldsymbol{A}\) as input for the representation learning process. Therefore, \(g(\boldsymbol{V}, \boldsymbol{A}; \textbf{W})\) represents a GNN with trainable weights \(\textbf{W} = \{\boldsymbol{W}^{(1)}, \cdots , \boldsymbol{W}^{(L)}\}\) in L hidden layers. Formally, for the l-th layer, the GNN propagation can be summarized as follows:
in which \(\boldsymbol{H}^{(l)}\) is the input to the l-th GNN layer, and \(\boldsymbol{H}^{l+1}\) is the output of this layer. The representations \(\boldsymbol{V}\) are the inputs for the first layer, i.e., \(\boldsymbol{V} \equiv \boldsymbol{H}^{(0)}\). In this sense, \(\boldsymbol{H}^{(L)}\) are the learned embeddings for each node.
A GNN has two main steps during the learning. First, the aggregate step tries to aggregate the information from the neighbors of each node. The second is the combining step, which tries to update the node representations by combining the aggregated information from neighbors with the current node representations [27]. After these steps, the aggregated and combined representations pass through neurons to learn the weights \(\textbf{W}\). The steps are defined by [27, 31]:

in which \(\boldsymbol{a}_{v_i}^l\) is the aggregation result of the \(v_i\) neighbors defined as \(N_{v_i}\), and \(\boldsymbol{h}_{v_j}^{l-1}\) is the feature vector of the node \(v_j\) at the \(l-1^{th}\) layer. The combination of the aggregate representation and the node representation is defined by Eq. 3 [27, 31]. For instance, the mean operator can perform both steps.
The studies of OCL and GNNs use Graph Autoencoders (GAE) to improve the OCL, given the advantages of two GAEs of learning representations in an unsupervised way by reconstructing the graph [7, 10, 11]. A GAE uses GNN layers as an encoder and an inner product of the latent representation as a decoder to learn node representations. Equation 4 describes a GAE [15]:
in which \(\sigma (.)\) is a logistic sigmoid function. GAE learns \(\boldsymbol{H}^{(L)}\) by performing the binary cross-entropy loss considering true labels (\(\boldsymbol{A}\)) and predicted labels (\(\boldsymbol{\hat{A}}\)), i.e., the GAE uses the graph relations as the first class and non-relations as another class, performing a binary classification with the learned representations.
3 Related Work
One-Class Learning for Data Streams. One-class Learning (OCL) is currently a relevant strategy explored in the data stream field [9]. Works explore OCL for novelty, anomaly, or interest class detection in the data stream [9, 26, 28]. Some works explore classic OCL algorithms or their variations to solve data stream-based tasks. In this sense, [14] proposed two algorithms: CMA and FMA. Both algorithms are based on one-class support vector machines (OCSVM) and their retraining during the stream of new data. CMA retrains OCSVM when each new instance emerges. FMA retrains the OCSVM with a heuristic formulated based on the values of new instances classified as interest or novelty. [28] proposes an Isolation Forest (IForest) variant that retrains the model when the anomaly rate increases. [20] proposes a Local Outlier Forest (LOF) variant with a new density-based sampling algorithm and distance approximation technique. Given the OCL challenge of training with one class to classify two, generally, the algorithms use unsupervised techniques to improve classification through OCL, such as clustering [9] or graph autoencoders [7, 10] techniques.
Custer-based One-Class Learning for Data Stream. Pioneering [26] or more recent [6, 18] methods explore a standard strategy to apply clustering methods of OCL and data stream scenarios. Generally, the methods apply a clustering algorithm to the training data, i.e., to the interest class data (offline stage ), and, in the online scenario, they apply this algorithm or more clustering algorithms on the new stream data to detect novelty or the interest class. Normally, what differentiates the methods is the strategy of the online stage. In this sense, [26] proposed OLINDDA, [6] proposed MINAS, and [18] proposed CDD. All are clustering algorithms for detecting novelties in data streams. OLINDDA and CDD are OCL algorithms, and MINAS is a multi-class algorithm that works in the OCL scenario. As in classical algorithms, in those based on clustering, there is a gap in interpretability. However, we can explore another relevant data-streaming strategy based on graph neural networks to obtain interpretability [13].
Graph Neural Networks for Data Stream. Graphs explicit relations between entities and these relationships can bring relevant information to the data stream field because they add information about the new data, which is better for the model [4, 17]. Still, GNNs have been explored and have state-of-the-art results in different domains [5]. Thus, studies have explored GNNs to improve the classification performance in data stream [13]. GNN works focus on proposing new adaptive GNN layers for data stream [17], specific methods for anomaly detection or novelty detection [4], and focusing on binary or multi-class classification. In the OCL, the use of GNNs focuses on unsupervised techniques such as graph autoencoders [7, 10] or end-to-end techniques with loss functions specialized for OCL [11]. Even though graphs bring relevant information about relations to data and obtain state-of-the-art results for data streams or for one-class learning, to our knowledge, there are no methods based on GNNs and OCL for data streams. In this sense, in the next section, we present an OCL method based on GNNs for the data stream.
4 OPENCAST: One-class graPh autoENCoder for dAta STream
We propose a novel method called One-class graPh autoENCoder for dAta STream (OPENCAST). Our method for data streams is based on OCL and GNNs. We explore a state-of-the-art loss function to encapsulate interest instances closer to the center within the hypersphere. OPENCAST learns a new low-dimensional latent space, where interest instances are positioned inside a hypersphere. We learn the new space through a GAE to explore the reconstruction loss. Thus, we introduce a final loss function that combines the hypersphere loss function with the reconstruction loss function, considering a weight to control the impact of each loss function in the learning since we have the concept drift of the interest class in the data stream scenario.
The first step of our method is modeling the data stream through graphs. In this modeling, heterophilic graphs can be generated, given the concept drift present in the data stream, i.e., change in the class of interest or class of non-interest [33]. Heterophilic graphs are graphs in which many nodes from different classes are connected. With the concept drift of the interest class, nodes of the interest class can connect with nodes of non-interest [16]. When using traditional GNN layers, as well as in works of one-class graph neural networks [7, 11, 30], information from all connected nodes are aggregated, i.e., nodes of non-interest can pass representation information to a node of interest, which is harmful to OCL. Thus, our first innovation is based on our method of GNN layers for heterophilic graphs. We chose the FAConv layer because it can learn weights for the edges and minimize the problem of aggregating information from nodes of different classes [3]. FAConv uses an Aggregation and Combination function presented in Eq. 5 [3].

in which, \(\boldsymbol{h}_{v_i}^0\) is the initial \(v_i\) representation, \(\epsilon \) is a factor to keep the generated representation close to the initial representation, \(d_i\) is the node degree of node i, and the attention coefficients \(\alpha _{i,j}\) are computed as presented in the Eq. 6.
The state-of-the-art for OCL through GNNs is formed by GNNs that exploit loss functions based on hyperspheres [11, 30]. These methods learn representations for the nodes while encapsulating the representations of the nodes of interest. We also explore this strategy for data stream [11, 30]. Furthermore, we combine the hypersphere loss function with the loss function of GAEs [11], which obtained superior and state-of-the-art results compared to other methods [30]. We use the hypersphere loss function \(\mathcal {L}_{1}\) defined in Eq. 7 [11] and the GAE loss function \(\mathcal {L}_{2}\) defined in Eq. 9 (binary cross entropy loss applied in the adjacency matrix). Equation 8 represents the value indicating whether the interest instance \(v_i\) is within the hypersphere with radius r and center \(\boldsymbol{c}\).

Some works combine the hypersphere and reconstruction loss functions, only adding both loss functions [11, 32]. However, considering the concept drift of the interest class can be interesting, adding weights to the losses to bias the learning. Thus, we innovate by adding impact factors to each loss function because of the concept drift during the data stream. This concept drift may require more of the hypersphere loss function that aims to encapsulate the instances of interest or more of the reconstruction of the graph that acts as a constraint for the hypersphere loss function. Therefore, our final loss function is defined by:
We present an illustration of OPENCAST in Fig. 2. We show examples of graph modeling, the FAConv as a GNN layer that allows us to focus on relations between nodes of the same class and use the hypersphere loss function to understand the model’s decision. Even though it is possible to understand the model’s decision by observing a circle or sphere and instances inside the circle/sphere (class of interest) and outside the circle/sphere (class of non-interest), it is challenging to interpret the learning that generated this decision, since we cannot visualize the representations generated during learning if the dimension is greater than 3. On the other hand, with representations in two or three dimensions, we can observe and interpret the representations generated during learning. In this sense, we bias OPENCAST learning so that our method learns representations in size two to provide interpretability for representation learning in the scenario of OCL and GNNs for data streams.

Illustration of the OPENCAST method.
5 Experimental Evaluation
This section presents the experimental evaluation of this article. We present the used datasets, experimental settings, results, and discussion. Our goal is to demonstrate that our OPENCAST proposal outperforms other state-of-the-art methods for data streams. Another goal is to demonstrate that our method learns low-dimensional representations, providing interpretability for the data stream scenario. The experimental evaluation codes are publicly availableFootnote 2.
5.1 Datasets
We selected four publicly available benchmark datasets from [29], commonly used in the data stream literature, for our OCL scenario, each large enough to be processed as a stream and with two classes: the interest and outlier classes. We choose two synthetic and two real datasets. AgrawalFootnote 3 and Tweet500Footnote 4 are synthetic, and Bank MarketingFootnote 5 and ElectricityFootnote 6 are the real datasets. Agrawal is a stream generator that uses ten functions to generate binary class labels from nine features [1]. Tweet500 is generated by MOA [2] and simulates sentiment analysis on tweets (positive or negative feelings). Bank Marketing is related to direct marketing campaigns to assess if the product (bank term deposit) would be (’yes’) or not (’no’) subscribed [19]. Electricity was collected from the Australian New South Wales Electricity Market. The class label identifies the price change (UP or DOWN) in New South Wales relative to a moving average of the last 24 h. Table 1 summarises the datasets. For categorical attributes, we use a one-hot-encoding strategy to transform the attributes into numeric ones.
5.2 Experimental Settings
One part of the experimental settings defines the data ordering, partitions, and distribution [29]. We follow the data stream protocol from [8] and select the sliding window strategy. Our window is 2500 in length. It is essential to point out that we use only the interest instances of each window before the current window to train the algorithms and evaluate them on all instances of the current window. We kept the most current instances of interest from the previous window until there were 2500 instances of interest for training the algorithm (see Fig. 1). Finally, we use the \(f_1\)-macro to compare all models, as the \(f_1\)-micro and Accuracy are biased by test set imbalance, which is natural in OCL.
We compare the OPENCAST with CMA and FMA from [14], OCSVM, IForest, and LOF to cover the classical and adaptation of OCL algorithms for data streamsFootnote 7. Furthermore, considering the one-class cluster algorithms of the data stream from the literature, we compare our method with CDD [18]. We also adapted the LOF algorithm to compare OPENCAST with another method with graph topology information since LOF has a parameter to receive neighbor information. We use the following parameters for the methods:
-
OCSVM, CMA, and FMA: kernel = {rbf, poly, sigmoid, linear}, \(\nu = \{0.05 * b, 0.005 * b\}, b \in [1..19]\), and \(\gamma = \{\) scale, auto \(\}\);
-
FMA: \(H_t = \{50, 100, 1000, 2000\}\), \(\alpha = \{0.1 * b\}, b \in [1..9]\);
-
IForest: n\(^\circ \) of estimators = \(\{1,2,5,10,50,100,200,500\}\), maximum samples and maximum features = \(\{0.1 * b\}, b \in [1..10]\);
-
LOF: n\(^\circ \) of neighbors = \(\{1,2,5,10,50,100\}\);
-
GraphLOF: n\(^\circ \) of neighbors = \(\{1,2,3,4,5,6,7,8,9,10,15,20\}\) and k for graph modeling = n\(^\circ \) of neighbors + 1;
-
CDD: n\(^\circ \) of clusters = \(\{2, 5, 10, 50, 100\}\) and algorithms k-means and GMM;
-
OPENCAST: k for graph modeling = \(\{1,2,3,4,5\}\), n\(^\circ \) of layers = \(\{1,2\}\), \(r = 0.3\), c \(= [0,0]\), epochs = \(\{2000, 3000\}\), \(\beta \) and \(\epsilon = \{0.1 * b\}, b \in [1..9]\), learning rate = 0.001.
5.3 Results and Discussion
Table 2 shows our results. Each table row shows the results of a method on the four datasets. In bold are the highest \(f_1\) macro averages. Underlined are the second-highest macro \(f_1\) averages. In parentheses are the standard deviations for each result. In the four datasets, OPENCAST obtained the highest macro \(f_1\) averages. In three of the datasets, OCSVM obtained the second-best result. In the Electricity dataset, IForest obtained the second-best result. For real datasets, OPENCAST improved to the second or third decimal place. On the other hand, in the synthetic datasets, OPENCAST improved 23 % and 31 % in the average \(f_1\) macro. The worst results were obtained by GraphLOF, followed by LOF and CDD. CMA, FMA, and IForest were competitive with OCSVM.
The worst result of OPENCAST was in the dataset bank. This is the most unbalanced dataset (see Table 1). Therefore, the lack of interest and many examples of non-interest may have been the factor for our low performance. It is worth mentioning that the other methods also suffered from this imbalance. Given the low performance of all methods in this dataset, we believe that the initial representations also harm the learning, i.e., it is necessary to pre-process to normalize, standardize, and even perform feature selection to improve the OCL performance in these data stream datasets. We obtained satisfactory SOTA results for data streams through OCL in the other datasets. An interesting point is the good results on different types of datasets (real and synthetic), with varying sizes of features (500, 40, and 6) and number of instances (100k and 45k).
Figures 3, 4, 5, and 6 present the \(f_1\) macro in each iteration for each dataset. In Figs. 5 and 6, OPENCAST always obtains better performance stably. We observed other stable methods but with worse performance or unstable and with worse performance. In Fig. 3, OPENCAST wins in some iterations and loses in others. For this dataset, most methods were stable except CDD. In Fig. 4, we observe the highest level of instability in the methods with the best averages (OPENCAST and IForest). OPENCAST wins in some iterations and loses in others, as in the dataset bank. OPENCAST is a method based on neural networks and needs a learning rate. One of the possibilities for improving the method’s performance and generating stability is exploring a lower learning rate and more training epochs.

\(f_1\) macro of each iteration of each method in dataset Bank.

\(f_1\) macro of each iteration of each method in dataset Electricity.

\(f_1\) macro of each iteration of each method in dataset Agrawal.

\(f_1\) macro of each iteration of each method in dataset Twitter.
We present the representations generated by the OPENCAST learning to demonstrate the interpretability of our method. In this sense, Fig. 7 presents the OPENCAST representations in the experimental evaluation of the Twitter dataset. Our interpretability focuses on the learning process. Thus, we present OPENCAST’s learning process. In the real world, we can show the video of the learning process since we can plot all learning epochs without processing the representation (our learned representations have two dimensions). The epochs are 700, 725, 750, 775, 800, 900. 1000, and 2000. Yellow points represent the interest class, and blue points represent the non-interest class.

Graph plot considering the two-dimensional last layer learned representations of OPENCAST in the Twitter dataset at one iteration. The colors indicate the interest (yellow) and the non-interest (blue) classes. (Color figure online)
We observe the learning process proposal through OPENCAST interpretability, as shown in Fig. 7. In the initial steps, we observe OPENCAST focusing on graph reconstruction (loss \(\mathcal {L}_2\)), the first OPENCAST goal. In the next steps, we observe learning through the two losses since the interest instances get closer to the sphere while non-interest instances are outside the sphere. In the final steps, we observed that the one-class loss \(\mathcal {L}_1\) encouraged the instances to continue coming to the sphere center, as proposed to improve the performance.
5.4 Ablation Study
We propose an ablation study to verify the impact of OPENCAST learning strategies compared to other strategies in the OCL literature for graphs [11, 32]. We compared, in the best OPENCAST performance scenario, the use of a Graph Convolutional Network (GCN) instead of FAConv and the addition of \(\mathcal {L}_1\) and \(\mathcal {L}_2\) instead of using our parameter \(\beta \). Table 3 presents the average macro \(f_1\) in the four datasets for each modification on OPENCAST, i.e., the OPENCAST with: (I) GCN and adding \(\mathcal {L}_1\) and \(\mathcal { L}_2\); (ii) GCN and our final loss (with \(\beta \)); (iii) FAConv and adding \(\mathcal {L}_1\) and \(\mathcal {L}_2\); and (iv) FAConv and our final loss (with \(\beta \)).
FAConv improves learning in relation to GCNConv as motivated in the OPENCAST section due to concept drift. Using the \(\beta \) parameter in real datasets improves the classification performance. On the other hand, in the synthetic datasets, the performance was equal, considering both the sum of the loss functions and using the \(\beta \) parameter to weigh the losses. We analyzed the best OPENCAST parameters in each dataset to find meaning in this ablation study. In the real datasets, the best \(\beta \) values were 0.6 (Electricity) and 0.4 (Electricity), i.e., there was greater importance for each loss function during learning. For the synthetic datasets, the \(\beta \) value that resulted in the best learning was 0.5, i.e., the same importance for the two loss functions as in the sum strategy. This shows us why the \(\beta \) parameter has less impact on synthetic datasets. Still, it is a good strategy since it wins in real datasets and does not lose in the synthetics.
We complement our ablation study by presenting the interpretability results for each learning strategy described in the paragraph above. Figure 8 presents the graph and its connections considering the final representation learned by each model in the Twitter dataset as coordinates. In addition to higher \(f_1\), FAConv generated better representations for the hypersphere-based decision strategy. OPENCAST with FAConv learned representations for instances of interest closer to the center and within the hypersphere than GCN.

Graph plot considering the two-dimensional last layer learned representations of OPENCAST in the Ablation Study considering the Twitter dataset. The colors indicate the interest (yellow) and the non-interest (blue) classes. (Color figure online)
6 Conclusions and Future Work
In this work, we propose OPENCAST, a GNN based on OCL for stream data. OPENCAST is based on FAConv due to the concept of drift since this layer gives importance to edges of nodes from the same classes and ignores relations between nodes from other classes. Our OPENCAST is also based on the SOTA hypersphere loss function for OCL and the reconstruction function of GAEs. We introduce a new way of combining these loss functions through a \(\beta \) parameter that gives weight to each loss function. OPENCAST learning allows for exploring low-dimensional representations during classification, providing interpretability and visualization for the OCL task on a graph-structured data stream. OPENCAST outperformed other methods, obtaining SOTA results and generating representations visually suitable for OCL in each epoch, which brought interpretability to the data stream scenario through OCL.
The main limitation of OPENCAST is that it does not take advantage of the neuron’s weights from the previous iteration in the current iteration. This limitation can be observed in the instability shown in Fig. 4. Maintaining old instances mitigates this, but it is not enough if there is a dependency on the previous iteration. Therefore, in future work, we intend to explore a version of OPENCAST that uses the neural network weights in the previous iteration to initialize the neural network weights in the current iteration. Furthermore, we intend to explore our method in heterophilic scenarios other than data streams.
Notes
- 1.
OCL is also called one-class classification in the literature, but this work chose to use the term OCL.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
Other methods based on OCSVM, IForest and LOF (methods presented in the Related Work section) do not share the source code or the link to the source code is broken or the code is not in python which was the language used in this work.
References
Agrawal, R., Imielinski, T., Swami, A.: Database mining: a performance perspective. IEEE Trans. Knowl. Data Eng. 5(6), 914–925 (1993)
Bifet, A., et al.: MOA: massive online analysis, a framework for stream classification and clustering. In: Proceedings of the First Workshop on Applications of Pattern Analysis. PMLR (2010)
Bo, D., Wang, X., Shi, C., Shen, H.: Beyond low-frequency information in graph convolutional networks. In: Proceedings of the Conference of AAAI (2021)
Cai, L., et al.: Structural temporal graph neural networks for anomaly detection in dynamic graphs. In: Proceedings of the International Conference on Information and Knowledge Management (2021)
Corso, G., Stark, H., Jegelka, S., Jaakkola, T., Barzilay, R.: Graph neural networks. Nat. Rev. Methods Primers 4(1), 17 (2024)
de Faria, E.R., Ponce de Leon Ferreira Carvalho, A.C., Gama, J.: Minas: multiclass learning algorithm for novelty detection in data streams. Data mining and knowledge discovery 30, 640–680 (2016)
Feng, Y., Chen, J., Liu, Z., Lv, H., Wang, J.: Full graph autoencoder for one-class group anomaly detection of IIOT system. Internet Things J. 9(21) (2022)
Gama, J., Sebastiao, R., Rodrigues, P.P.: On evaluating stream learning algorithms. Mach. Learn. 90, 317–346 (2013)
Gaudreault, J.G., Branco, P.: A systematic literature review of novelty detection in data streams: challenges and opportunities. ACM Comput. Surv. (2024)
Gôlo, M.P.S., De Moraes, M.I., Goularte, R., Marcacini, R.M.: On the use of early fusion operators on heterogeneous graph neural networks for one-class learning. In: Proceedings of the Brazilian Symposium on Multimedia and the Web, pp. 128–136 (2023)
Gôlo, M.P.S., Junior, J.G.B.M., Silva, D.F., Marcacini, R.M.: Olga: one-class graph autoencoder. arXiv preprint arXiv:2406.09131 (2024)
Haug, J., Broelemann, K., Kasneci, G.: Dynamic model tree for interpretable data stream learning. In: International Conference on Data Engineering. IEEE (2022)
Jin, G., et al.: Spatio-temporal graph neural networks for predictive learning in urban computing: a survey. IEEE Trans. Knowl. Data Eng. (2023)
Jodelka, O., Anagnostopoulos, C., Kolomvatsos, K.: Adaptive novelty detection over contextual data streams at the edge using one-class classification. In: International Conference on Information and Communication Systems. IEEE (2021)
Kipf, T.N., Welling, M.: Variational graph auto-encoders. Stat 1050, 21 (2016)
Luan, S., et al.: Revisiting heterophily for graph neural networks. Adv. Neural. Inf. Process. Syst. 35, 1362–1375 (2022)
Ma, Y., Guo, Z., Ren, Z., Tang, J., Yin, D.: Streaming graph neural networks. In: Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 719–728 (2020)
Mendelson, S., Lerner, B.: Online cluster drift detection for novelty detection in data streams. In: International Conference on Machine Learning and Applications. IEEE (2020)
Moro, S., Rita, P., Cortez, P.: Bank Marketing. UCI Repository (2012)
Na, G.S., Kim, D., Yu, H.: Dilof: effective and memory efficient local outlier detection in data streams. In: Proceedings of Knowledge Discovery and Data Mining (2018)
Onuki, E.K.T., Malucelli, A., Barddal, J.P.: A tool for measuring energy consumption in data stream mining. In: BR Conference on Intelligent Systems. Springer (2023)
Peng, X., Li, Y., Tsang, I.W., Zhu, H., Lv, J., Zhou, J.T.: Xai beyond classification: interpretable neural clustering. J. Mach. Learn. Res. (2022)
Pitonakova, L., Bullock, S.: The robustness-fidelity trade-off in grow when required neural networks performing continuous novelty detection. Neural Networks (2020)
Puerto-Santana, C., et al.: Asymmetric HMMs for online ball-bearing health assessments. Internet Things J. 9(20), 20160–20177 (2022)
de Souza, M.C., Nogueira, B.M., Rossi, R.G., Marcacini, R.M., Rezende, S.O.: A heterogeneous network-based positive and unlabeled learning approach to detect fake news. In: Brazilian Conference on Intelligent Systems. Springer (2021)
Spinosa, E.J., de Leon F. de Carvalho, A.P., Gama, J.: Olindda: a cluster-based approach for detecting novelty and concept drift in data streams. In: Proceedings of the 2007 ACM Symposium on Applied Computing, pp. 448–452 (2007)
Tang, J., Liao, R.: Graph neural networks for node classification. In: Graph Neural Networks: Foundations, Frontiers, and Applications, pp. 41–61 (2022)
Togbe, M.U., et al.: Anomaly detection for data streams based on isolation forest using Scikit-Multiflow. In: Gervasi, O., et al. (eds.) ICCSA 2020. LNCS, vol. 12252, pp. 15–30. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58811-3_2
Veloso, B., Gama, J., Malheiro, B., Vinagre, J.: Hyperparameter self-tuning for data streams. Inf. Fusion 76, 75–86 (2021)
Wang, X., Jin, B., Du, Y., Cui, P., Tan, Y., Yang, Y.: One-class graph neural networks for anomaly detection in attributed networks. Neural Comput. Appl. 33(18), 12073–12085 (2021). https://doi.org/10.1007/s00521-021-05924-9
Xu, K., Hu, W., Leskovec, J., Jegelka, S.: How powerful are graph neural networks? In: Proceedings of the International Conference on Learning Representations. Open Review (2019)
Zhang, F., Fan, H., Wang, R., Li, Z., Liang, T.: Deep dual support vector data description for anomaly detection on attributed networks. Int. J. Intell. Syst. 37(2), 1509–1528 (2022)
Zheng, Y., Yi, L., Wei, Z.: A survey of dynamic graph neural networks. arXiv preprint arXiv:2404.18211 (2024)
Acknowledgments
This work was supported by Coordenação de Aperfeiçoamento de Pessoal de Nível Superior (CAPES) grant number 88887.671481/2022-00. Also, this work was supported by LatAm Google Ph.D. Fellowship. Finally, we would like to thank Google Tutor Mara Finkelstein for reviewing the work.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2025 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Silva Gôlo, M.P., Gama, J., Marcondes Marcacini, R. (2025). One-Class Learning for Data Stream Through Graph Neural Networks. In: Paes, A., Verri, F.A.N. (eds) Intelligent Systems. BRACIS 2024. Lecture Notes in Computer Science(), vol 15415. Springer, Cham. https://doi.org/10.1007/978-3-031-79038-6_5
Download citation
DOI: https://doi.org/10.1007/978-3-031-79038-6_5
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-79037-9
Online ISBN: 978-3-031-79038-6
eBook Packages: Computer ScienceComputer Science (R0)